转载请注明出处 https://blog.csdn.net/Fire_Light_/article/details/79596024
论文链接:A Light CNN for Deep Face Representation With Noisy Labels
概述
这篇文章同样使用Maxout作为激活函数,但是和之前的Lightened CNN相比,网络参数明显提升了。
为了获得更多的训练数据,作者还使用MS-Celeb-1M作为训练集,同时也设计了一个语义自启动的过程来清楚训练集中的噪声样本。
网络结构
结构一:
1.5G FLOPS
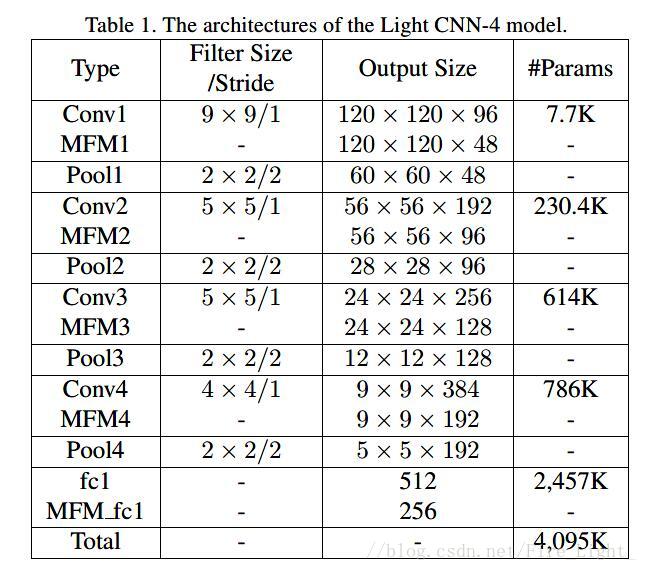
相较A lightened CNN中的结构,
卷积核不再是不同通道间权值共享了,卷积层参数也明显提升了,图中没有写出Softmax所用的参数,但是理应也加上,应该是2707K,比起lightened CNN大约有3M的参数提升。
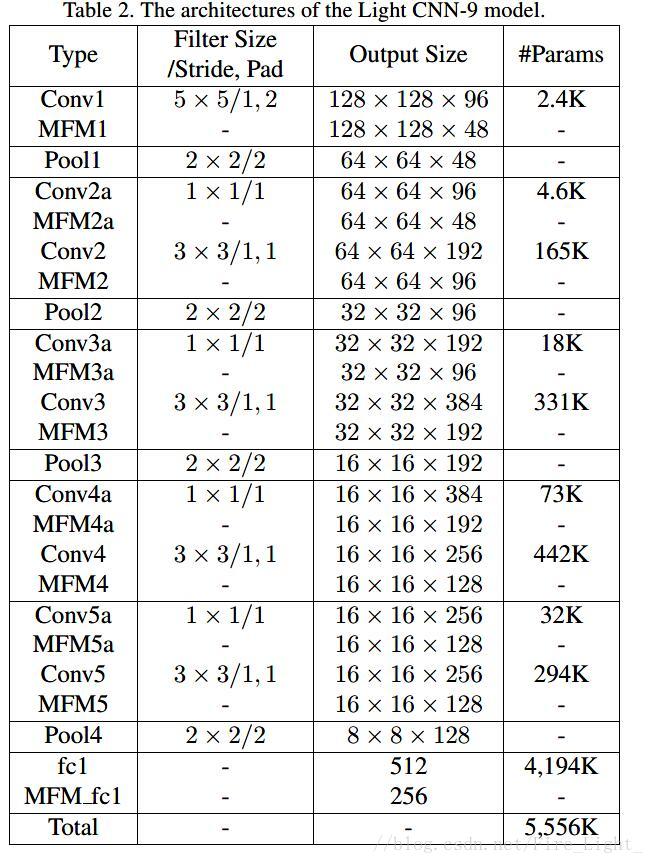
结构二
使用了所谓的NIN.其实就是在卷积层前增加1*1的卷积核降维来减小计算量。
结构三:
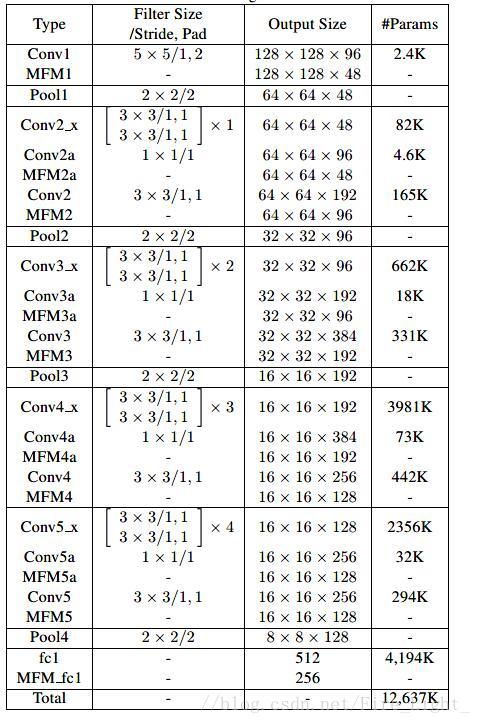
[]表示的应该是残差网络模块
与resnet不同之处在于
一、不使用Batch Nomalize.
