一、File对象
1.作用
操作系统的任何一个单独的文件或者文件目录,都可以使用File对象来表示,使用File对象可以获取文件的一些基本信息,也可以实现删除文件、目录创建等操作,但是,如果要面对文件中的具体内容进行操作,则无法通过File对象来完成,需要使用IO流
2、File对象的构建
File file = new File(String path);
path:文件所在的路径,用来指定当前要进行操作的文件或目录所在的位置
路径的写法分类
绝对路径:从盘符开始到目的地(可以是单个文件也可以是目录)的完整 路径
相对路径:以当前目录作为起始目录,不需要写出从盘符开始的完整路径
3、常用API
二、IO流
(一)概念
I:Input,输入,使用输入流对文件进行读操作
O:Output,输出,使用输出流对文件进行写操作
Java中的IO流分为字节流和字符流
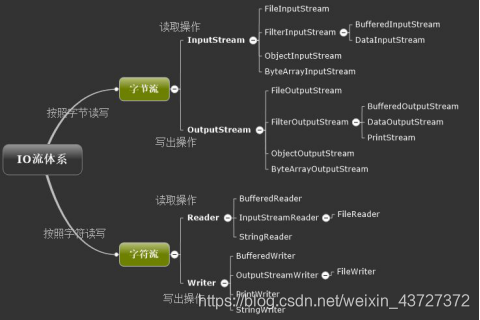
(二)字节流
以字节为单位对文件进行操作的流
字节流的顶级父类:InputStream(输入流,读)、OutputStream(输出流,写)InputStream(输入流,读)、OutputStream(输出流,写)中分别提供了以字节为单位进行读写的常用方法。
1、FileOutputStream、FileInputStream
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* FileOutputStream
*/
public class Demo01 {
public static void main(String[] args) {
try( FileOutputStream fos = new FileOutputStream("src" + File.separator + "2.txt", true)) {
//构造参数可以是File对象或路径字符串
//注意:输出流会自动创建不存在的文件
// FileOutputStream fos = new FileOutputStream("src" + File.separator + "2.txt");
//如果append参数为true,则将新的内容追加到原来的文件中
//如果为false,就是覆盖模式,默认如果不指定append参数,就是覆盖模式
//void write(byte[] d)
//将给定的字节数组中的所有字节全部写出
fos.write("上元IT".getBytes());
fos.write("传智播客".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
// finally {
// //关闭资源
// if (fos != null) {
// try {
// fos.close();
// } catch (IOException e) {
// }
// }
// }
}
}import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.lang.reflect.Array;
import java.util.Arrays;
/**
* FileInputStream
*/
public class Demo02 {
public static void main(String[] args) {
System.out.println("a".getBytes().length);
System.out.println("1".getBytes().length);
System.out.println("中".getBytes().length);
//在JDK1.7后可以使用try……with……resource语法
//在try的括号中构建最终原本需要在finally中关闭的对象,
//在try中声明的对象,最后会自动调用其中的close()方法
try( FileInputStream fis = new FileInputStream("src" + File.separator + "2.txt");) {
//读取文件中的内容
//int read(byte[] b)
//尝试最多读取给定数组的length个字节并存入该数组,返回值为实际读取到的字节量
//该数组用来存放每次读取时读取的字节信息,如果调用read方法,则会一次性读取
//数组长度个字节,将读出来的字节放入这个数组中
//此处如果读取的有中文内容,可能只会读取到中文的某几个字节,导致乱码
byte[] bytes=new byte[6];
//返回的是实际读取的字节量,这个值可能小于数组的最大长度
int read=fis.read(bytes);
//读取到的字节信息
//System.out.println(Arrays.toString(bytes));
//将字节信息转换为字符串
System.out.println(new String(bytes));
} catch (IOException e) {
e.printStackTrace();
}
}
}
以字节为单位,对文件进行读写操作
2、BufferedInputStream、BufferedOuputStream
import java.io.*;
/**
* BufferedInputStream、BufferedOutputStream
* 复制
*/
