八、可靠性探究
1、副本剖析
- 副本是相对于分区而言的,即副本是特性分区的副本
- 一个分区中包含一个或多个副本,其中一个为leader副本,其余为follower副本,各个副本位于不同的broker节点中。只有leader副本对外提供服务,follower副本只负责数据同步
- 分区中的所有副本统称为AR,而ISR是指与leader副本保持同步状态的副本(包括leader)集合,OSR是指与leader副本同步滞后过多的副本。AR=ISR+OR
- LEO标识每个分区中最后一条消息的下一个位置,分区的每个副本都有自己的LEO,ISR中最小的LEO即为HW,俗称高水位,消费者只能拉取到HW之前的消息
从生产者发出的一条消息首先会被写入分区的leader副本,不过还需要等待ISR集合中所有follower副本都同步完之后才能被认为已经提交,之后才会更新分区的HW,进而消费者可以消费到这条消息
1)、失效副本
在ISR集合之外的副本统称为失效副本,失效副本对应的分区称为同步失效分区,即under-replicated
使用kafka-topics.sh脚本的under-replicated-partitions参数来显示主题中包含失效副本的分区
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --describe --topic topic-demo --under-replicated-partitions
Topic: topic-demo Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2
Topic: topic-demo Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2
Topic: topic-demo Partition: 2 Leader: 2 Replicas: 0,1,2 Isr: 2
Topic: topic-demo Partition: 3 Leader: 2 Replicas: 1,0,2 Isr: 2
主题topic-demo中的四个分区都为under-replicated分区,因为它们都有副本处于下线状态
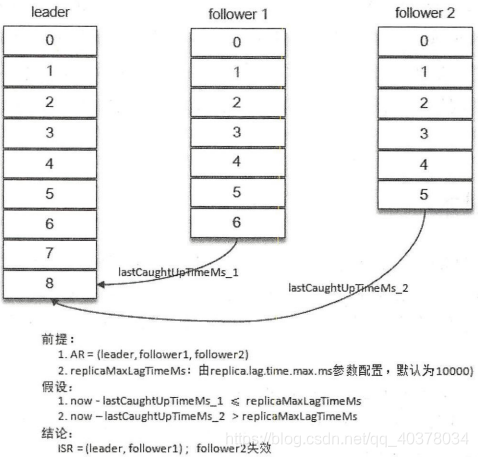
当ISR集合中的一个follower副本滞后leader副本的时间超过broker端参数replica.lag.time.max.ms指定的值时则判定为同步失败,需要将此follower副本剔除出ISR集合,此参数默认值为10000
当follower副本将leader副本LEO之前的日志全部同步时,则认为该follower副本已经追赶上leader副本,此时更新该副本的lastCaughtUpTimeMs标识。Kafka的副本管理器会启动一个副本过期检测的定时任务,而这个定时任务会定时检查当前时间与副本的lastCaughtUpTimeMs差值是否大于参数replica.lag.time.max.ms指定的值
如果增加了副本因子,那么新增的副本在赶上leader副本之前都是处于失效状态的。如果一个follower副本由于某些原因而下线,之后又上线,在追赶上leader副本之前也处于失效状态
2)、ISR的伸缩
Kafka在启动的时候会开启两个与ISR相关的定时任务,分别为isr-expiration和isr-change-propagation。isr-expiration任务会周期性地检测每个分区是否需要缩减其ISR集合。这个周期和replica.lag.time.max.ms参数有关,大小是这个参数的一半,默认值为5000ms。当检测到ISR集合中有失效副本时,就会收缩ISR集合。如果某个分区的ISR集合发生变更,则会将变更后的数据记录到ZooKeeper对应的/brokers/topics/<topic>/partition/<partition>/state节点中。节点中的数据示例如下:
{"controller_epoch":21,"leader":-1,"version":1,"leader_epoch":38,"isr":[1]}
controller_epoch表示当前Kafka控制器的epoch,leader表示当前分区的leader副本所在的broker的id编号,version表示版本号(当前版本固定位1),leader_epoch表示当前分区的leader纪元,isr表示变更后的ISR列表
当ISR集合发生变更时还会将变更后的记录缓存到isrChangeSet中,isr-change-propagation任务会周期性(固定值为2500ms)地检查isrChangeSet,如果发现isrChangeSet中有ISR集合的变更记录,那么它会在ZooKeeper的/isr_change_notification路径下创建一个以isr_change_开头的持久顺序节点,并将isrChangeSet中的信息保存到这个节点中。Kafka控制器为/isr_change_notification添加了一个Watcher,当这个节点有子节点发生变化时会触发Watcher的动作,以此通知控制器更新相关元数据信息并向它管理的broker节点发送更新元数据的请求,最后删除/isr_change_notification路径下已经处理过的节点。频繁地触发Watcher的动作会影响Kafka控制器、ZooKeeper甚至其他broker节点的性能。为了避免这种情况,Kafka添加了限定条件,当检测到分区的ISR集合发生变化时,还需要检查以下两个条件:
- 上一次ISR集合发生变化距离现在已经超过5s
- 上一次写入ZooKeeper的时间距离现在已经超过60s
满足以下两个条件之一才可以将ISR集合的变化写入目标节点
OSR集合中的副本进入ISR集合的判断准则是此副本的LEO是否不小于leader副本的HW,ISR扩充之后同样会更新ZooKeeper中的/brokers/topics/<topic>/partition/<partition>/state节点和isChangeSet,之后的步骤和ISR收缩时的相同
LW是Low Watermark的缩写,俗称低水位,代表AR集合中最小的logStartOffset值
3)、LEO与HW
对于副本而言,有两个概念:本地副本和远程副本。本地副本是指对应的Log分配在当前的broker节点上,远程副本是指对应的Log分配在其他的broker节点上。在Kafka中,同一个分区的信息会存在多个broker节点上,并被其上的副本管理器所管理,这样在逻辑层面每个broker节点上的分区就有了多个副本,但是只有本地副本才有对应的日志
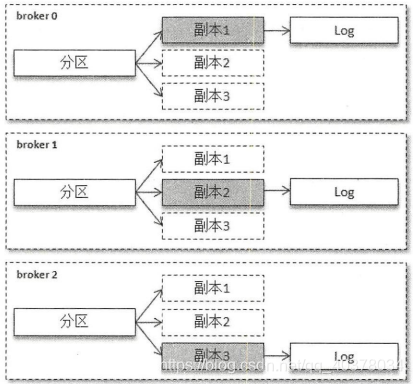
如上图所示,某个分区有3个副本分别位于broker0、broker1、broker2节点中,其中带阴影的方框表示本地副本。假设broker0上的副本1为当前分区的leader副本,那么副本2和副本3就是follower副本,整个消息追加的过程可以概括如下:
A.生产者客户端发送消息至leader副本中
B.消息被追加到leader副本的本地日志,并且会更新日志的偏移量
C.follower副本向leader副本请求同步数据
D.leader副本所在的服务器读取本地日志,并更新对应拉取的follower副本的信息