原因是BN虽然可以加速收敛,但是依赖与特定的训练集。
并且模型通常会使用minibatch的均值和方差的滑动平均数,也就是说当Minbatch很小或者测试集与训练集相互独立的时候,batch的统计数据会缺乏普遍意义。
二、不使用平均池化层,而使用全连接层
原因是高层次的特征除了语义信息,同样包含空间信息,使用平均池化层会破坏其中的空间信息。
语义自启动(Semantic Bootstrapping )
因为MS-Celeb-1M的数据中带有大量噪声,这会对训练产生不利的影响,因此设计了一个语义自启动步骤来解决这一问题。也就是先通过CNN训练一遍MS-Celeb-1M上的数据,然后再用训练过的CNN预测训练集,根据一个阈值来筛选预测结果,对训练集的标签进行更新,然后再用更新过后的训练集重新训练网络。
实验:
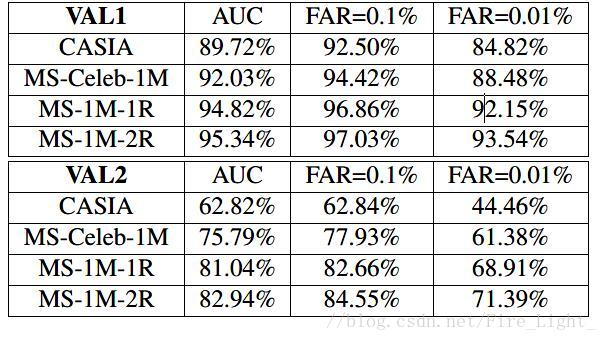
1.选择两个验证集VAL1、VAL2
2.在webface上预训练一个light CNN-8(结构二),然后再在MS上进行微调(微调的办法是先将卷积层的学习率设为0,Softmax的损失只用来训练最后一个全连接层,直到训练接近收敛时,才将前面的层的学习率调回正常值。),至收敛。
3.使用训练好的CNN预测MS中的数据,以阈值0.7更新MS的标签,把新的训练集记为MS-1M-1R,在1R上重新训练CNN
4.使用训练好的CNN预测MS中的数据,以阈值0.7更新MS的标签,把新的训练集记为MS-1M-2R,在2R上重新训练CNN
5.使用训练好的CNN在验证集上验证
结果如下:
训练参数
dropout fc1 0.7
momentum 0.9
weight decay conv- fc1:5e-4 fc2:5e-3(防止过拟合)
学习率 1e-3 to 5e-5
人脸对齐方法:检测5个人脸关键点,将两个眼睛的点旋转为水平,将两个眼睛的中点与两个嘴巴的中点之间的距离设为48像素。
训练集:CASIA-WebFace and MS-Celeb-1M datasets
结果
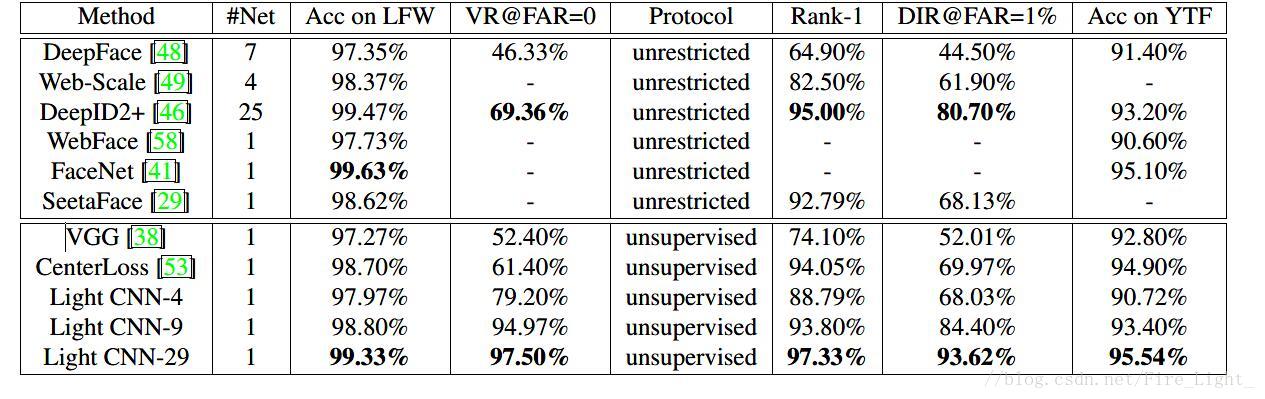
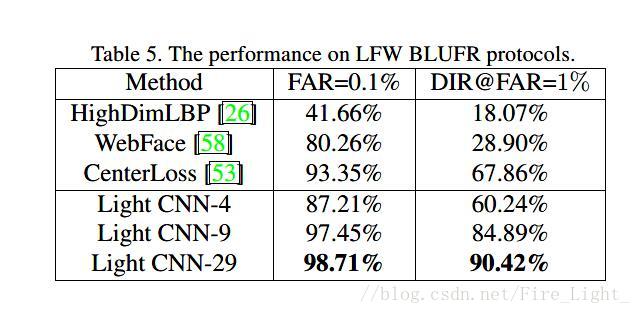
遵循的是LFW的无监督协议,即使用余弦距离作为特征相似度的衡量。
LFW-BLUFER结果