文章目录
可靠数据传输原理
TCP处于运输层中,虽然下层协议——网络层协议是不可靠的,但TCP必须为它的上层提供一种可靠数据传输协议(reliable data transfer protocol)。
这种协议提供的服务为:数据可以通过一条可靠的信道进行传输。借助于可靠信道,传输数据比特就不会受到损坏或丢失,而且所有数据都是按照其发送顺序交付给接收方。
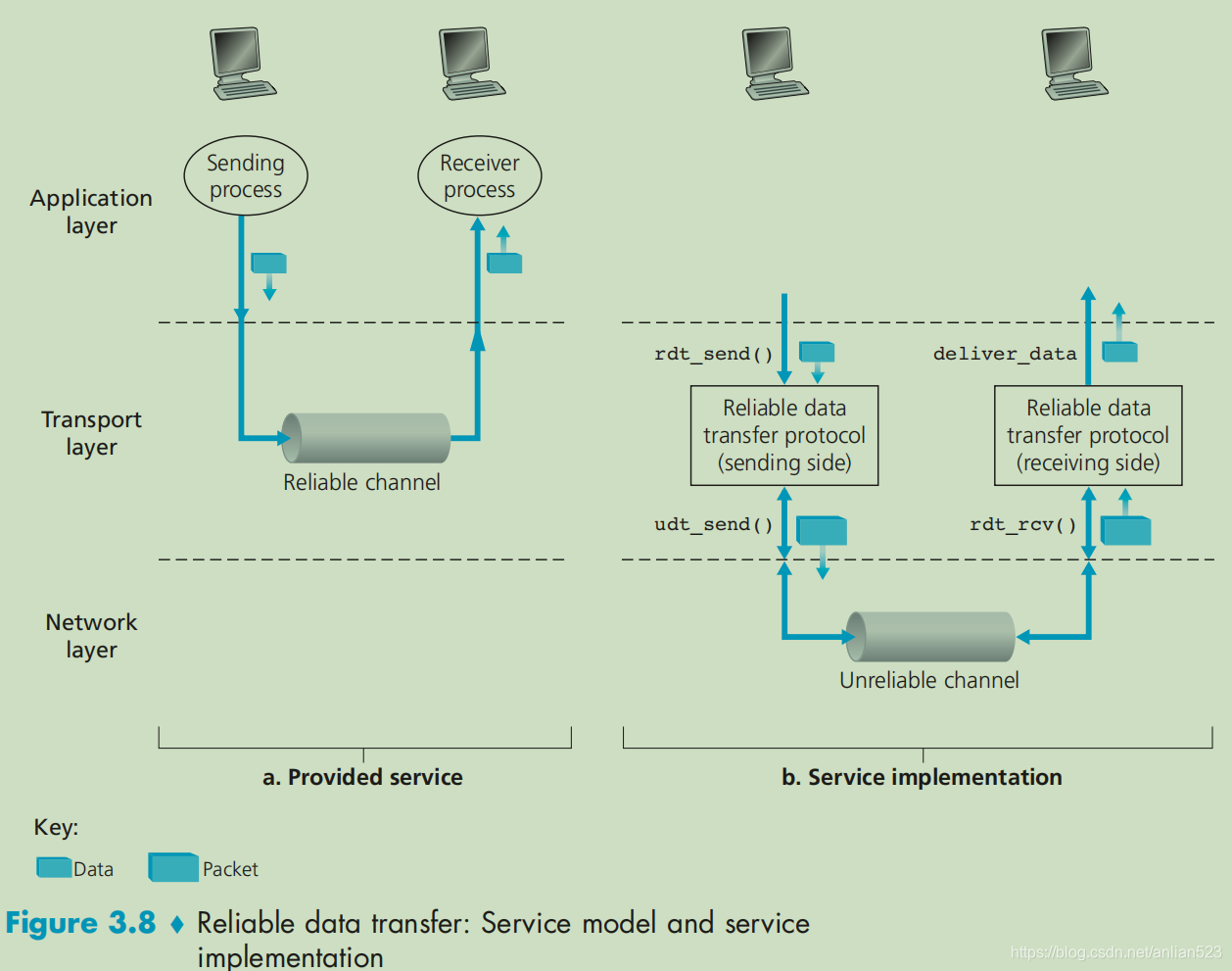
从上图可以看出,可靠数据传输协议是建立在不可靠信道之上的。
rdt协议
rdt 1.0
首先假设底层信道是完全可靠的。
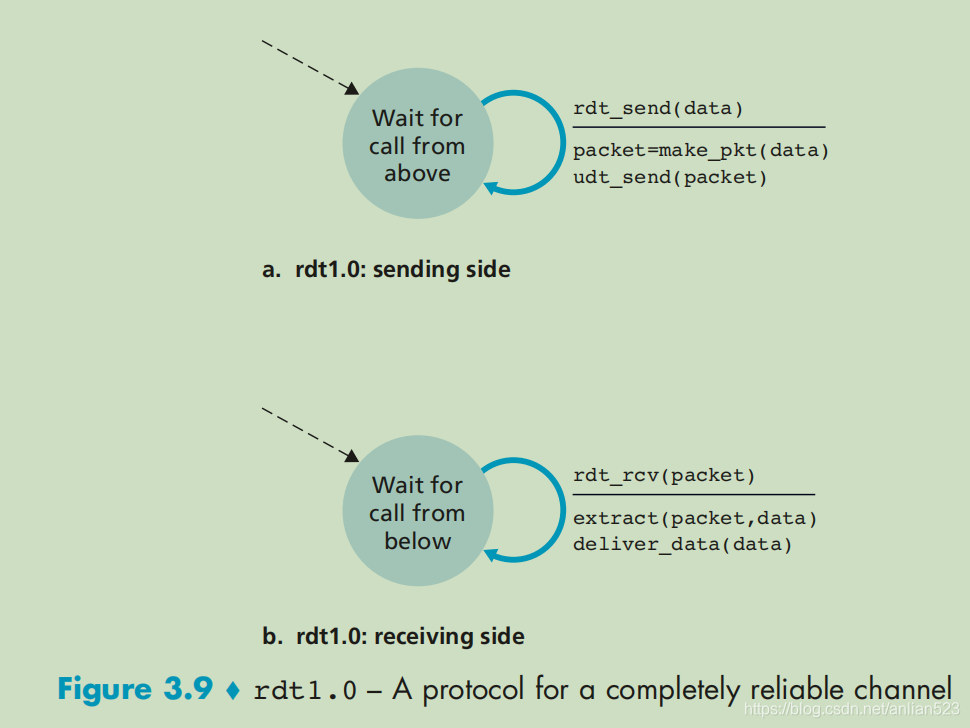
可见发送方和接收方的状态机都很简单。有了完全可靠的信道,接收方不需要提供任何反馈给发送方。
发放方:
rdt_send(data)//上层要发送数据了
------------------------------------
packet=make_pkt(data)//将数据打包
udt_send(packet)//发送
接收方:
rdt_rcv(packet)//从下层接收到pkt
------------------------------------
extract(packet,data)//从pkt中抽取数据
deliver_data(data)//向上层交付数据
rdt 2.0
现在假设经过底层信道后,分组中的比特可能受损(由0变成1,或者1变成0),但发送的分组还是可以按其发送顺序被接收。
现在让接收方检查分组,如果接到的分组没有损坏,那么反馈给发送方一个ACK(positive acknowledgement);如果接到的分组损坏了,那么反馈给发送方一个NAK(negative acknowledgement),那么发送方则会重传这个分组。这种基于重传机制的可靠数据传输协议称为自动重传请求协议(ARQ)。
ARQ协议中还需要另外三种协议功能来处理存在比特差错的情况:差错检测,接收方反馈,重传。
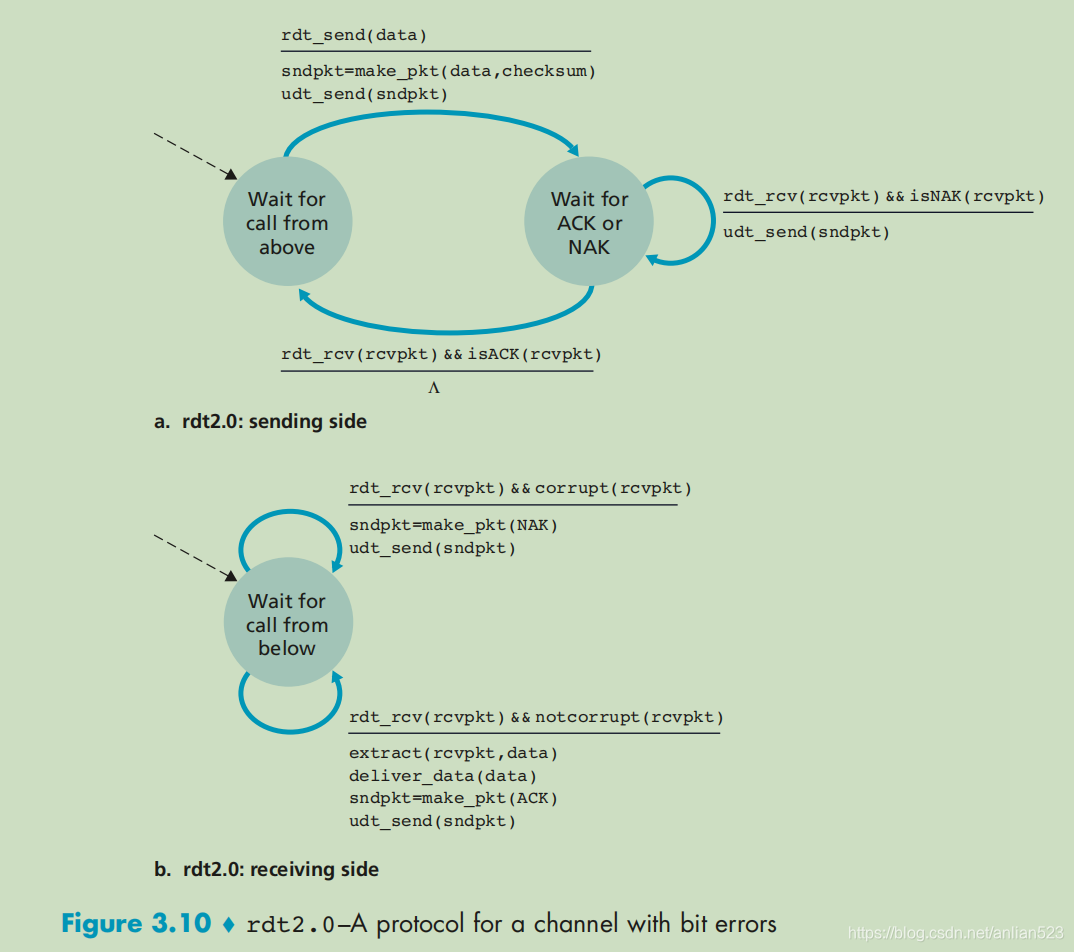
rdt2.0的发送端每发送一个分组需要等待接收端的确认信号,这种协议被称为停等协议。
发放方:
rdt_rcv(rcvpkt) && isNAK(rcvpkt)//发送方收到的反馈为NAK时
------------------------------------
udt_send(sndpkt)//重新发送 上一次发送的分组
接收方:
rdt_rcv(rcvpkt) && corrupt(rcvpkt)//接收方收到损坏的分组
------------------------------------
