可靠数据传输的原理
由于实现可靠数据传输的问题不仅仅出现在传输层,而且在链路层和应用层。这个问题对networking很关键。
下图就展现了我们学习可靠数据传输的框架。
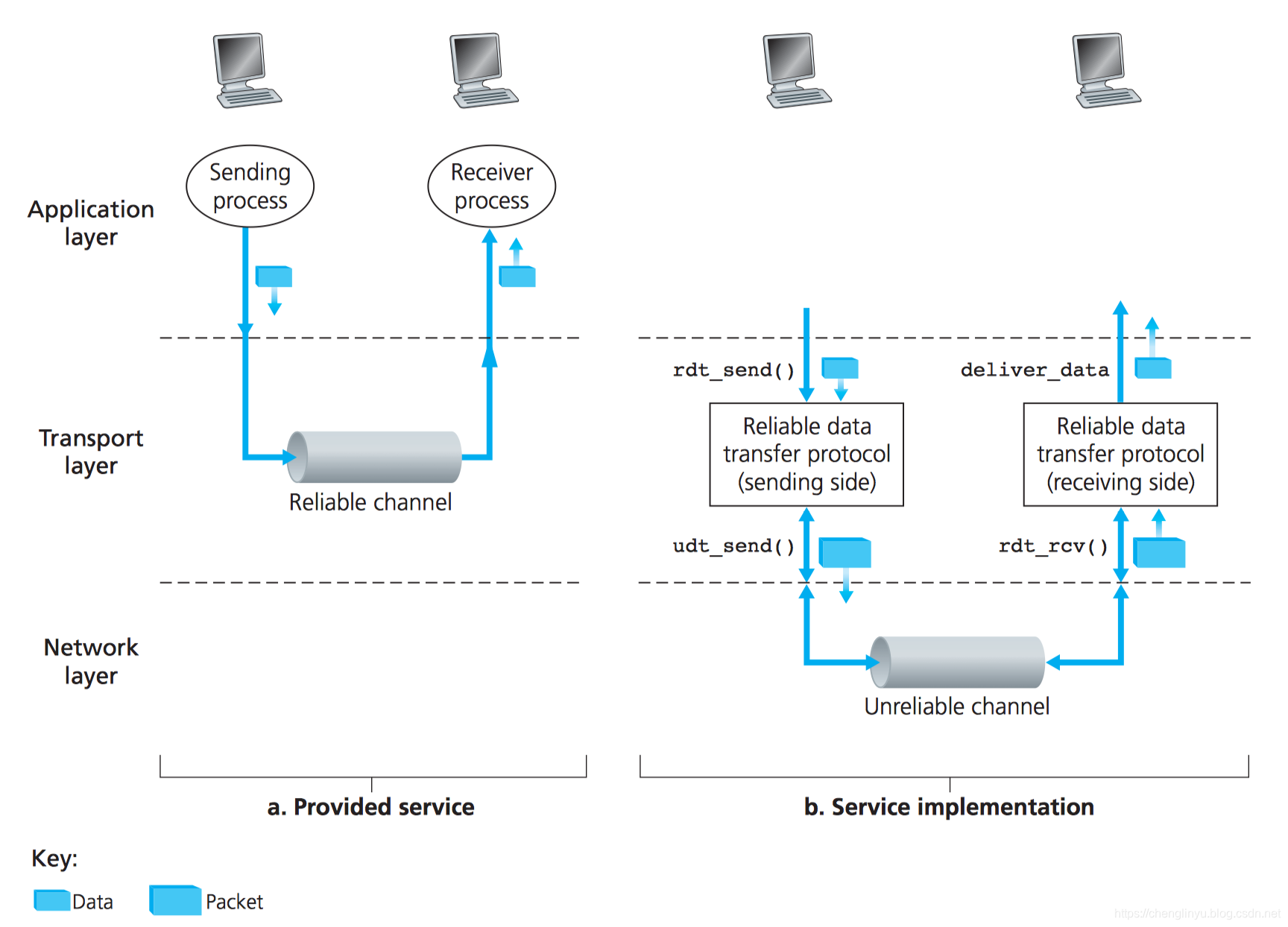
左边是提供的服务,右边是服务的实现。
左边提供的服务模型是TCP提供给网络应用的准确模型。
好了,实现这个模型是谁的责任呢?可靠数据传输协议(reliable data transfer protocol),可靠数据传输协议是一类协议,(例如TCP协议)
这个任务之所以难,就是因为在可靠数据传输协议的下层可能是不可靠的。
举个例子,TCP是一个可靠数据传输协议,implemented on top of 不可靠的(IP)端到端网络层。
udt----unreliable data transfer