E.leader副本所在的服务器将拉取结果返回给follower副本
F.follower副本收到leader副本返回的拉取结果,将消息追加到本地日志中,并更新日志的偏移量信息
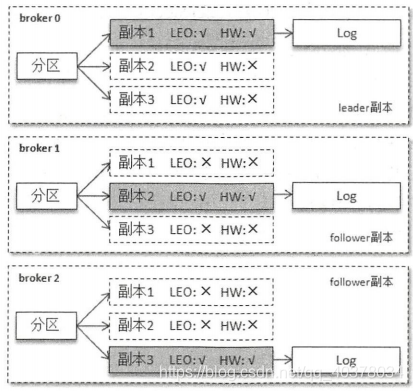
在一个分区中,leader副本所在的节点会记录所有副本的LEO,而follower副本所在的节点只会记录自身的LEO,而不会记录其他副本的LEO。leader副本收到follower副本的FetchRequest请求之后,它会首先从自己的日志文件中读取数据,然后再返回给follower副本数据前先更新follower副本的LEO。对HW而言,各个副本所在的节点都只记录它自身的HW
Kafka的根目录下有cleaner-offset-checkpoint、log-start-offset-checkpoint、recovery-point-offset-checkpoint、replication-offset-checkpoint四个检查点文件。
recovery-point-offset-checkpoint和replication-offset-checkpoint这两个文件分别对应了LEO和HW。Kafka会有一个定时任务负责将所有分区的LEO刷写到恢复点文件recovery-point-offset-checkpoint中,定时周期由broker参数log.flush.offset. checkpoint.interval.ms来配置,默认值为60000。还有一个定时任务负责将所有分区的HW刷写到复制点文件replication-offset-checkpoint中,定时周期由broker端参数replica.high.watermark.checkpoint.interval.ms来配置,默认值为5000
log-start-offset-checkpoint文件对应logStartOffset,用来标识日志的起始偏移量。各个副本在变动LEO和HW的过程中,logStartOffset也可能随之而动。Kafka也有一定定时任务负责将所有分区的logStartOffset书写到起始点文件log-start-offset-checkpoint中,定时周期由broker端参数log.flush.start.offset.checkpoint.interval.ms来配置,默认值为60000
4)、Leader Epoch的介入
在Kafka0.11.0.0版本之前,如果leader副本发生切换,Kafka使用的是基于HW的同步机制,有可能出现数据丢失或leader副本和follower副本数据不一致的问题
数据丢失问题:
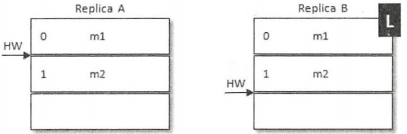
Replica B是当前的leader副本,Replica A是follower副本,在某一时刻,B中有2条消息m1和m2,A从B中同步了这两条消息,此时A和B的LEO都为2,同时HW都为1;之后A再向B中发送请求以拉取消息,FetchRequest请求中带上了A的LEO信息,B在收到请求之后更新了自己的HW为2;B中虽然没有更多的消息,但还是在延时一段时间之后(延时拉取)返回FetchResponse,并在其中包含了HW信息;最后A根据FetchResponse中的HW信息更新自己的HW为2
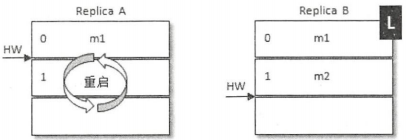
整个过程中两者之间的HW同步有一个间隙,在A写入消息m2之后需要再一轮的FetchRequest/FetchResponse才能更新自己的HW为2。如果在这个时候A宕机了,那么在A重启之后会根据之前HW位置进行日志截断,这样便将会m2这条消息删除,此时A只剩下m1这条消息,之后A再向B发送FetchRequest请求拉取消息
