编写MapReduce任务
实验要求
本次实验输入为包含各科成绩文本,每一行分别为科目和成绩,要求使用MapReduce模型进行编程,输出单科最高分。要求实验报告包含编写的代码以及实验步骤。
将数据上传到hdfs
hadoop fs -mkdir /data
hadoop fs -put ~/subject_score.txt /data
查看
hadoop fs -ls /data

将jar包提交到hadoop执行
hadoop jar ~/WordCount.jar wordcount input output
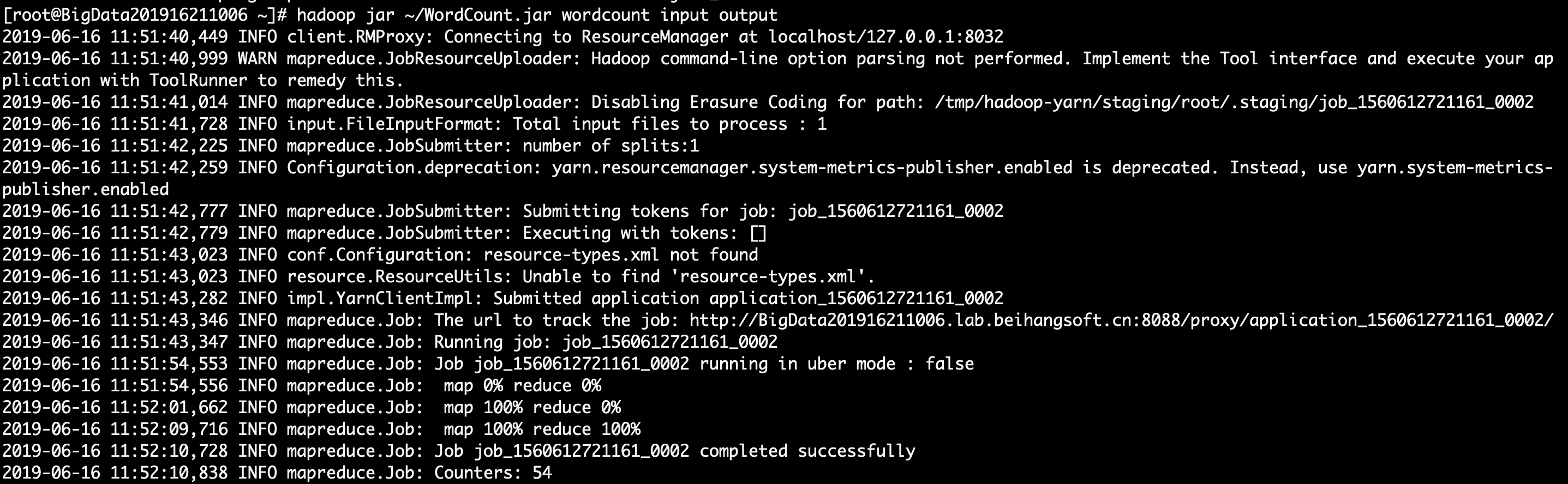
查看hdfs的目录结构我们可以推测出/wordcount_output/part-r-00000运行后的输出
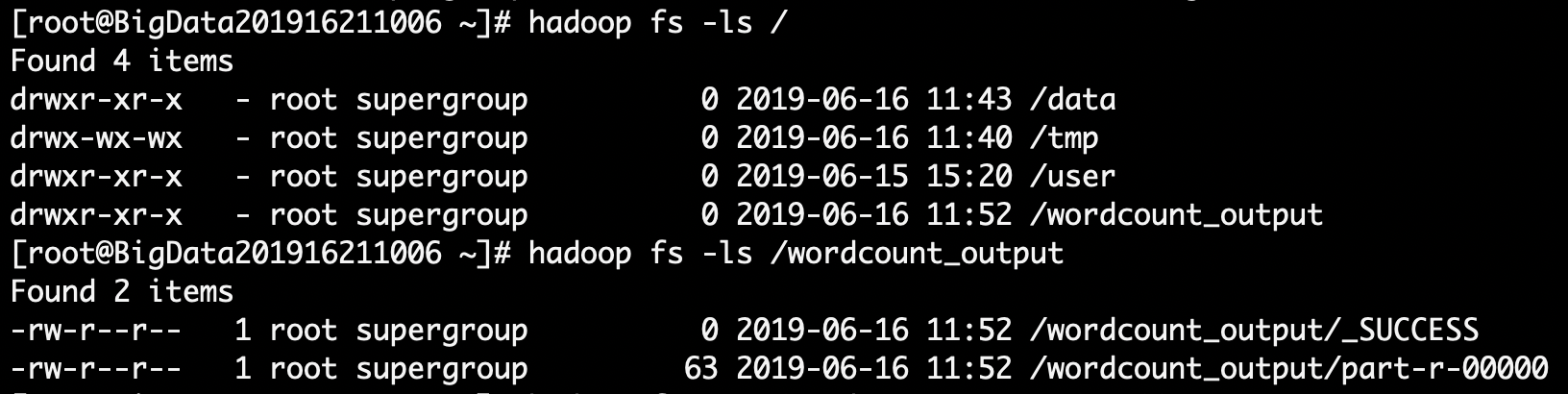
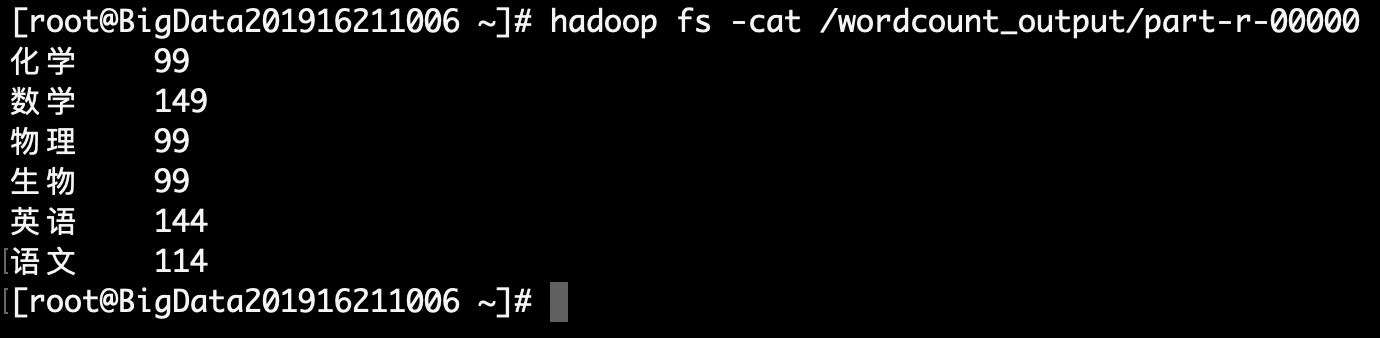