单向数据传输(unidirectional data transfer)
数据传输是从发送端到接收端的。
双向数据传输(bidirectional data transfer),全双工数据传输)
不会更难。
构建一个可靠数据传输协议
在一个完美可靠的渠道上的可靠数据传输: rdt 1.0
我们首先考虑最简单的情况——下层渠道完全可靠。这个协议本身,我们叫做rdt1.0, rdt 1.0发送端和接收端的有穷状态自动机的定义如下图。
有穷自动机中横线上方是触发的事件。
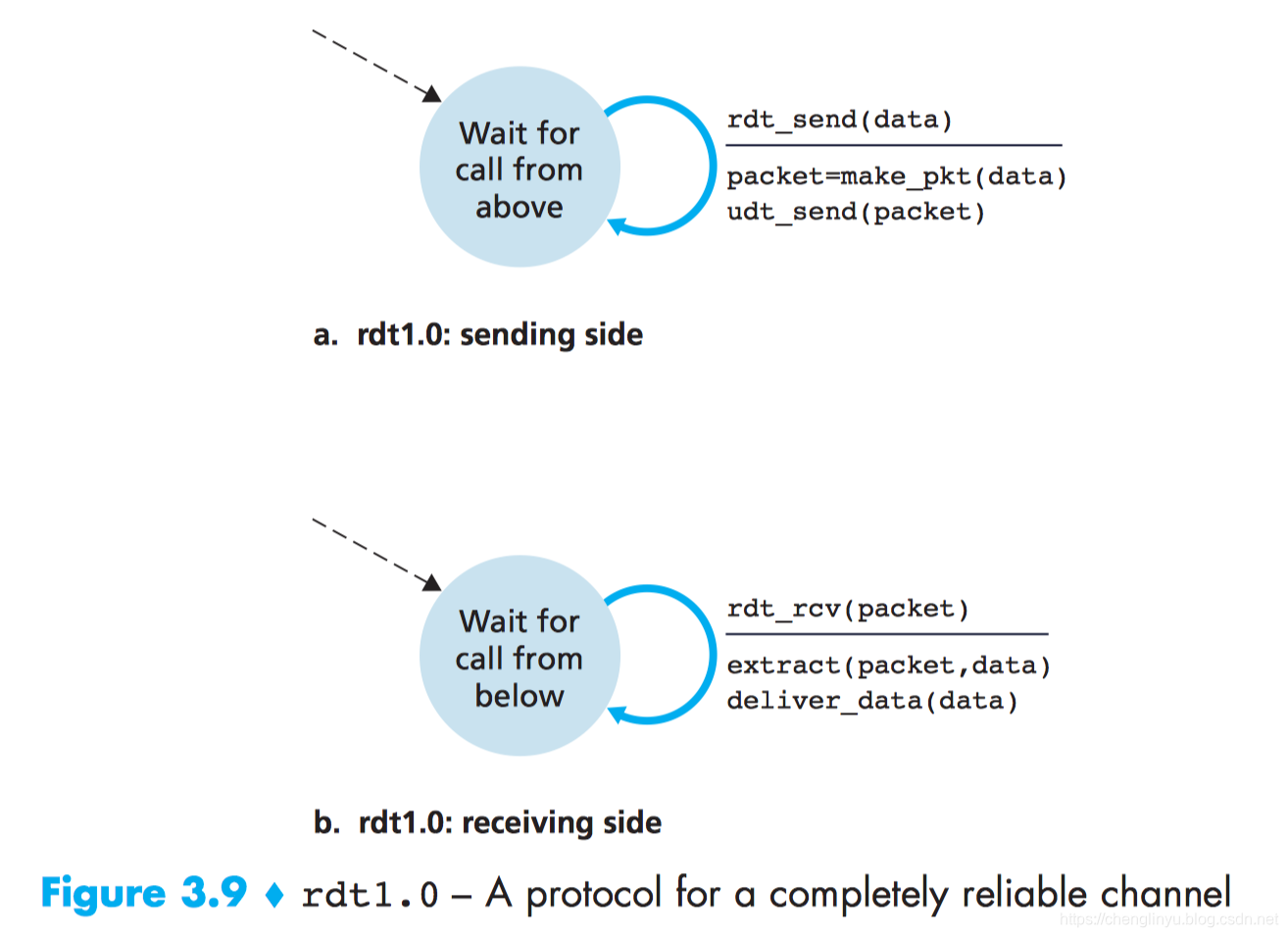
rdt_send(data): rdt的发送端通过该事件从上层接收数据,通过动作make_pkt(data)创建一个包含数据的分组,并把分组发送给channel.