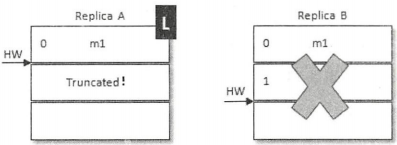
此时若B再宕机,那么A就会被选举为新的leader,B恢复之后会变为follower,由于follower副本HW不能比leader副本的HW高,所以还会做一次日志截断,以此将HW调整为1。这样m2这条消息就丢失了
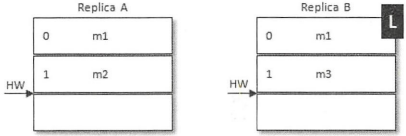
数据不一致问题:
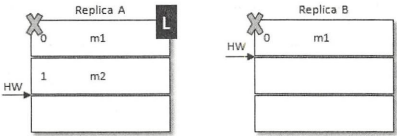
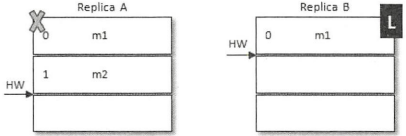
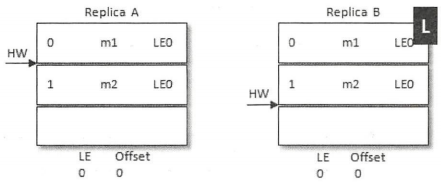
如上图所示,当前leader副本为A,follower副本为B,A中有2条消息m1和m2,并且HW和LEO都为2,B中有1条消息m1,并且HW和LEO都为1。假设A和B同时挂掉,然后B第一个恢复过来并成为leader
之后B写入消息m3,并将LEO和HW更新至2。此时A也恢复过来了,A成为了follower,需要根据HW截断日志及发送FetchRequest至B,此时A的HW正好也为2,不需要做任何调整了。这样A中保留了m2而B中没有,B中新增了m3而A也同步不到,这样A和B就出现了数据不一致的情形
为了解决上述两种问题,在Kafka0.11.0.0版本开始引入了leader epoch的概念,在需要截断数据的时候使用leader epoch作为参考数据而不是原本的HW。leader epoch代表leader的纪元信息,初始值为0。每当leader变更一次,leader epoch的值就会加1,相当于为leader增设一个版本号。与此同时,每个副本中还会增设一个矢量<LeaderEpoch=>StartOffset>,其中StartOffset表示当前LeaderEpoch下写入的第一条消息的偏移量。每个副本的Log下都有一个leader-epoch-checkpoint文件,在发生leader epoch变更时,会将对应的矢量对追加到这个文件中
LeaderEpoch解决数据丢失问题:
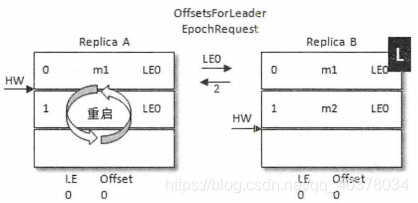
同样A发生重启,之后A先发送OffsetsForLeaderEpochRequest请求给B(其中包含A当前的LeaderEpoch值),B作为目前的leader在收到请求之后会返回当前的LEO,与请求对应的响应OffsetsForLeaderEpochResponse
如果A中的LeaderEpoch(假设LE_A)和B中的不同,那么B此时会查找LeaderEpoch为LE_A+1对应的StartOffset并返回给A,也就是LE_A对应的LEO
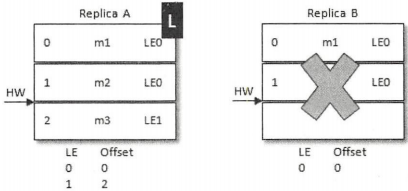
A在收到2之后发现和目前的LEO相同,就不需要截断日志了。之后B发生了宕机,A成为新的leader,那么对应的LE=0也变成了LE=1,对应的消息m2此时就得到了保留,之后不管B有没有恢复,后续的消息都可以以LE1为LeaderEpoch陆续追加到A中
LeaderEpoch解决数据不一致问题:
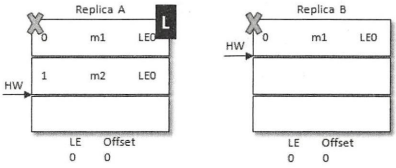
当前A为leader,B为follower。A中有2条消息m1和m2,而B中有1条消息m1。假设A和B同时挂掉,然后B第一个恢复过来成为leader
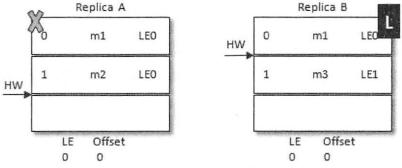