sndpkt=make_pkt(NAK)//反馈NAK
udt_send(sndpkt)
rdt_rcv(rcvpkt) && notcorrupt(rcvpkt)//接收方收到完好的分组
------------------------------------
extract(rcvpkt,data)//抽取数据
deliver_data(data)//交付上层
sndpkt=make_pkt(ACK)//反馈ACK
udt_send(sndpkt)
rdt 2.1
rdt 2.0 中有一个致命的缺陷,就是没有考虑到接收方反馈的 ACK 和 NAK 分组受损的可能性。
当发送方收到含糊不清的ACK 和 NAK分组时,只需要重传上一次发送的分组即可。但对于接收方来说,它无法区分这个分组到底是一个新分组,还是一个重传的分组。
为了解决接收方的困惑,我们在数据分组中添加一个字段,让发送方对其数据分组编号,把发送数据分组的 序号 放在sequence字段中。于是,接收方只需要检查序号即可确定收到的分组是否一次重传。对于停等协议这种简单的情况,1 比特的序号就足够了。简单的说:接收方期待收到的序号为:0,1,0,1…
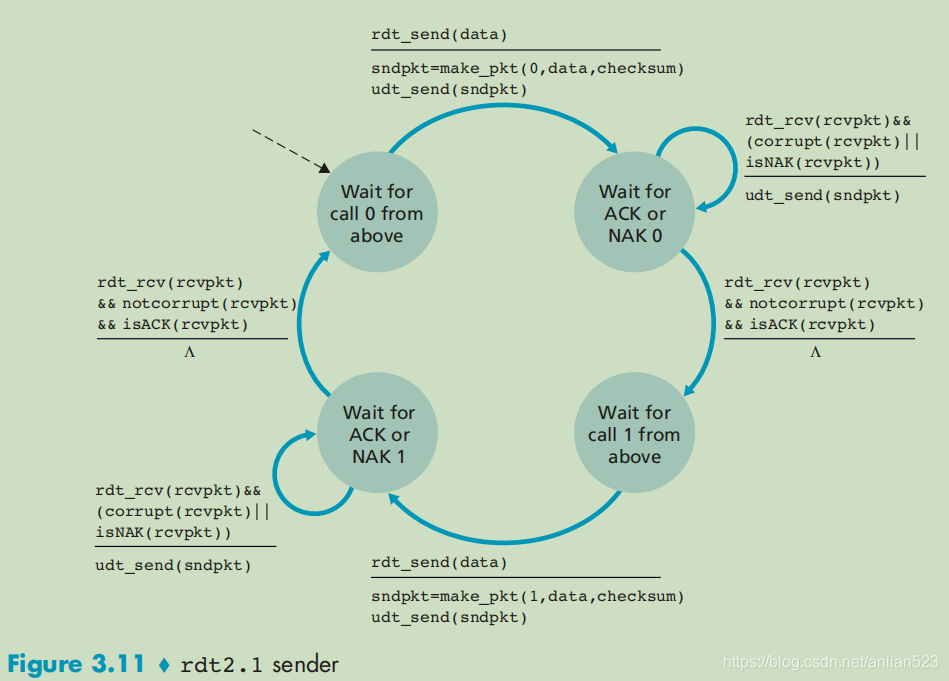
相比上一个版本,这个版本:发送方会去检测ACK或NCK是否已经corrupt了,从而判断是否需要重新发送。也就是说,上一个版本认为接收方发出的ACK或NCK是必然不会损坏的。
rdt_rcv(rcvpkt)&&
(corrupt(rcvpkt)||
isNAK(rcvpkt))//如果收到的反馈损坏了
------------------------------
udt_send(sndpkt)//重新发送 上一次发送的分组
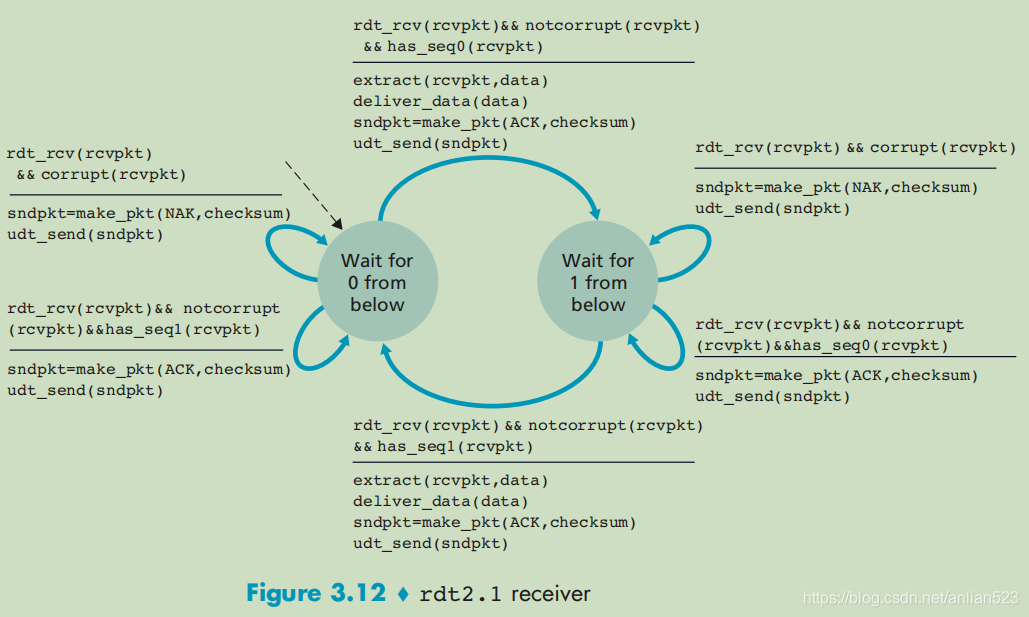
而接收方会根据序号来判断是否需要extract出数据给应用层,上一个版本是没有序号的。
rdt_rcv(rcvpkt)
&& corrupt(rcvpkt)//当收到了损坏的序号分组(这里指上图的左边状态机)
----------------------------------
//不会向上层交付数据
sndpkt=make_pkt(NAK,checksum)//因为损坏,所以反馈NAK
udt_send(sndpkt)
这里讲一个实例:
- 初始时:发送方wait for call 1 from above;接收方wait for 1 from blow。
- 发送方被call 1,然后发送序号为1的数据包,但接收方接受到的是 损坏的数据包(即不知道序号是多少)。
- 发送方跳转到wait for ACK or NAK 1。