public class Demo01 {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("src" + File.separator + "1.txt");
//缓冲流是一种包装流,不能单独存在,是对其它流做的一个包装
BufferedInputStream bis = new BufferedInputStream(fis);
FileOutputStream fos = new FileOutputStream("src" + File.separator + "1Copy.txt",true);
BufferedOutputStream bos = new BufferedOutputStream(fos);
) {
// //此处使用缓冲流来完成读写操作
byte[] bytes = new byte[5 * 1024];
int len = -1;
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
}
// bos.write("中国".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}
}
缓冲字节流
缓冲流的原理
缓冲输出流
在向硬件设备做写出操作时,增大写出次数无疑会降低写出的效率,为此,可以使用缓冲输出流来一次性批量写出若干数据减少写出次数来提高写出效率。
BufferedOutputStream内部维护一个缓冲区,每当向该流写数据时,都会先将数据存入缓冲流,当缓冲区满了,缓冲流会将数据一次性全部写出。
缓冲输入流
在读取数据时若以字节为单位读取数据,会导致读取次数过于频繁从而降低读取效率,为此可以通过提高一次读取的字节数量减少读写次数来提高读取的效率。
内部维护者一个缓冲区,使用该流在读取一个字节时,会尽量多的一次性读取若干字节并存入缓冲区,然后逐一将字节返回,直到将缓冲区的数据全部读取完毕,会再次读取若干字节从而反复,这样就减少了读取的次数,从而提高了读取效率。
3、ObjectOutputStream、ObjectInputStream
import com.sy.file.io.entity.Emp;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.List;
/**
* 序列化操作:ObjectOutputStream
*/
public class Demo01 {
public static void main(String[] args) {
//对于这个emps对象而言,保存在此次运行的虚拟机实例的内存中
//内存中的对象具有瞬时性,随着程序的退出,对象就没有了
//但是有时候希望将内存中的对象提供给另外一台计算机使用或者使其在网络中传递
// List<Emp> emps=new ArrayList<>();
// emps.add(new Emp());
// emps.add(new Emp());
// emps.add(new Emp());
Emp emp = new Emp("Tom", 25);
try (FileOutputStream fos = new FileOutputStream("src" + File.separator + "emp.obj");
ObjectOutputStream oos = new ObjectOutputStream(fos);) {
//通过writeObject方法实现序列化操作
oos.writeObject(emp);
System.out.println("序列化完毕!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
import com.sy.file.io.entity.Emp;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
/**
* ObjectInputStream:反序列化操作
*/
public class Demo02 {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("src" + File.separator + "emp.obj");
ObjectInputStream ois = new ObjectInputStream(fis);) {
//通过readObject()方法进行反序列化操作
Emp emp = (Emp) ois.readObject();
System.out.println(emp);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
序列化流、对象流
序列化、反序列化的概念
序列化:将对象转换为字节序列
反序列化:字节序列转换为对象
因为有时候需要在不同的计算机之间共享对象或传输对象,而计算机中内存里的对象无法直接共享,所以先通过序列化将对象转化为字节序列,将字节序列传输后再另外一台计算机中再通过反序列化转换为对象。
Serializable接口
Serializable接口是一个标记接口,其中没有任何需要被实现的方法,只是用来标记当前的类是一个可以被序列化和反序列的类型,所有需要进行序列化和反序列化的类型必须实现Serializable接口
序列化编号serialVersionUID
首先创建一个Emp对象,包含name和age两个属性,此时对Emp对象进行序列化操作得到一个字节序列,如果此时直接对字节序列进行反序列化则没有任何的问题!