实际上rdt_send(data)这个事件源于上层应用的程序调用,(例如 ,rdt_send() )
在接收端,rdt经由事件rdt_rcv(packet)从下层渠道获取分组,移除来自分组的数据(via the action extract( packet, data)), 将数据pass给上上层(通过action deliver_data(data)). 实际上, rdt_rcv(packet)事件源于来自下层协议的程序调用(例如rdt_rcv())
在这个简单的协议中,一个单元数据和一个分组没有差别。而且所有分组是从发送方流向接收方;有了完全可靠的信道,接收端就不需要任何反馈信息给发送方,因为不必担心出现差错!
在一个有比特错误的渠道上的可靠数据传输协议: rdt2.0
底层渠道更加实际的一个模型是:分组中的bit可能会受损。这样的bit错误通常出现在一个网络的物理部件中。我们将继续假定所有被传送的分组都将按照它们被发送的顺序接收。
在开发这样一个在这样的渠道之上的可靠传输协议之间,我们首先考虑一下人们会怎么样处理这样一个情况。想象一下你自己对着手机通过讯飞的语音识别发消息的时候。在一个经典的场景中,这个消息的接受者在被一个句子都已经被听清楚之后数偶一个OK。如果一个消息接受者接收到一个错乱的消息,你被会要求重复这个错乱的消息。这个message-dictation的协议使用了肯定确认(positive acknowledgement)(“OK”)与否定确认(negative acknowledgement)(“请重复一遍”)。这些控制报文使得接收方可以让发送方知道哪些内容被正确接收,哪些内容有误并因此需要重复。在计算机网络环境中,基于这样重传机制的可靠数据传输协议称为自动重传请求(Automatic Repeat Request , ARQ)协议。
基本上,在ARQ协议中还需要3个额外的协议来处理这些bit错误的存在。
-
错误检测
首先需要一种机制以使接收方检测什么时候出现了比特差错。UDP使用因特checksum字段正是为了这个目的。现在我们只需要知道这些技巧需要额外的bit位(beyond the bits of original data to be transmitted), 这些比特位will be gathered into the packet checksum field of the rdt2.0 数据分组。 -
接收方反馈
因为发送方和接收方通常在不同的端系统上执行,可能相隔万里,发送方要了解接收方情况(此时为分组是否被正确接收)的唯一途径就是让接收方提供明确的反馈信息给发送方。在口述报文情况下下回答的“肯定确认“和”否定确认“都是反馈的例子。我们的rdt 2.0也会类似地从接收方发送ACK和NAK分组到发送方。理论上,这些分组只需要一个bit长,例如用0表示NAK,用1表示ACK。 -
重新传送
-
接收方收到有差错的分组时,发送方将重传该分组。