- 接收方反馈NAK,然后在wait for 1 from blow原地踏步。
- 反馈的NAK运输途中损坏或者没损坏(都会到下面这步)。
- 发送方重新发送 这个序号为1的数据包。发送方还是处于wait for ACK or NAK 1。
- 如果发送方重新发送的序号为1的数据包又损坏了,会一直重复上面这两步。
rdt_rcv(rcvpkt)&& notcorrupt(rcvpkt)&&
has_seq1(rcvpkt)//当收到了非期待的但完好的序号分组(这里指上图的左边状态机)
----------------------------------
//不会向上层交付数据
sndpkt=make_pkt(ACK,checksum)//因为完好,所以反馈ACK
udt_send(sndpkt)
这里讲一个实例:
- 初始时:发送方wait for call 1 from above;接收方wait for 1 from blow。
- 发送方被call 1,然后发送序号为1的数据包,且接收方完好接受到 序号为1的数据包。
- 发送方跳转到wait for ACK or NAK 1。
- 接收方反馈ACK,然后跳转到wait for 0 from blow。
- 反馈的ACK运输途中损坏了。
- 发送方收到了corrupt的ACK包,然后重新发送 这个序号为1的数据包。发送方还是处于wait for ACK or NAK 1。
- 接收方此时处于wait for 0 from blow,却收到了 序号为1的数据包,只好返回ACK。
- 如果反馈的ACK又损坏了,会一直重复上面这两步。
rdt 2.2
如果不发送NAK,而是对上次正确接收的分组发送一个ACK,我们也能实现同样的效果。
发送方接收到对一个分组的两个ACK(冗余ACK)后,就知道接收方没有正确接收到跟在确认两次的分组后面的分组。
rdt 2.1和rdt 2.2的区别在于,接收方此时必须实现一种 包含分组序号的ACK报文。即rdt 2.2无NAK只有ACK。
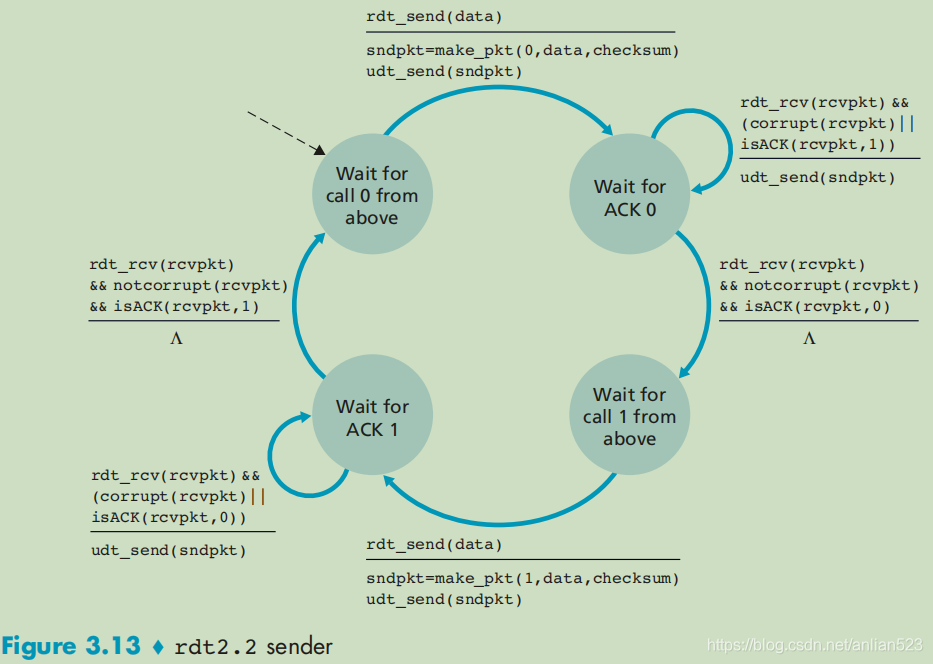
相比上一个版本,这个版本:发送方不需要去确认NAK了,转而将 (ACK,0) 和 (ACK,1) 分别对应到 上一个版本的ACK和NCK(在sender的不同状态机下,这两个元祖对应的情况可能会交换)。
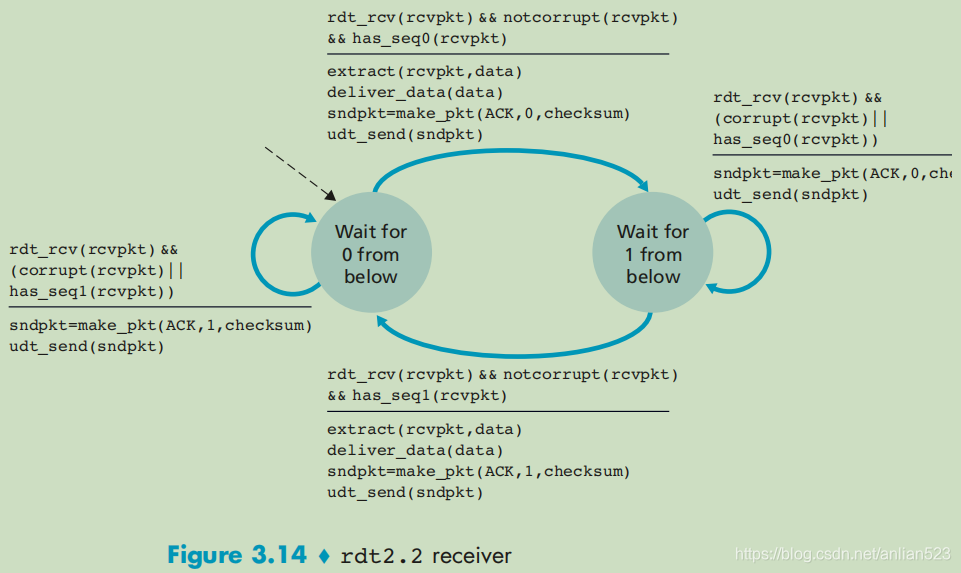
接收方把两种错误情况进行了合并:当收到损坏分组或不期待的分组时,都反馈ACK。且ACK带的序号为 接收方上一次接收分组的序号。
rdt 3.0
现在假设底层信道不仅可能使得分组受损,而且还会丢包。该版本引入了定时器。
考虑丢包的话,那么有三种情况:
- 发送方的 数据分组 丢了。
