版权声明:个人做题总结专用~ https://blog.csdn.net/tb_youth/article/details/91349338
STL有全排列函数next_permutation:传送门
不过还是自己写写比较好啊~
自己写全排列:
#include <iostream>
#include <algorithm>
using namespace std;
const int MAXN = 105;
int a[MAXN];
int n,cnt;
inline void mySwap(int i,int j)
{
int temp;
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
inline void print(int *a)
{
for(int i = 0; i < n; i++)
{
cout<<a[i]<<" ";
}
cout<<"\n";
}
/*
全排列递归写法(非字典序)
基本思想:
每次固定该序列的某一个数(固定到s位置),
然后递归调用其他数构成的子序列全排列,
直到需要全排列的子序列只有一个数就打印出整个序列
然后递归返回
*/
//去重
bool check(int cur)
{
for(int i = cur+1; i < n; i++)//确保只与它后面不相等的数字交换
{
if(a[cur] == a[i])
return false;
}
return true;
}
void permutation(int *a,int s)
{
if(s == n)
{
cnt++;
print(a);
return;
}
for(int i = s; i < n; i++)
{
if(check(i))
{
mySwap(s,i);
permutation(a,s+1);
mySwap(s,i);
}
}
}
/*
全排列非递归算法,
并且字典序,
会去重
*/
void permutationTwo(int *a)
{
sort(a,a+n);
//第一个要打印出来
cnt++;
print(a);
while(1)
{
int pos = -1;
/*
从前往后找最后一个:a[i]<a[i+1],pos = i,
现在从后往前找以提高效率,即转化为
第一个:a[i] > a[i-1],pos = i - 1;
*/
for(int i = n-1; i >= 0; i--)//i > 0 防止数组越界
{
if(a[i] > a[i-1])
{
pos = i - 1;
break;
}
}
if(pos == -1) break;
int k = -1;
/*
找pos之后最后一个a[i] > a[pos],k = i,
从后向前找即第一个a[i] > a[pos],k = i
*/
for(int i = n-1; i > pos; i--)
{
if(a[i] > a[pos])
{
k = i;
break;
}
}
//交换pos,k两个位置元素的值
mySwap(pos,k);
//反转pos之后元素
for(int i = pos+1,j = n-1; i <= j; i++,j--)
{
mySwap(i,j);
}
cnt++;
//打印permutation
print(a);
}
}
int main()
{
cin>>n;
for(int i = 0; i < n; i++)
{
cin>>a[i];
}
cout<<"permutation:"<<endl;
permutation(a,0);
cout<<"permutation count = "<<cnt<<endl;
cnt = 0;
cout<<"permutationTwo:"<<endl;
permutationTwo(a);
cout<<"permutationTwo count = "<<cnt<<endl;
return 0;
}
测试结果:
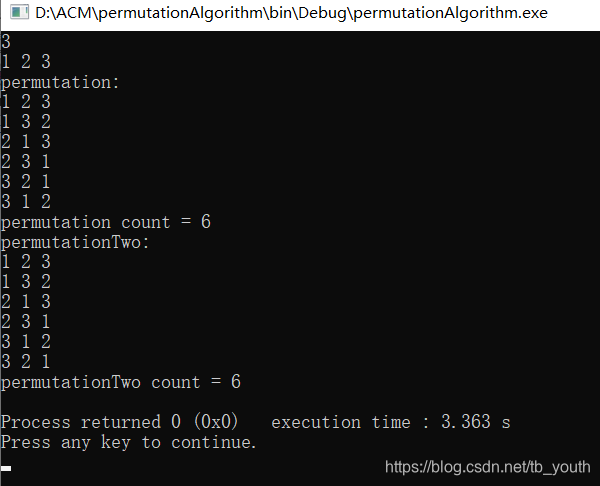
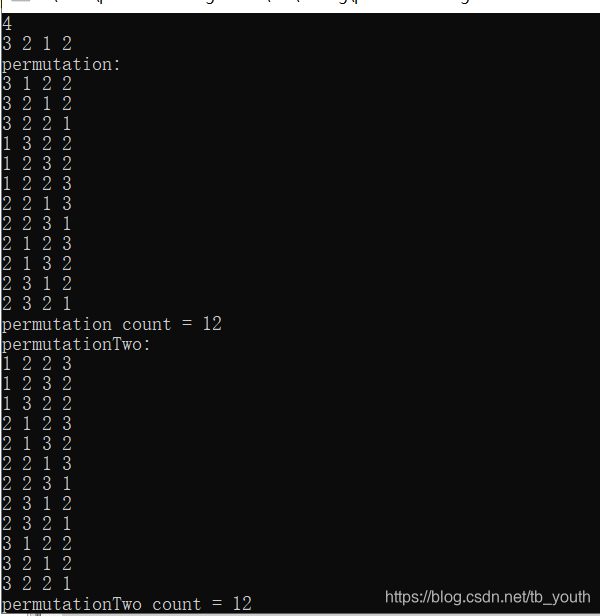
时间复杂度:
递归和非递归都近似O(n!)
但是非递归相对要慢一些,因为它在其他方面,
比如反转,查找等方面增加了时间消耗。