下图是rdt2.0的有穷自动机
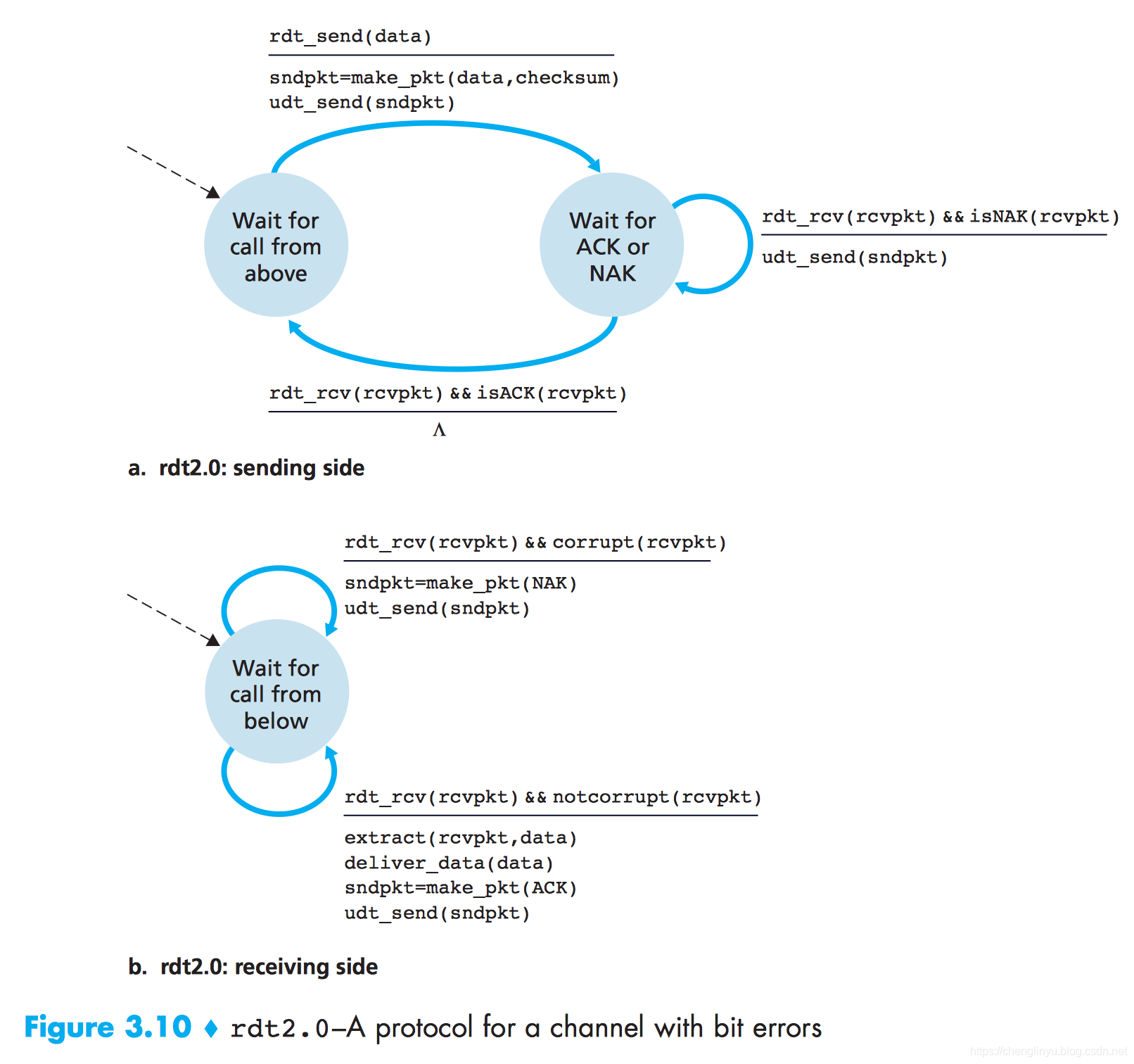
原来这里绘制的是有穷自动机,最开始一直没有看懂,后来才看懂。
有可能会考看图写话。
那么这里是不是要解释一下:
rdt2.0的发送端协议
rdt2.0的发送端有2个状态,左边的状态,发送端协议正在等待数据从上次pass down下来。当事件rdt_send(data)事件出现了之后,这个发送者会创建一个分组(sndpkt),包括要发送的数据,along with 一个分组checksum,然后将这个分组通过udt_send(sndpkt)操作发送,然后发送端协议等待接收方的ACK或者是NAK 分组。如果ACK分组被收到,(the notation rdt_rcv(rcvpkt) && isACK(rcvpkt) in the picture对应这个事件),这个发送者就会知道最近被出传输的分组已经被只呢狗却收到,因此协议返回到the state of waiting for data from the upper layer. 如果一个NAK is received, 这个协议重新传送上一个分组,等待一个ACK或者是NAK被返回in reponse to the retransmitted packet. 要注意,当一个发送者is in the wait-for-ACK-or-NAK状态,这个发送者是不能够从上一层中再获取数据的。也就是说rdt_send()事件不能够出现。rdt_send will happen仅当发送方收到一个ACK或者是离开这个状态的时候。因此,这个发送方不会发送a new piece of data直到发送方确认接收方已经正确地收到the current packet. 由于这个行为,类似于rdt2.0的协议被称为stop-and-wait协议(停等协议)。
rdt2.0的接收方协议
rdt2.0的接收方仍然只有一个状态。当分组到达时,接收方要么回答一个ACK,要么回答一个NAK,这取决于收到的分组是否受损。在上图中,rdt_rcv(rcvpkt) && corrupt(rcvpkt)对应于一个分组并发现有错的事件。
rdt2.0存在的致命缺陷:
尤其是我们没有考虑到ACK或NAK分组受损的可能性!
至少我们需要在ACK/NAK分组中添加checksum比特位以检测这样的差错。
更难的问题是协议应该怎样纠正ACK或者NAK分组中的差错。
这里的难点在于:如果一个ACK或者NAK分组受损,发送方无法知道接收方是否正确接收了上一块发送的数据。
解决这个新问题的一个简单方法(几乎所有的数据传输协议中,包括TCP,都采用了这种方法)是在数据分组中添加一新字段,让发送方对其数据分组编号,即将发送数据分组的**序号(sequence number)**放在该字段,于是,接收方只需要检查序号就可以确定收到的分组是否一次重传。
还有2.1, 3.0, 流水线,内容是真的多,先看看别的吧。