- 接收方的 ACK 丢了。
- 数据分组或ACK 经历了很长的时间才到达。(相当于丢了)
而定时器就解决了这些丢包的问题。
因为rdt 3.0的分组序号在0和1之间交替,因此rdt 3.0有时被称为比特交替协议(alternating-bit protocol)。
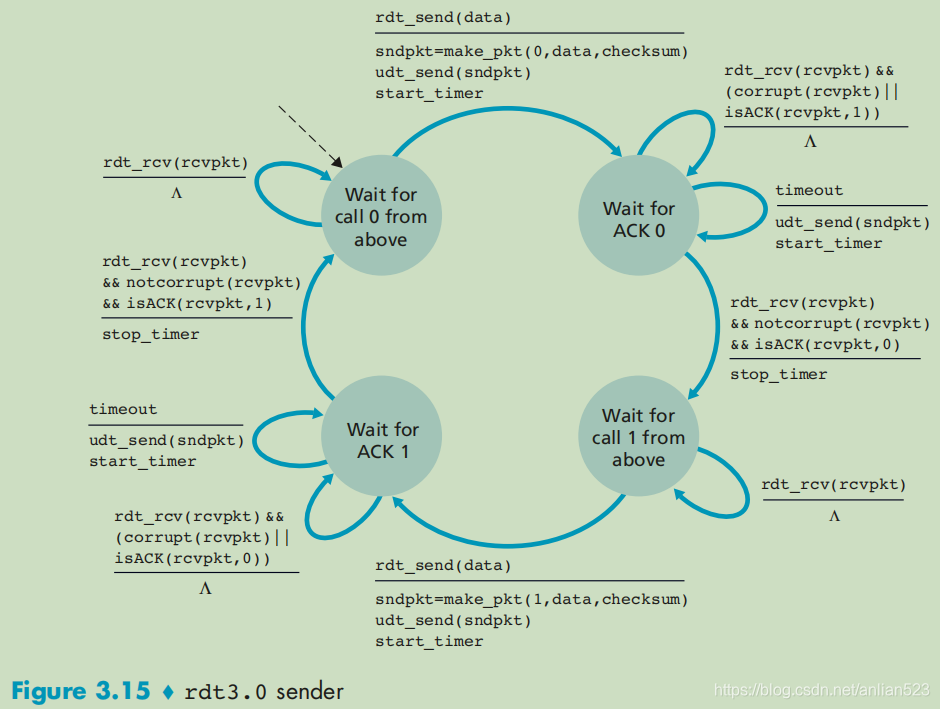
相比上一个版本,这个版本:
- 发送方在发现ACK损坏,或不是期待的ACK时,不会马上重新发送数据,而是等到定时器超时后才重新发送数据。(这一点看起来好像没啥用,却反而让接收方多等了一会,才得到想要的数据包)
- 在发送方收到了想要的ACK后,停止定时器,而不是上一个版本的什么也不做。
注意右下角的动作: r d t _ r c v ( r c v p k t ) ∧ \frac{rdt\_rcv(rcvpkt)}{\land} ∧rdt_rcv(rcvpkt)其实并不是新加的,上一个版本只是没有标注而已。当正在等待上层调用而非等待ACK时,如果收到ACK那么不会有任何动作,因为这是一个比特交替协议。(因为分组序号在0和1直接交替,因此rdt3.0有时被称为比特交替协议)
虽然接收方的状态机没有给出,但实际上它和上一个版本的接收方是一样的,因为所有的脏活累活都让发送方干了。
下图为比特交替协议的工作流程示例:
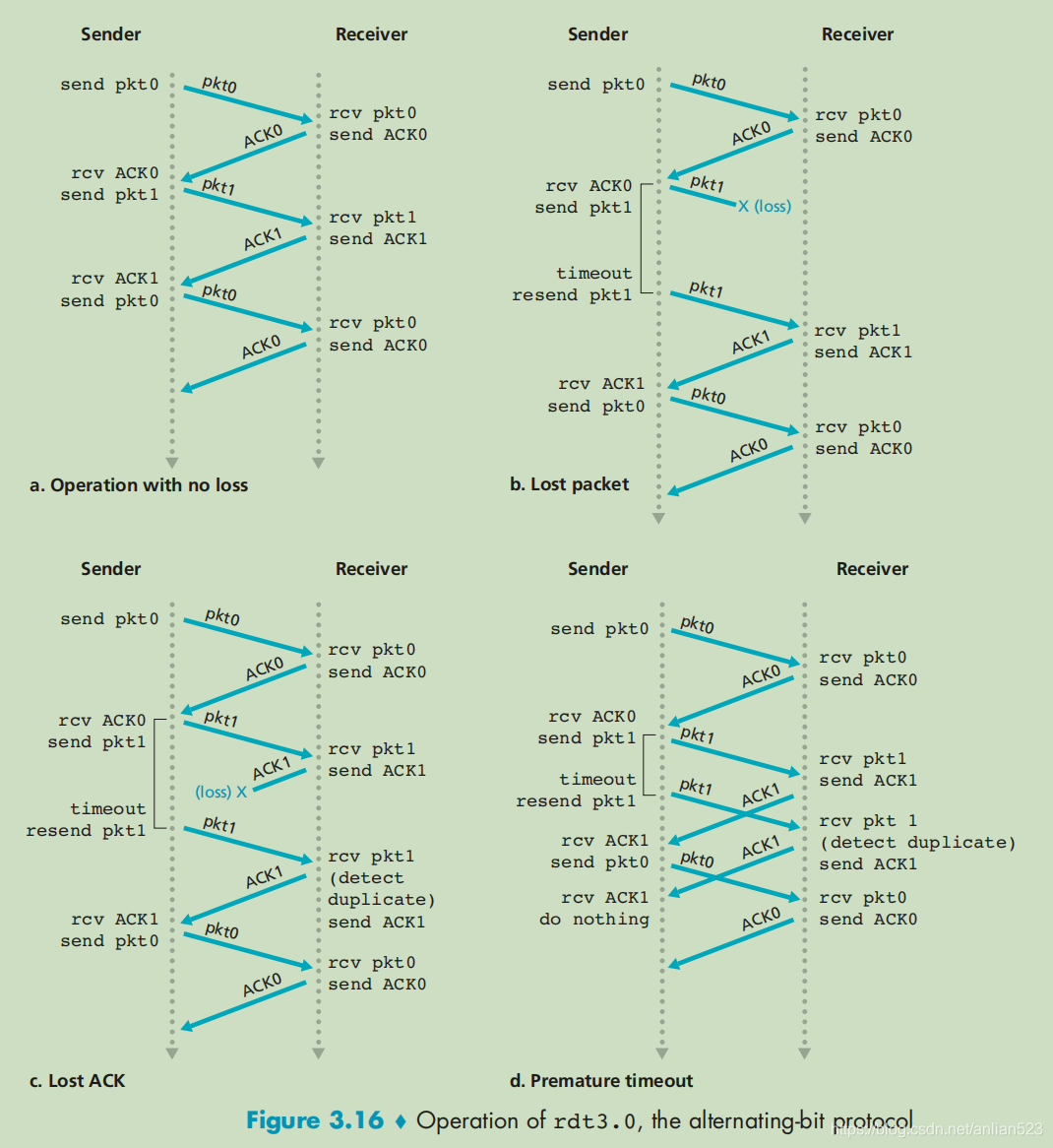
注意d情况是过早超时的情况。
流水线可靠数据传输协议
rdt 3.0的核心问题在于他是一个停等协议,这使得发送方的利用率(utilization)很低。
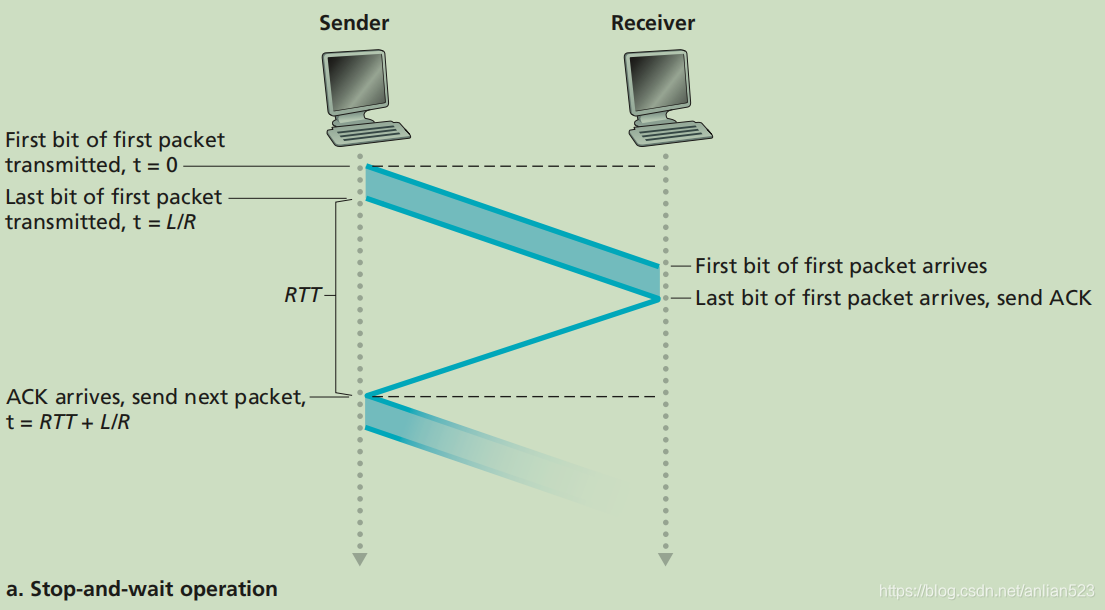
从上图可以看出,发送一个数据包假设为T,那么在T+RTT的时间内,只有T时间内发送方是忙碌的,大部分时间则是空闲的。
rdt 3.0 是一个功能正确的协议,但是由于它是一个停等协议,大部分的时间都浪费在等待确认上面,所以性能不好。解决这种特殊性能问题的一个简单的方法是:不使用停等方式运行,允许发送方发送多个分组而无需等待确认。这种技术被称为 流水线。
要使用流水线技术,则须:
- 增加序号范围,不能只有0和1。因为要连续传送多个分组,所以每个传输中的分组必须有一个单独的序号。
- 协议的发送方和接收方两端必须能缓存多个分组。发送方至少得能缓存那些已发送但未确认的分组(因为这些分组有可能需要被发送方重传),而接收方或许也需要缓存那些已经正确接收的分组(因为这些分组有可能暂时还不能交付给上层,当小序号的分组迟迟未到,而大序号的分组却先到了)。
- 所需序号的范围和对缓冲的要求取决于数据传输协议如何处理丢失、损坏及延时过大的分组。解决流水线的差错恢复有两种基本方法:回退 N 步(Go-Back-N, GBN )和选择重传(selective repeat,SR)。