之后B写入消息m3,并将LEO和HW更新至2,此时LeaderEpoch已经从LE0增至LE1了
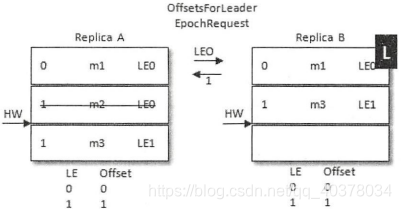
紧接着A也恢复过来成为follower并向B发送OffsetsForLeaderEpochRequest请求,此时A的LeaderEpoch为LE0。B根据LE0查询到对应的offset为1并返回给A,A就截断日志并删除了消息m2,之后A发送FetchRequest至B请求来同步数据,最后A和B中都有两条消息m1和m3,HW和LEO都为2,并且LeaderEpoch都为LE1
2、可靠性分析
就Kafka而言,越多的副本数越能够保证数据的可靠性,副本数可以在创建主题时配置也可以在后期修改,不过副本数越多也会引起磁盘、网络带宽的浪费,同时会引起性能的下降。一般而言,设置副本数为3即可满足绝大多数场景对可靠性的要求
生产者客户端参数acks,相比于0和1,acks=-1可以最大程度地提高消息的可靠性
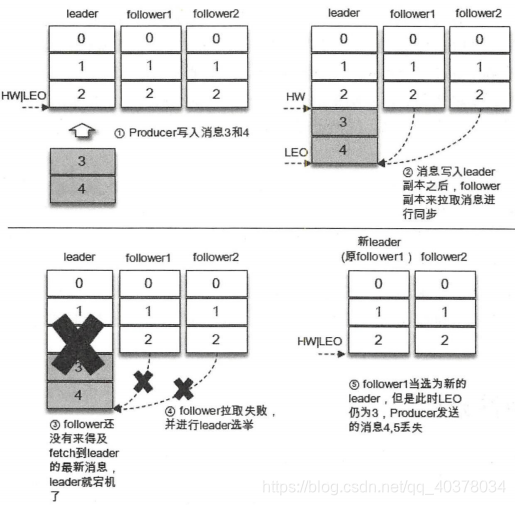
对于ack=1的配置,生产者将消息发送到leader副本,leader副本在成功写入本地日志会后会告知生产者已经成功提交。如果此时ISR集合的follower副本还没来得及拉取到leader中新写入的消息,leader就宕机了,那么此次发送的消息就会丢失
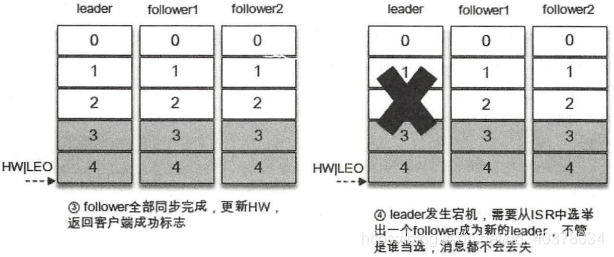
对于ack=-1的配置,生产者将消息发送到leader副本,leader副本在成功写入本地日志之后还要等待ISR中的follower副本全部同步完成才能告知生产者已经成功提交,即使leader副本宕机,消息也不会丢失
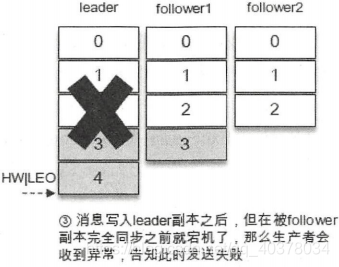
同样对于ack=-1的配置,如果在消息成功写入leader副本之后,并且在被ISR中的所有副本同步之前leader副本宕机了,那么生产者会收到异常以此告知此次发送失败
消息发送的3种模式,即发后即忘、同步和异步。对于发后即忘的模式,不管消息有没有被成功写入,生产者都会不会收到通知,那么即使消息写入失败也无从得知,因此发后即忘的模式不适合高可靠性要求的场景。如果要提升可靠性,那么生产者可以采用同步或异步的模式,在出现异常情况时可以及时获得通知,以便可以做相应的补救措施,比如选择重试发送
有些发送异常属于可重试异常,客户端内部提供了重试机制来应对这类异常,通过retries参数即可配置。retry.backoff.ms参数用来设定两次重试之间的时间间隔,以此避免无效的频繁重试
与可靠性和ISR集合有关的还有一个参数——unclean.leader.election.enable。这个参数的默认值为flase,如果设置为true就意味着当leader下线时候可以从非ISR集合中选举出新的leader,这样有可能造成数据的丢失
在broker端还有两个参数log.flush.interval.messages和log.flush.interval.ms用来调整同步刷盘的策略,默认是不做控制而交给操作系统本来来进行处理。同步刷盘是增强一个组件可靠性的有效方式,但可靠性不应该由同步刷盘这种极其损耗性能的操作来保障,应该采用多副本的机制来保障
enable.auto.commit参数的默认值为true,即开启自动位移提交的功能,这种方式可能会带来重复消费和消息丢失的问题,对于高可靠性要求的应用来说需要将enable.auto.commit参数设置为false来执行手动位移提交。在执行手动位移提交的时候要遵循一个原则:如果消息没有被成功消费,那么就不能提交所对应的消费位移