目录
- -flatten_hierarchy (影响综合结果的层次)
- -gated_clock_conversion
- -fsm_extraction (影响状态机编码方式)
- -fsm_encoding
- Keep_equivalent_registers (含义)
- -resource_sharing (影响算术运算)
- -control_set_opt_threshold (影响触发器控制集)
- -no_lc (影响LUT资源)
- -shreg_min_size (影响移位寄存器)
- -bufg
- -fanout_limit
- -directive
- -max_bram
- -max_dsp
- -cascase_dsp
Synthesis setting
Vivado开发套件的综合设置中提供了一系列的综合选项,这些综合选项对综合的结果有着潜在的影响,运行综合时可利用这些 综合选项 来对综合的设计进行综合。常用的选项都可以在下图菜单中设置。

-
-flatten_hierarchy (影响综合结果的层次)
该选项决定了Vivado综合工具将如何控制层次结构
| full | 指示工具完全展平层次结构,只留下顶层。只保留顶层层次,执行边界优化 |
| none | 指示综合工具从不展平层次结构。 综合后的输出具有与原始RTL相同的层次结构。不执行边界优化 |
| rebuilt: | rebuilt允许综合工具展平层次结构,执行综合,然后根据原始RTL重建层次结构。 此值允许跨边界优化的QoR优势,最终层次结构与RTL类似,便于分析。即综合时将原始设计打平,执行边界优化,综合后将网表文件按照原始层次显示,故与原始层次相似。 |
创建3个综合运行(Design Runs):synth_1、synth_2、synth_3,将三者的flatten_hierarchy分别设置为full、none、rebuilt。
创建方法见综合篇():Global和OCC综合模式。
综合结果分别如下所示:


三种综合结果的资源利用率报告:



对比可发现,当-flatten_hierarchy为none时消耗的寄存器最多,建议其设定为默认值rebuilt。
flatten_hierarchy是一个全局的综合指导原则,即它是对整个工程所有模块起作用而不是仅仅某一个模块。如果需要对某一个模块进行层次化管理,则需要用到综合属性:keep_hierarchy了。(详见综合属性章节)
(*keep_hierarchy = "yes"*)
module module_name
(
/*
接口信号
*/
);
...
endmodule-
-gated_clock_conversion
打开和关闭综合工具转换时钟逻辑的能力。使用门控时钟转换还需要使用RTL属性才能工作。 后面将介绍RTL属性GATED_CLOCK。

-
-fsm_extraction (影响状态机编码方式)
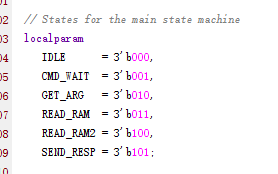
该选项主要对状态机的编码方式有影响,默认值为auto,此时vivado会自动推断最佳的编码方式。

在wavegen工程中,fsm_extraction选项选择auto如此综合后的设计中,在下方Log窗口中CRTL+F搜索encoding,结果如下:

可看出该状态机编码方式为sequential。而previous Encoding是什么呢,这是因为cmd_pase模块本身已经设定了编码方式了。
【注意】
-fsm_extraction设定为one-hot时,综合后的结果编码方式就是独热码。也就是说,-fsm_extraction设定的编码方式优先级高于HDL代码中定义的编码方式。
与-fsm_extraction综合选项功能一样的,还有综合属性,即-fsm_encoding。
-
-fsm_encoding
该综合属性可以针对某个状态机设定编码方式(体会综合选项和综合属性功能的异同,应用场合)。 综合属性 -fsm_coding的优先级高于综合选项-fsm_extraction,但如果代码本身已经定义了编码方式,该设定将无效。
有意思的是 综合选项fsm_extraction高于HDL代码定义的编码方式,而综合属性fsm_coding优先级高于综合选项fsm_extraction,HDL代码中定义编码了却能让综合属性失效。
现在有个问题是:假如三个方式全部都定义,且定义了不同的编码方式,哪一个会生效呢??
答:关于这个问题,在问题一栏中做了尝试。
-
Keep_equivalent_registers (含义)
equivalent registers即等效寄存器,是指具有同源的寄存器,即共享输入数据的寄存器。勾选时,等效寄存器不会合并;不勾选时,等效寄存器会被合并。
![]()
示例:
//
always@(posedge clk)
begin
opa_rx <= opa;
opa_ry <= opa;
opb_r <= opb;
resa <= opa_rx and opb_r;
resb <= opb_ry xor opb_r;
end勾选与补勾选Keep_equivalent_registers的综合结果如下:


等效寄存器可以有效的降低扇出,可以通过综合属性keep避免其被合并。(详见综合属性:KEEP)
避免等效寄存器被合并的方法还有利用综合属性:KEEP。
//Vierilog示例
(*keep = "true"*) wire sig;
assign sig1 = in1 & in2 ;
assign out1 = sig1 & in2;
//VHDL 示例
signal sig1 : std_logic;
attribute keep: string;
attribute keep of sig1 :signal is "true";
....
.....
sig1 <= in1 & n2;
out1 <= sig1 & in3;-
-resource_sharing (影响算术运算)
其目的是对算术运算通过资源共享优化设计资源。默认值为auto,此时会根据设计时序需求确定是否共享资源。

示例:对加法运算利用资源共享可降低资源利用率。

资源共享 原理:

对比前后两个加法电路,很明显后者占用 资源少(面积),但肯定也是有缺点的,那就是耗时问题。这就避不开速度与面积权衡的问题了。
-resource_sharing = on时资源利用率:

-resource_sharing = off时资源利用率

-
-control_set_opt_threshold (影响触发器控制集)
触发器的控制集由时钟信号、复位/置位信号和使能信号构成,通常只有{clk,set/rst,ce}均相同的触发器才可以被放置在一个SLICE中。 但是对于同步置位、同步复位和同步使能信号,Vivado会根据-control_set_opt_threshold的设置进行优化,优化的目的就是减少控制集的个数。
优化原理:未优化前,3个触发器可能会被分别放置到3个不同的SLICE中,而经过优化以后的3个触发器会被放置到同一个SLICE中,但是此时会需要消耗查找表(LUT)资源。

control_set_opt_threshold的值为控制信号(不包括时钟和数据)的扇出个数(选项为auto和0-16),表明对小于此值的同步信号进行优化,显然此值越大,被优化的触发器越多,但占用的查找表也越多。

当control_set_opt_threshold的值设置为0时,不进行优化。
示例:
process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
qr <= '0';
else
qr <= din;
endif;
endif;
end
end process;当-control_set_opt_threshold =auto时综合后为:

当-control_set_opt_threshold = 0;

-
-no_lc (影响LUT资源)
![]()
对于一个x输入的布尔表达式和一个y输入的布尔表达式,只要满足x + y ≤5(相同变量只算一次),这两个布尔表达式就可以放置在一个LUT6中实现。 此时A6=1,运算结果分别由06和05输出。
默认情况下,当存在共享变量的时候,Vivado会自动把两个布尔表达式放在一个LUT6中实现,称为LUT整个(LUT Combining);否则仍占用两个LUT6来分别实现每个布尔表达式。但是,当-no_lc(No LUT Combining)被勾选时,则不允许出现LUT整合。 通过LUT整合可以降低LUT的资源消耗率,但也可能导致布线拥塞。因此,xilinx建议,当整合的LUT超过了LUT总量的15%时,应考虑勾选-no_lc,关掉LUT整合。
-
-shreg_min_size (影响移位寄存器)
CLB中由SLICEL和SLICEM构成,后者中的LUT可以实现移位寄存器。shreg_min_size决定了当VHDL代码描述的移位寄存器深度大于此设定值时,将采用“触发器+SRL+触发器”的方式实现,其中SRL由LUT实现。即该值与HDL中描述的移位寄存器深度关系决定了综合时采用什么样的实现方式。该值默认值为3.

在综合属性中,shreg_extract可以用于指导综合工具是否将移位寄存器推断为SRL。作为局部的综合指导命令(体会综合属性与综合选项的异同),该属性的优先级高于-shreg_min_size。例如当-shreg_min_size=3时,而shreg_extract为no,这时就算是HDL中描述的移位寄存器深度大于综合选项-shreg_min_size的值,也不会推断出采用SRL实现移位寄存器,而是会选择5个寄存器级联。
此外,综合属性srl_style可指导综合工具如何处理移位寄存器。它的6个可取值与对应的综合结果如下图所示。srl_stytle优先级同样高于综合选项-shreg_min_size,但低于shreg_extract。
综合属性srl_stytle不必与shreg_extract联合使用。


-
-bufg
控制工具在设计中推断出的BUFG数量。 当综合过程中看不到设计网表中的其他BUFG时,Vivado设计工具会使用此选项。
该工具可以推断出指定的数量,并跟踪在RTL中实例化的BUFG数量。 例如,如果-bufg选项设置为12并且在RTL中实例化了三个BUFG,则该工具最多可以推断出9个BUFG。
![]()
-
-fanout_limit
用来指定信号在开始复制逻辑之前,必须驱动的负载数。 此全局限制是一般指南,当工具确定有必要时,它可以忽略该选项。 如果需要硬限制,请参见“综合属性”中描述的MAX_FANOUT选项。
![]()
[注意]:-fanout_limit开关不影响控制信号(例如置位,复位,时钟使能,因为这些控制信号具有高扇出能力,走专用线):如果需要,使用MAX_FANOUT复制这些信号。
-
-directive
替换effort_level选项。 指定时,此选项使用不同的优化运行Vivado综合。 值为Default和RuntimeOptimized,可快速运行综合并且优化较少。

- Default,默认设置。
- RuntimeOptimized,执行最短时间的优化选项,会忽略一些RTL优化来减少综合运行时间。
- AreaOptimized_high/medium,执行一些通用的面积优化。
- AlternateRoutability,使用算法提高布线能力,减少MUXF和CARRY的使用。
- AreaMapLargeShiftRegToBRAM,将大型的移位寄存器用块RAM来实现。
- AreaMultThresholdDSP,会更多地使用DSP块资源。
- FewerCarryChains,位宽较大的操作数使用查找表(LUT)实现,而不用进位链。
-
-max_bram
描述设计中允许的最大块RAM数量。通常在设计中存在黑盒(black boxes)或第三方网表时使用,并为这些网表提供空间。
注意:默认设置为-1表示该工具选择指定零件允许的最大数量。
![]()
-
-max_dsp
描述了设计中允许的最大块DSP的数量。与max_ram一样,通常是用在设计中存在黑盒或第三方网表时候使用。并为这些网表提供空间。
-
-cascase_dsp
用来控制如何实现sum DSP块输出中的加法器。 默认情况下,使用块内置加法器链计算DSP输出的总和。 value tree强制在结构中(Fabric)实现总和。 Value包括:auto,tree和force。 默认为auto。

tcl.pre和tcl.post选项是在综合之前和之后立即运行的Tcl文件的钩子。
注意:tcl.pre和tcl.post脚本中的路径,是相对于当前工程关联的运行目录:<project> / <project.runs> / <run_name>。
有关Tcl脚本的更多信息,请参阅Vivado Design Suite用户指南中的此链接:使用Tcl脚本(UG894)。
您可以使用当前工程或当前运行的DIRECTORY属性来定义脚本中的相对路径:
获取方法:
- get_property DIRECTORY [current_project]
- get_property DIRECTORY [current_run]