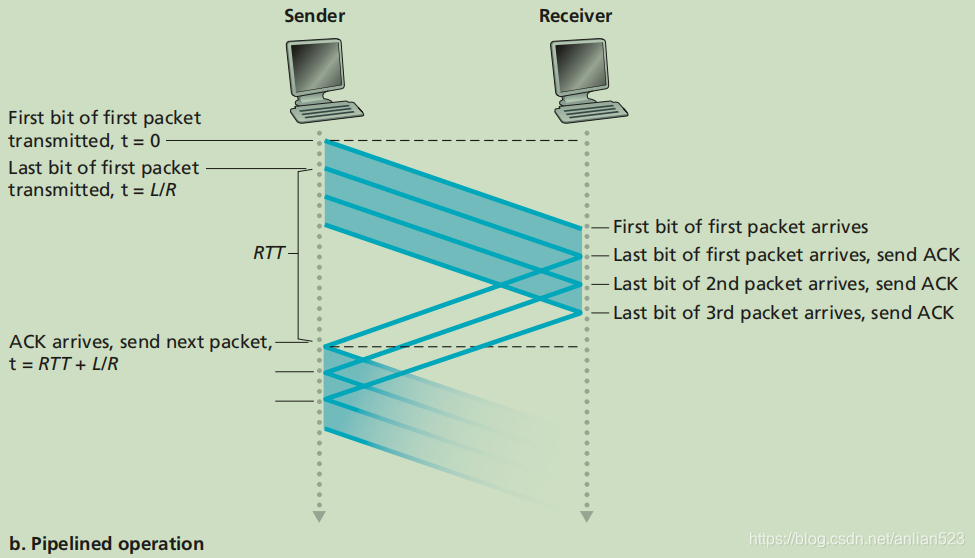
流水线工作流程如上。
GBN
在GBN中,允许发送方发送多个分组而无需等待ACK,但这样的已发送待确认的分组个数不能超过N。
- 发送方维护一个
N的大小的滑动窗口。 base为已发送待确认的最早的分组。nextseqnum为下一个即将被发送的分组将采用的序号(即最小的未使用序号)。
从下图可以马上得到:nextseqnum只能落在[base, base+N-1]这个范围里面。
这样我们把区间可以分为4段:
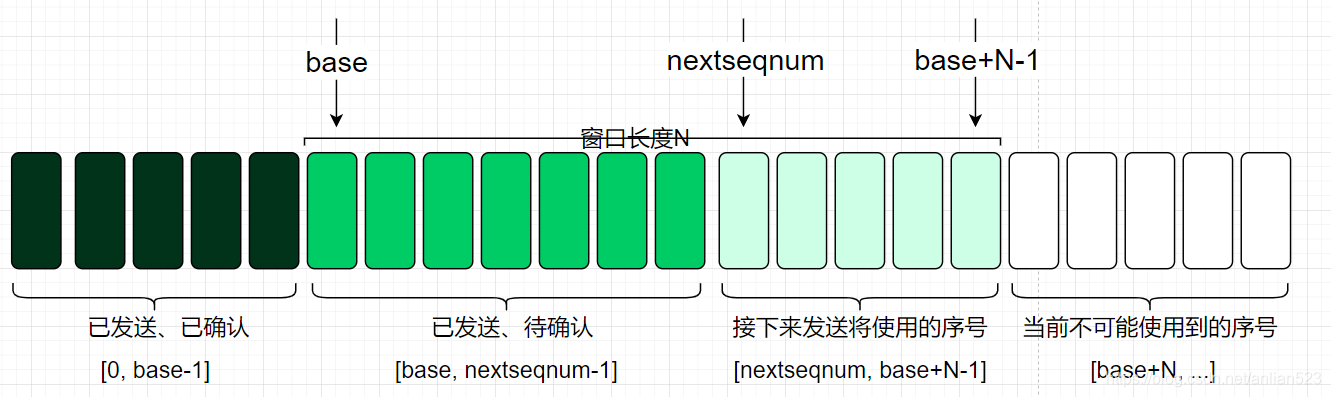
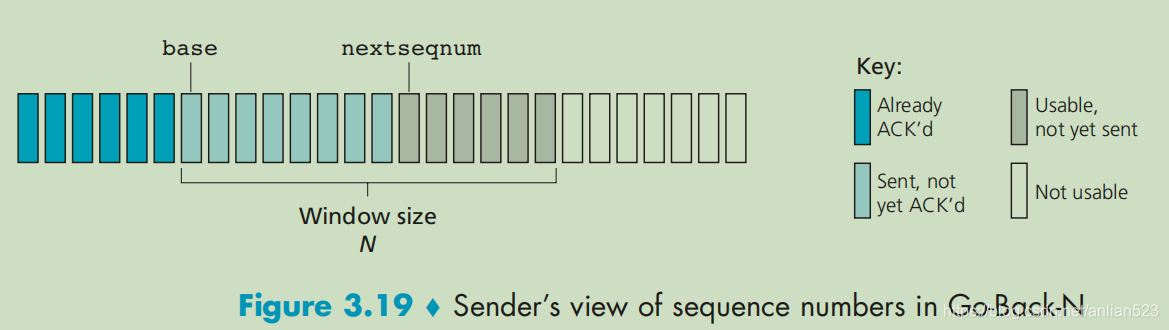
流量控制是需要限制窗口长度的原因之一。(TCP有一个32比特的序号字段,这个序号是按照字节流中的字节进行计数的,而不是按分组计数。当然这在本文不重要)
GBN发送方
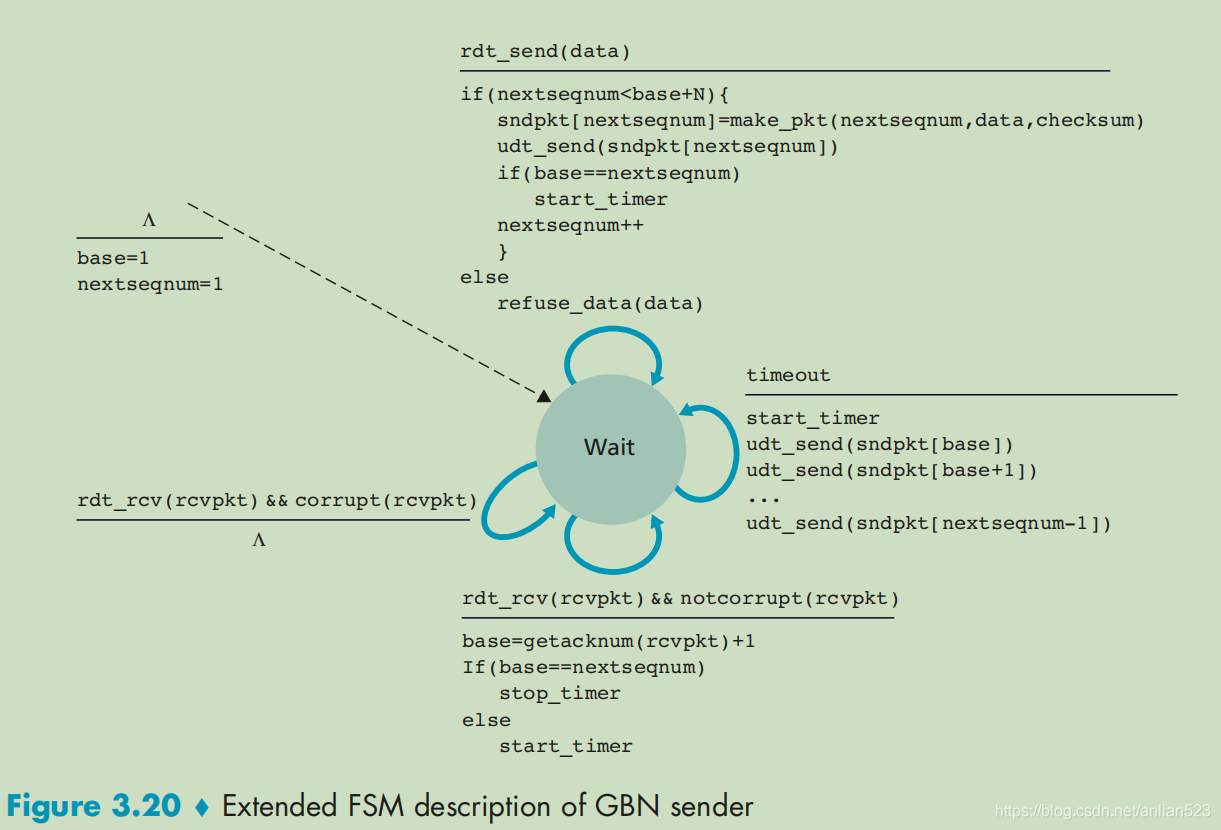
发送方需要响应的事件有:上层调用、收到ACK、超时事件。
rdt_send(data)//上层发送数据
-------------------------------------------------
if (nextseqnum<base+N) {
//每发送一个分组nextseqnum就会增加,但不可以超过窗口长度
sndpkt[nextseqnum]=make_pkt(nextseqnum,data,checksum)//发送前都要把分组给缓存起来
udt_send(sndpkt[nextseqnum])//发送缓存里的分组
if(base==nextseqnum)//如果发送的是窗口里的第一个分组,那么需要启动timer
start_timer
nextseqnum++//发送后,增加nextseqnum
}
else//当需要发送[base+N, ...)的序号分组时,则拒绝发送
refuse_data(data)
timeout//超时
-------------------------------------------------
start_timer//超时后,需要重新发送[base, nextseqnum-1]中的所有分组,即已发送但未确认的分组
udt_send(sndpkt[base])
udt_send(sndpkt[base+1])
...
udt_send(sndpkt[nextseqnum-1])
rdt_rcv(rcvpkt) && notcorrupt(rcvpkt)//收到了没有损坏的ACK