如果在反序列化之前对Emp对象添加salary属性,此时再进行反序列化,会出现InvalidClassException。原因是因为序列化和反序列化的时候版本号不相同了。
对于每一个已经实现Serializable接口的类而言,如果不显式声明,这些类都有一个隐含的属性serialVersionUID,该属性在默认情况下是通过类的方方面面以及当前所在的操作系统平台计算得到的,所以一旦类的属性发生变化以后,就会改变原来的serialVersionUID,而对于序列化和反序列化时如果serialVersionUID不一样,则反序列化的时候会出现错误。
如果要修改属性又想保证其serialVersionUID一样,则可以在类中手动声明一个serialVersionUID属性。手动声明后的serialVersionUID就固定下来了,不会因为操作系统或属性的变化而重新计算。
可以使用序列化版本号来解决序列化前后类内容不相同导致的兼容性问题!
transient 关键字
private transient String name;
transient关键字用来修饰成员属性,被该关键字修饰的属性在序列化过程中会被自动忽略,如果某些属性不需要被转换为字节序列,可以使用该关键字修饰这个属性,从而达到对序列化对象进行“瘦身”的效果。
static修饰的关键字无论是否被transient 修饰,都不会被序列化
(三)字符流
字符流是以字符为基本单元进行操作的
字符流的顶级父类是Reader和Writer
1、OutputStreamWriter、InputStreamReader
import java.io.*;
/**
* OutputStreamWriter
*/
public class Demo01 {
public static void main(String[] args) {
try (
FileOutputStream fos = new FileOutputStream("D:" + File.separator + "1.txt", true);
//如果要解决中文乱码问题,需要保证写出时的字符集编码和读取的时的字符集编码保持一致
//输出文件的编码格式由第二个参数决定,
//常用的编码:gbk,gb2312,big5,iso8859-1(西欧), UTF-8(万国码)
//默认不指定则为当前文件的默认字符集编码
OutputStreamWriter osw = new OutputStreamWriter(fos, "utf-8");
) {
//通过字符流的write方法写出字符信息
// void write(int c)写出一个字符,写出给定int值低16位表示的字符,参数其实就是ascii码
osw.write(97);
osw.write(65);
// void write(char[] chs)将给定字符数组中所有字符写出
osw.write(new char[]{'J', 'a', 'v', 'a' });
// void write(String str)将给定的字符串写出
osw.write("黑驴");
osw.write("达外");
// void write(String str, int off, int len)将给定的字符串中从offset处开始连续len个字符写出
osw.write("abc", 0, 2);
// void write(char[] chs,int offset,int len)给定的字符数组从offset处开始连续len个字符写出
osw.write(new char[]{'P', 'H', 'P' }, 0, 2);
} catch (IOException e) {
e.printStackTrace();
}
}
}
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
/**
* InputStreamReader
*/
public class Demo01 {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("D:" + File.separator + "1.txt");
//对于中文而言,读取和写入时要保证字符集编码一致才不会出现乱码
InputStreamReader isr = new InputStreamReader(fis, "utf-8");
) {
//一个个字节读取
// int read() 读取一个字符,返回int值的低16位有效,如果返回-1,说明到了文件末尾,返回ascii的值
// int c = -1;
// while ((c = isr.read()) != -1) {
// System.out.print((char) c);
// }
//以字符数组为单位读取
//int read(char[] chs),从该流中读取一个字符数组的连续length个字符并存入该数组,返回值为实际读取到的字符量,如果返回-1,说明到了文件末尾
char[] chars = new char[3];
int len = -1;
while ((len = isr.read(chars)) != -1) {
System.out.print(new String(chars, 0, len));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2、PrintWriter、BufferedReader
/**
* PrintWriter
*/
public class Demo01 {
public static void main(String[] args) {
//根据构造参数的不同
//可以传递File对象,String类型的路径
//也可以传递OutputStream--可以去改变追加还是覆盖模式
//也可以传递Writer--可以去改变字符集编码
try (PrintWriter pw = new PrintWriter("src" + File.separator + "3.txt");) {
//PrintWriter中提供了丰富的print和println方法,可以完成输出操作
pw.print("哈哈");
pw.print("呵呵呵");
pw.println("嘻嘻嘻");
pw.println("嚯嚯嚯");
} catch (IOException e) {
e.printStackTrace();
}
}
}
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.PrintWriter;
public class Demo02 {
public static void main(String[] args) {
PrintWriter pw = null;
FileOutputStream fos = null;
try {
fos = new FileOutputStream("src" + File.separator + "3.txt");
//第二个参数如果为true,表示自动将print的内容写出到文件中,不需要再调用flush方法了
