提交任务命令spark-submit

查看入口类是哪个?
主要都用的就是这个了。进入这个的源码

首先进行了初始化参数,然后开始调用dupbit方法进行提交。


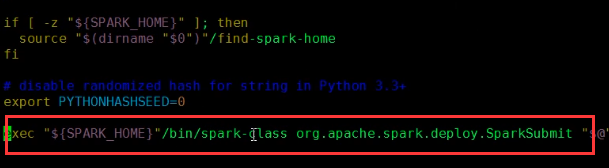
首先看一下childMainClass是什么?

是一个常量?
![]()
这个常量是通过ClientApp映射过来的

然后ClasForName获取类信

将mainClass对象映射成SparkApplication对象--app,
开始start方法

查看start方法做了什么?

可以看到有三个重要的步骤
创建rpcEnv通信环境----------------又回到了前面创建通信坏境的一步了
获取Master的通信邮箱
在rpc中设置提交当前任务的Endpoint,只要设置肯定会运行new ClinetEndpoint类的start方法

进入:

也就是这里,将“Client“EndpointData获取,将对象放到Endpoint方法中,获取Message进行获取,在里面方法如onStart样例类,通过Dispacher的index对象的process调用线程池去执行。并开始启动。
每次通过setupEndpoint方法,都会调用onStart方法,进行启动。
进入onstart方法

看到里面将DriverWrapper完整全类名给了mainClass

由将DriverWrapper这个类封装到了command中

又将command对对象封装到了driverDescription对象中,
最后将开始请求Master,这里请求Master并且发送了DriverDescription这个参数,并等待结果,
Master中的:receiveAndReply方法开始接受消息了,进行匹配RequestSubmitDriver参数

进入Master中的receiveAndReply方法匹配

将发送的参数进行封装,并且进行调度--调用schedulee()方法:

进行判断worker的可用数量*(进行判断空闲的内存、core的数量是否满足,所需要的),在可用的数量中挑选一台进行启动》
进入launchDriver中

将着了launchDriver(id,desc)发送给worker。worker进行接收,接收当然是receive方法了
去Worker中的receive方法


匹配到lunchDriver之后,会进行初始化,创建一个Driver对象。并且开始start。
首先清楚,两个参数,driverDesc中封装了一个command对象里面有mainclass类

在这里进行初始化DriverMapper,进入DriverMapper:



在这开始执行真正提交的application了

并开始执行。这里将执行我门的sparkcontext了,
进入人SparkContext.scala

可以看到每个executor中默认分配的内存是1024M

利用当前SparkContext对象和master对象以及deployMode对象作为参数,返回了一个二元组分别是
schedulerBachend和taskScheduler对象,
进入createTaskScheduler中

这里匹配的是提交方式,我们在这里提交的时候,肯定是是以“spark://”这种方式进行提交的。
里面创建了一个scheduler对象,并且将对象scheduler利用StandloneSchedulerBachend(。。。)进行了封装,封装成了backend对象。
利用scheduler的初始化方法initialize将bachend作为参数进行传递,返回了两个对象。StandloneSchedulerBackend对象中和TaskSchedulerImpl两个对象
上面看完之后继续看taskScheduler的启动

进入

由TaskScheduler启动,继续进入start,这里的bankend就是前面的StandaloneBackend

由父类调用,进入,是CoarseGrainedSchedulerBackend.scala这个类,粗粒度的调度类


这里就是创建Driver的通信邮箱,喜爱那个Rpc中注册当前的DriverEndpoint。以后也就是executor向这里的driverEndpoint进行反向注册信息

这里则开始注册了。ENDPOINT_NAME = "CoarseGrainedScheduler"
回到前面super.start


这里和前面一样都是将command进行封装,.只不过分装的是粗粒度的那个类
进入start

这里可以看到向endpoint注册了一个appCliinet

注册之后,都会启动一个onStart方法

master中注册application的信息

进入TryRegisterAllMasters()方法中

通过获取Master的名字当然是“master”了来创建通信邮箱的引用masterRef向后向Master进行发送消息。rend---RegisterApplication
去Master中找receive

开始注册app,即向ArrayBuffer中将app添加--waitingApp

最后开始调度。
scheduler()
执行:

首先进行从waitingApps中获取提交的app,遍历每一个app,遍历了之后,然后获取core的数量,如果设置了--executor-core的个数,没有设置默认就是1。
挑选出可用的worker。从workers集合中
首先判断过滤出ALIVE存活的workers,然后判断内存是否和desc中描述的一样即1024M,再次判断空闲的core数是否够(这里的core数量,用户在不设置的时候将是所有core的数量,即在没有设置的时候,当前当前的executor会使用当前所有的core的数量,),最后将这些alive的worker进行reserve反转即将拥有core数最多的worker,放在最前面。

开始划分资源。首先利用Worker上的调度器,将app,和可用的workers,以及默认是true的值

开始进行创建对象,根据分配的core,内存等信息
1.启动一个Executor需要的core,要么是None(Option->对应none和some),
2.如果用户设定了使用一个executor使用的core数量,则是指定的,否则是1.
3.第1步中指定了,coresPerExecutor为none,则这里是true
4.一个executor默认使用的内存是1024
5.传递进来可以使用的worker的个数。
6.创建了两个对象
两个对象进行分配资源,
图示解决:

/**
* coresToAssign 指的是当前要给Application分配的core是多少? app.coresLeft 与集群所有worker剩余的全部core 取个最小值
* 这里如果提交application时指定了 --total-executor-core 那么app.coresLeft 就是指定的值
*/
var coresToAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