-------------------------------------------------
base=getacknum(rcvpkt)+1//base会更新为最小的已发送待确认分组序号
If(base==nextseqnum)//如果base追上了nextseqnum,即所有发送的分组,都已经被确认了
stop_timer//那么任务完成,停止timer
else//如果只是确认了某个分组,但还是有 待确认分组
start_timer//那么重启timer,以再次等待这么久的时间
上面的base=getacknum(rcvpkt)+1可能会有点奇怪,因为万一这个ACK所带的序号 指的是已发送、待确认区间的中间某个包的ACK,那滑动窗口就会跳过某些还没确认的包进行移动。
所幸GBN的接收方做了更多的事情:接收方反馈的(ACK, n)代表的是 接收方已正确收到了序号n以及n以前的所有分组(即[0, n])。也就是说,发送方收到的(ACK, n)代表的是累积确认。
GBN接收方
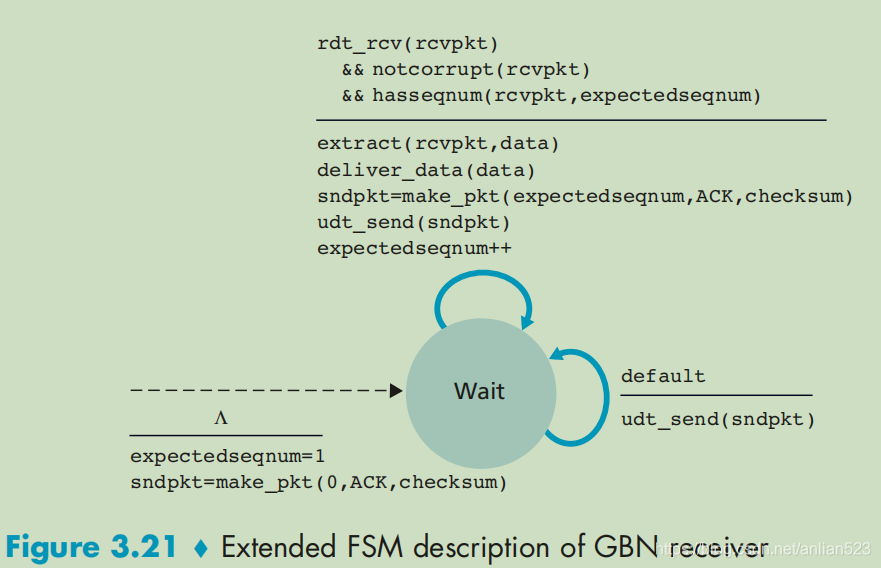
rdt_rcv(rcvpkt)
&& notcorrupt(rcvpkt)
&& hasseqnum(rcvpkt,expectedseqnum)
//接收方只期待expectedseqnum序号的分组,并不期待失序到达的分组(只要其序号不等于expectedseqnum,就代表其不被期待)
-------------------------------------------------
extract(rcvpkt,data)//向上层交付数据
deliver_data(data)
sndpkt=make_pkt(expectedseqnum,ACK,checksum)//根据expectedseqnum来创建新的ACK
udt_send(sndpkt)//发送新的ACK
expectedseqnum++//增加expectedseqnum
如果接收方收到了按序到达的分组,那么交付数据,反馈新的ACK。
default//收到失序到达的分组
-------------------------------------------------
udt_send(sndpkt)//发送上一次创建的ACK,即旧ACK
如果接收方收到了失序到达的分组,那么不交付数据,反馈旧的ACK。
这意味着GBN的接收方其实和rdt 3.0协议的接收方是一样的,永远只期待 当前所期待的序号。
- rdt 3.0协议的接收方只期待0或1(因为序号只在0和1之间交替)。
- GBN协议的接收方只期待expectedseqnum(expectedseqnum在一个范围内循环增长)。