pw = new PrintWriter(fos, true);
pw.print("哈哈");
pw.print("呵呵呵");
pw.println("嘻嘻嘻");
pw.println("嚯嚯嚯");
//对于PrintWriter对象而言,缓冲区中的内容写出有两种情况
//(1)缓冲区满了以后自动写出
//(2)缓冲区没有达到上限时,需要手动写出
//pw.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (pw != null) {
//该方法中会自动调用flush方法,所以如果能够正常关闭,不需要调用flush方法或设置autoFlush为true
pw.close();
}
if(fos!=null){
try {
fos.close();
} catch (IOException e) {
}
}
}
}
}
import java.io.*;
/**
* BufferedReader
*/
public class Demo01 {
public static void main(String[] args) {
try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("src" + File.separator + "3.txt")));) {
//br.readLine()方法读取文件中一行的记录,如果文件读完了,则该方法返回null
//注意:该方法读取的每一行记录中不包括该行的换行符
String line = null;
StringBuilder sb=new StringBuilder();
while ((line = br.readLine()) != null) {
sb.append(line);
sb.append("\n");
}
System.out.println(sb.toString());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}对文件进行复制的三种操作
1.使用单个字节进行复制
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 使用FileInputStream和FileOutputStream完成文件的复制
* 以字节为单位
*/
public class Demo01 {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("src" + File.separator + "1.png");
FileOutputStream fos = new FileOutputStream("src" + File.separator + "1Copy.png");
) {
// int read()
// 读取一个字节,以int形式返回,该int值的低8为有效,若为-1,则EOF (End Of File)
//b表示读取到的下一个字节,如果为-1说明到达文件的末尾
int b = -1;
while ((b = fis.read()) != -1) {
// void write(int d)
// 写出一个字节,写出的是给定int的低八位
fos.write(b);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}使用字节数组进行复制
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 使用FileInputStream和FileOutputStream完成文件的复制
* 以字节数组为单位
*/
public class Demo02 {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("src" + File.separator + "1.png");
FileOutputStream fos = new FileOutputStream("src" + File.separator + "2Copy.png");
) {
// int read(byte[] b)
// 尝试最多读取给定数组的length个字节并存入该数组,返回值为实际读取到的字节量
// int read(byte b[], int off, int len)
// 尝试读取给定数组的从off开始的连续len个字节并存入该数组,返回值为实际读取到的字节量
byte[] bytes = new byte[5 * 1024];
//len表示实际读取到的字节量
int len = -1;
while ((len = fis.read(bytes)) != -1) {
// void write(byte[] d)
// 将给定的字节数组中的所有字节全部写出
// void write(byte b[], int off, int len)
// 将给定字节数组中从off开始的连续len个字节写出
//写出的时候应该写出实际读取到的个数的字节
fos.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
3.使用字符流复制文件
import java.io.*;
/**
* 使用字符流进行复制操作
*/
public class Demo03 {
public static void main(String[] args) {
try (
FileInputStream fis = new FileInputStream("D:" + File.separator + "1.csv");
InputStreamReader isr = new InputStreamReader(fis);
FileOutputStream fos = new FileOutputStream("D:" + File.separator + "1Copy.csv");
OutputStreamWriter osw = new OutputStreamWriter(fos);
) {
char[] chars = new char[3];
int len = -1;
while ((len = isr.read(chars)) != -1) {
osw.write(chars, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
字节流和字符流的区别
字节流以字节为单位进行操作,字符流以字符为单位进行操作
字节流默认不带缓冲区(除非使用缓冲流),字符流默认自带缓冲区
字节流可以操作任何类型的文件,但是字符流只能操作文本文件(word文档不属于纯文本文档,csv属于纯文本文档)
序列化和反序列化的区别
序列化:将对象转换为字节序列
反序列化:字节序列转换为对象
因为有时候需要在不同的计算机之间共享对象或传输对象,而计算机中内存里的对象无法直接共享,所以先通过序列化将对象转化为字节序列,将字节序列传输后再另外一台计算机中再通过反序列化转换为对象。