查看输出
hadoop fs -cat /wordcount_output/part-r-00000
java class打包
首先打开Project Structure,选中Artifacts
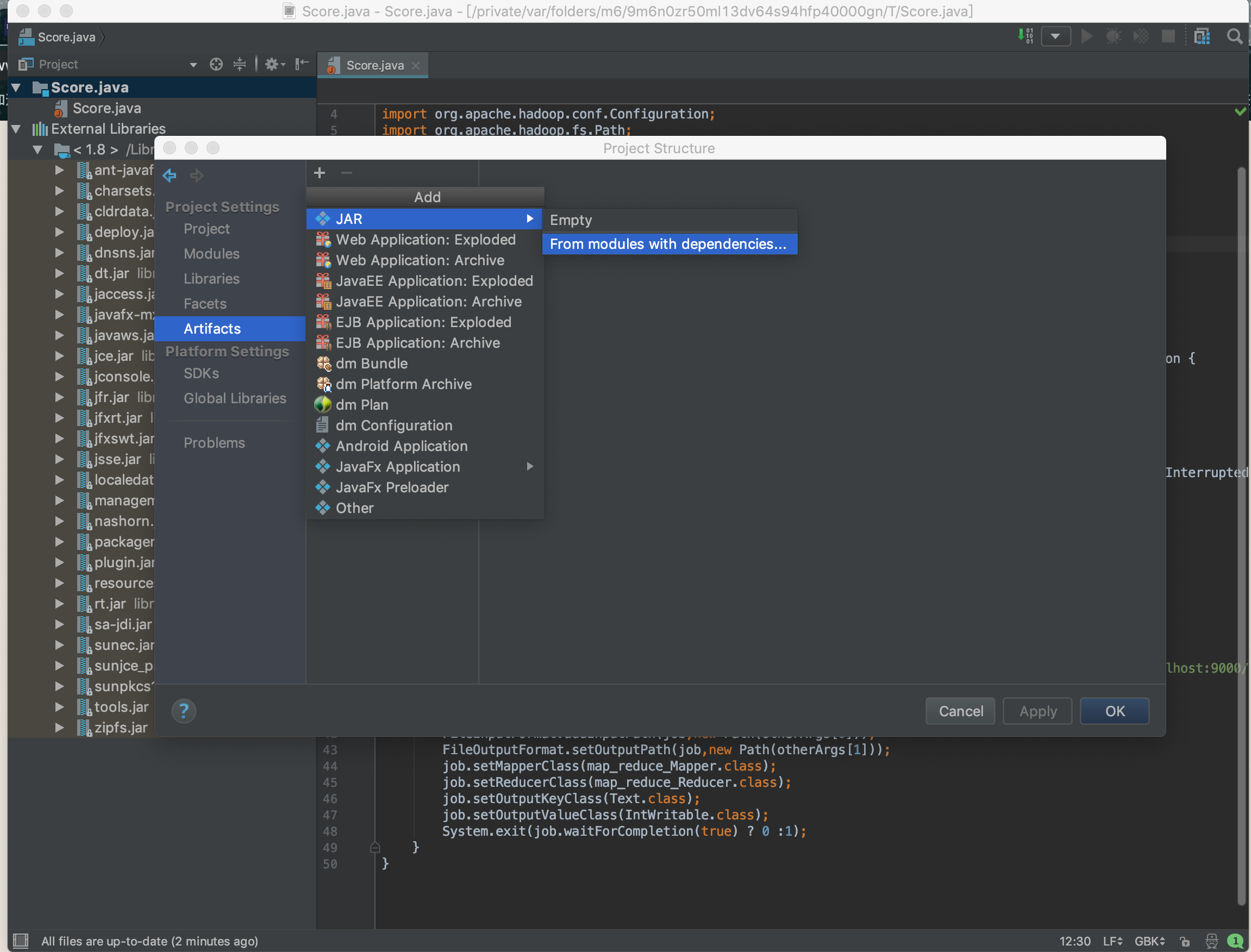
点击加号,选中jar ,然后选中from modules with dependencies
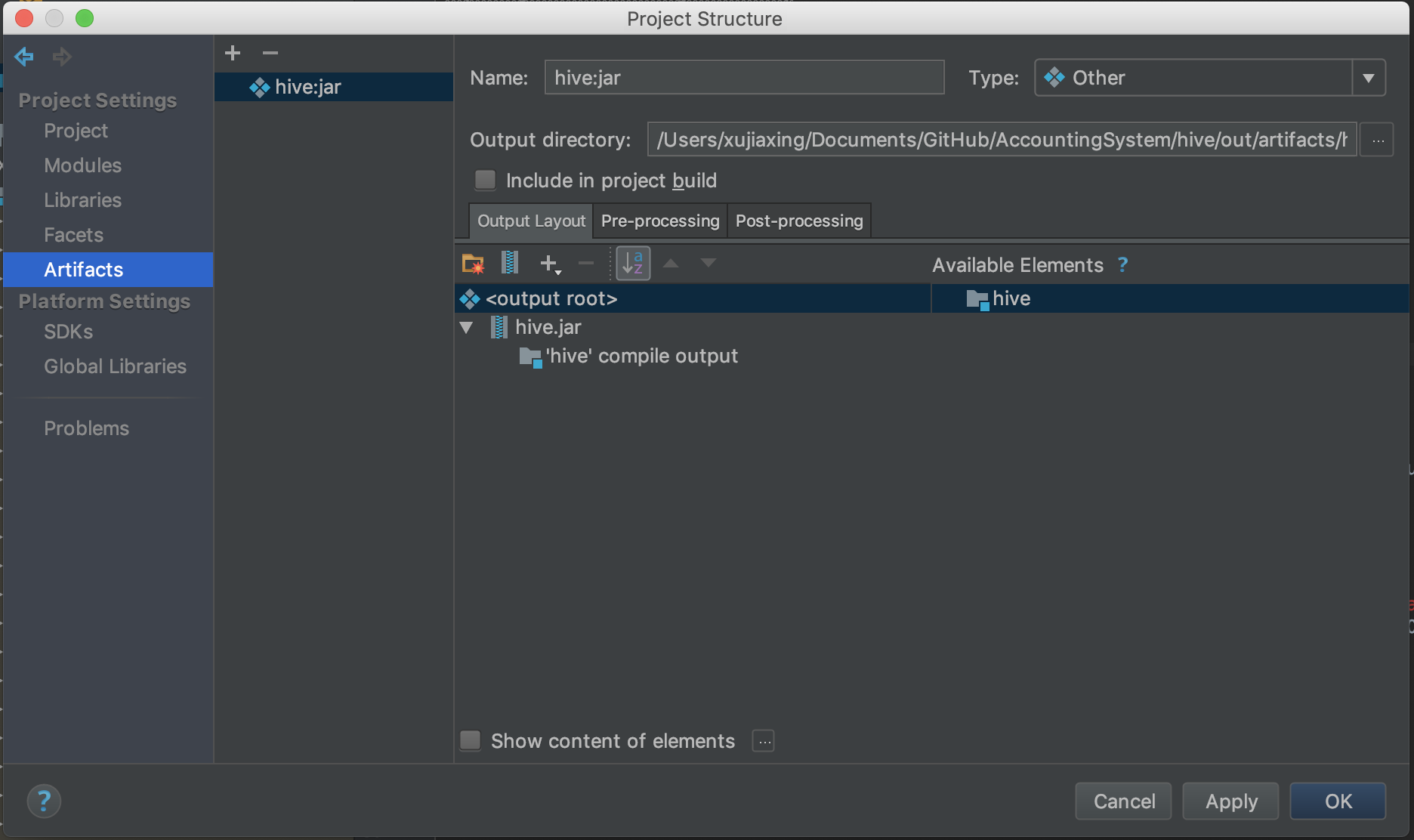
之后点击Build ,选中Build artifacts,就会出现对应的jar包
代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class map_reduce {
public static class map_reduce_Mapper extends Mapper<Object, Text, Text, IntWritable> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
context.write(new Text(words[0]),new IntWritable(Integer.parseInt(words[1])));
}
}
public static class map_reduce_Reducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int max = 0;
for(IntWritable v:values){
if(v.get()>max)
max = v.get();
}
context.write(key,new IntWritable(max));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String [] otherArgs = new String []{"hdfs://localhost:9000/data/subject_score.txt","hdfs://localhost:9000/wordcount_output"};
Job job = new Job();
job.setJarByClass(map_reduce.class);
job.setJobName("map_reduce app");
FileInputFormat.addInputPath(job,new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
job.setMapperClass(map_reduce_Mapper.class);
job.setReducerClass(map_reduce_Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 :1);
}
}