- 这意味着GBN协议的接收方,其实没什么改进,只是期待的序号的范围不一样罢了。
GBN协议具体处理过程的示例
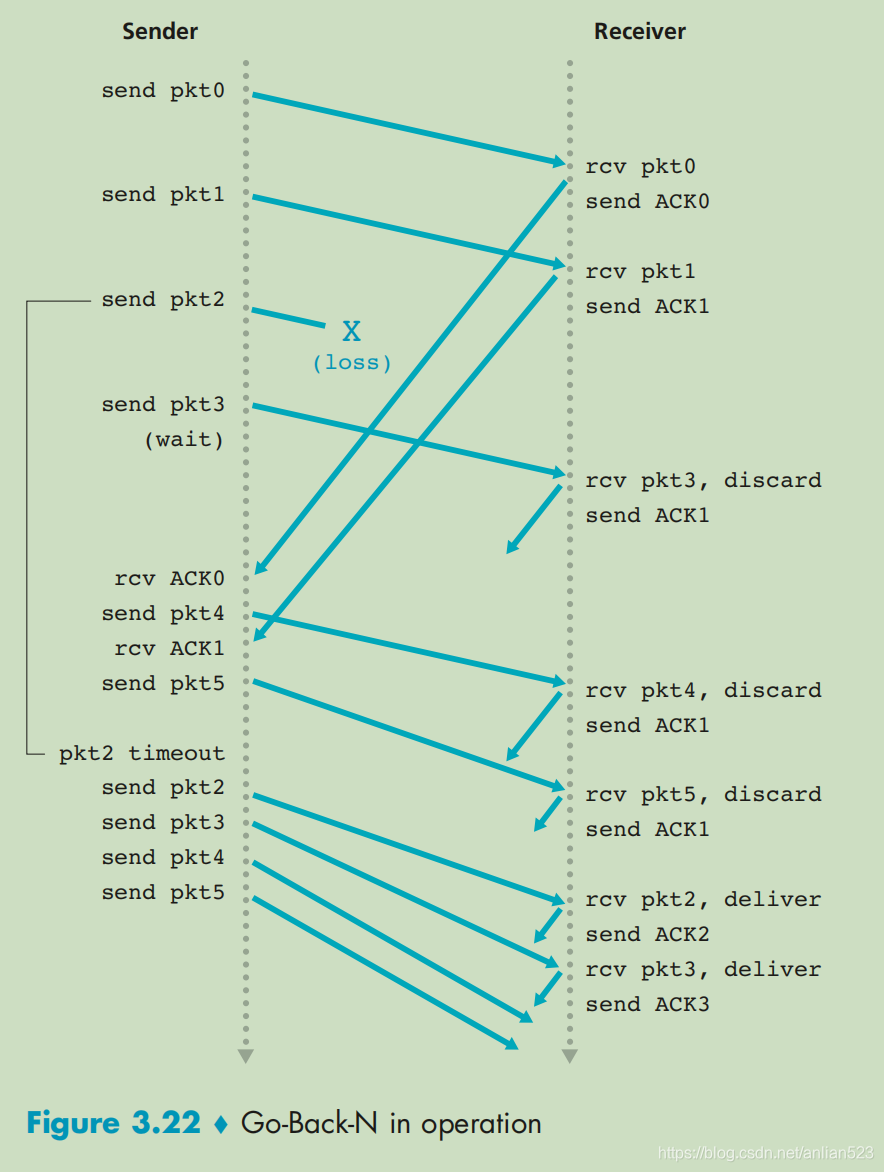
从上图可以看出,只是pkt2的丢失,导致2345都得重传。
SR
回退N步协议存在一个问题就是当窗口和带宽的时延都较大时,单个分组的差错可能会引起GBN重传大量的分组,然后许多本来不用重传的分组会充斥在信道中,造成资源浪费;选择重传就是让发送方仅重传那些丢失和受损的分组而避免不必要的重传。
注意SR协议中,反馈的ACK不再具有累积确认的意义。
SR协议中,接收方也需要维护一个接收窗口,并且需要缓存分组的能力。
注意本章的伪代码不是来自书中,而是本人根据理解写的。
SR发送方
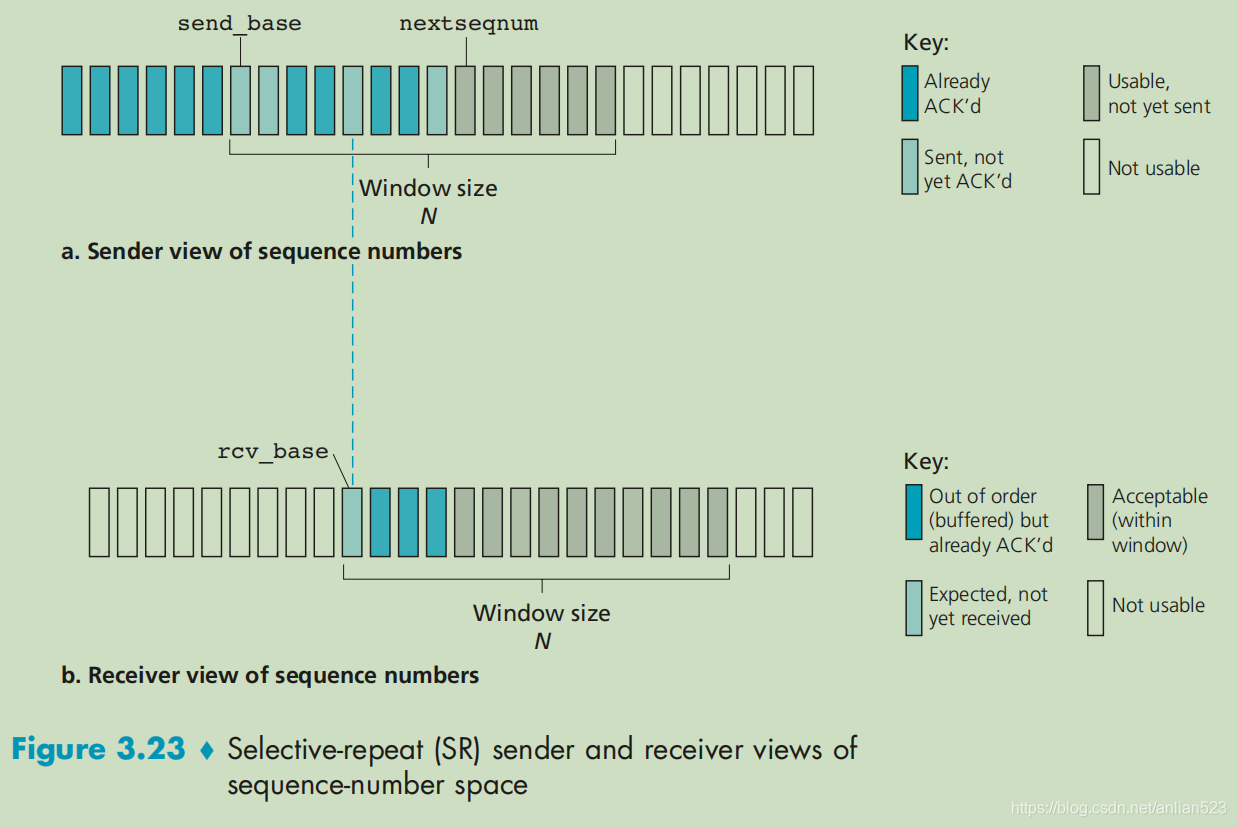
SR 发送方的事件和动作:

SR 发送方的事件和动作(伪代码形式):
- 从上层收到数据
rdt_send(data)//上层发送数据
-------------------------------------------------
if (nextseqnum < send_base+N) {
//每发送一个分组nextseqnum就会增加,但不可以超过窗口长度
sndpkt[nextseqnum]=make_pkt(nextseqnum,data,checksum)//发送前都要把分组给缓存起来
udt_send(sndpkt[nextseqnum])//发送缓存里的分组
start_timer(nextseqnum)//根据刚发送的分组序号,来启动对应的定时器
nextseqnum++//发送后,增加nextseqnum
}
else//当需要发送[base+N, ...)的序号分组时,则缓存起来。注意此时nextseqnum刚好等于send_base+N。
if [base+N, ...] not contain cache//如果滑动窗口外还没有缓存过 未发送分组
cacheSeqNum = nextseqnum//使用滑动窗口外的第一个序号
else//如果滑动窗口外已经缓存过 未发送分组
nothing//那么直接使用cacheSeqNum
sndpkt[cacheSeqNum]=make_pkt(cacheSeqNum,data,checksum)
cacheSeqNum++//缓存后,增加cacheSeqNum
与GBN的不同是:
- 根据不同序号启动对应的定时器。而不是当发送窗口内第一个分组时才启动定时器。
- 当需要发送滑动窗口所属序号以外的数据时,则把它缓存起来。而不是直接抛弃。
- 超时
ith-timer.timeout//第i个timer超时
