一个xml文档除了我们人去读写之外,我们还希望通过程序去操作xml文档,利用程序去增删改查xml文档的过程就称作xml编程,对xml文档解析主要有三种解析方式:SAX解析,dom解析以及pull解析。
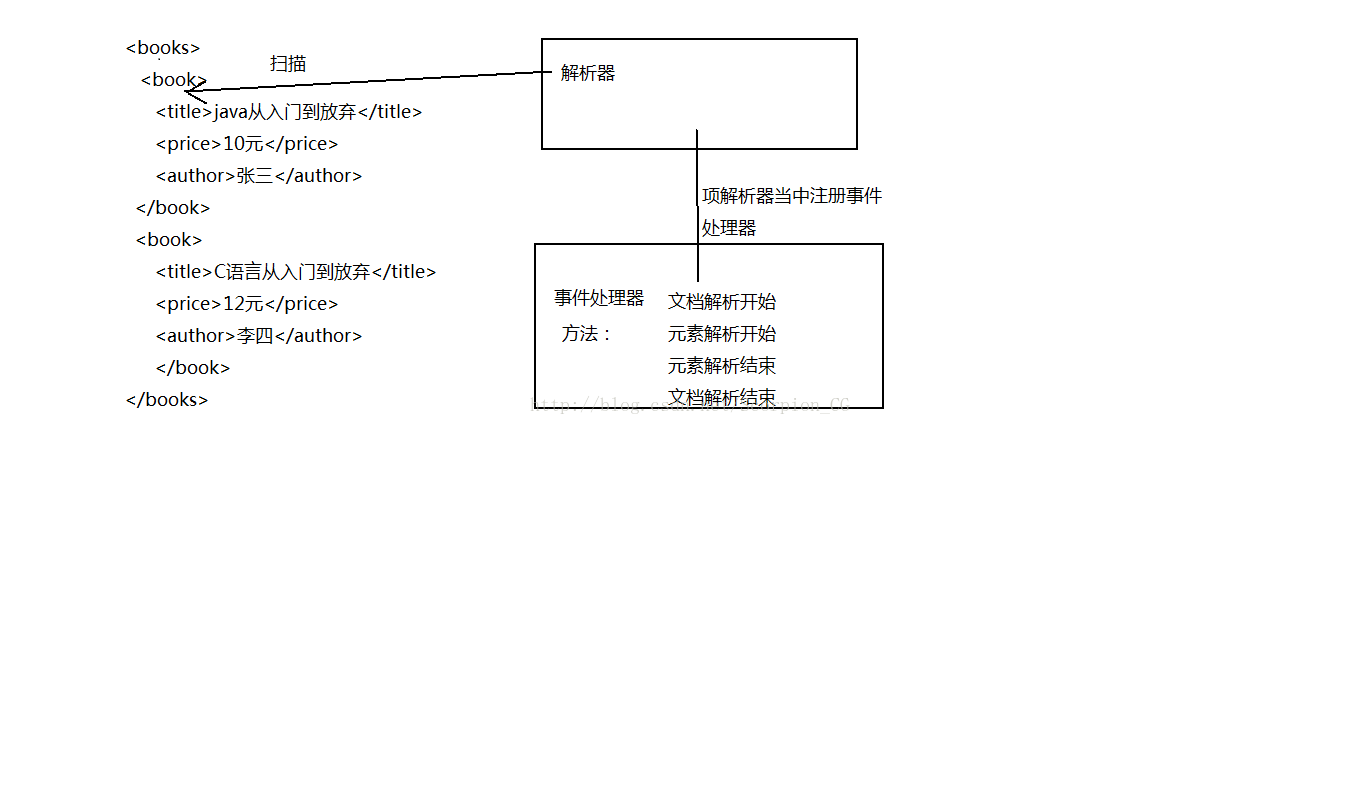
虽然SAX解析不是官方标准,但它是xml社区事实上的标准,几乎所有的xml解析器都支持他。我们首先来介绍SAX解析xml文档。我们有一个xml文档。<books>
<book>
<title>java从入门到放弃</title>
<price>10元</price>
<author>张三</author>
</book>
<book>
<title>C语言从入门到放弃</title>
<price>12元</price>
<author>李四</author>
</book>
</books>一个SAX解析过程当中有两个组件,一个是读取器(解析器)还有一个是事件处理器。解析器部分我们就不用操心了,jdk中已经帮我们做好了。我们要做的就是编写事件处理器的代码。SAX解析的过程为:在解析xml文档时,解析器会去逐行的扫描xml文档,当扫描到解析器当中的任意一个内容时,都会触发事件处理器当中的相应的方法。我们可以用下面这张图片表示SAX解析的处理过程
了解了SAX解析的过程,我们下面用java语言实现这个过程:
例如:我们要打印出这个xml文档中的所有的书的名字:
package com.hhuc.Sax;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
public class Demo {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
SAXParserFactory spf=SAXParserFactory.newInstance();//使用SAXParserFactory创建SAX解析工厂
SAXParser sp=spf.newSAXParser(); //通过SAX解析工厂得到解析器对象
XMLReader xmlreader=sp.getXMLReader(); //通过解析器对象的到一个xml的读取器
xmlreader.setContentHandler(new DefaultHandler(){
private String elename=null;
@Override
public void startElement(String uri, String localName,
String qName, Attributes attributes) throws SAXException {
elename=qName;
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
elename=null;
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if("title".equals(elename))
System.out.println(new String(ch,start,length));
}
});
xmlreader.parse("book.xml"); //解析xml文档
}
}