-------------------------------------------------
start_timer(i)//超时后,需要重新发送这个已发送但未确认的分组
udt_send(sndpkt[i])
- 这段逻辑是针对于每个序号来说的。
- 响应到时事件后,还是会重启启动定时器,除非收到了对应的ACK,不然这个定时器会一直工作下去。
- 收到ACK
rdt_rcv(rcvpkt) && notcorrupt(rcvpkt) && rcvpkt.ackNum == i//收到了没有损坏的ACK,且ACK序号为i
-------------------------------------------------
if (i in [send_base, nextseqnum-1]) {
//如果i在 已发送待确认 的区间内
mark ith.pkt -> acknowledged//标记i序号 已发送待确认-> 已发送已确认
stop_timer(i)//停止对应的timer。(其实timer是否停止就可以当作上一句的标记)
if (send_base==i) {
//如果i刚好是窗口左边缘,那么需要移动窗口
moveForward(send_base)//这里等同于send_base++,send_base移动到 已发送待确认区间 的最新的左边缘
if ([nextseqnum, send_base+N-1] contain cache)//如果 待发送区间 包含 已缓存但未发送 的分组。按照这个伪代码,[nextseqnum, send_base+N-1]区间长度只能是1。
udt_send(sndpkt[nextseqnum, send_base+N-1])//还能发送这些分组
start_timer([nextseqnum, send_base+N-1])//启动这些定时器
}
}
else//其他情况
nothing//不做任何情况
- 停止序号对应的定时器。
- 移动 滑动窗口。
- 如果刚移动后,窗口内有 已缓存但未发送 的分组,那么发送它们,且启动它们的定时器。
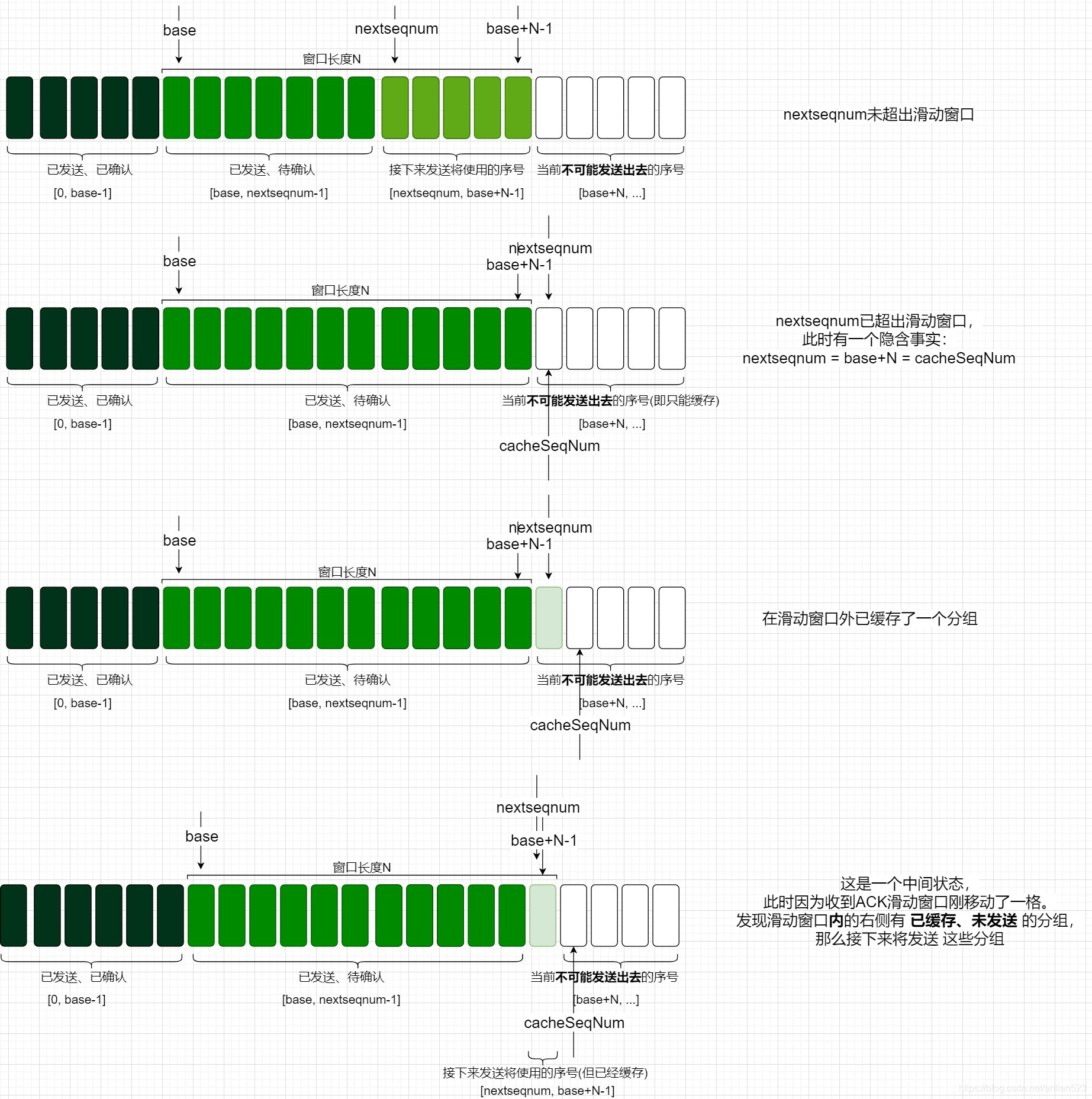
上图展示了一个经典过程:
- 滑动窗口内分为两个区间:已发送、待确认 和 即将发送、未缓存。
- 滑动窗口内只有一个区间:已发送、待确认。
- 滑动窗口内还是只有一个区间:已发送、待确认。但滑动窗口外 缓存了分组。
- 滑动窗口内分为两个区间:已发送、待确认 和 即将发送、已缓存。(这是一个中间状态,对应到伪代码
if ([nextseqnum, send_base+N-1] contain cache)) - 滑动窗口内只有一个区间:已发送、待确认。(此状态未在上图画出。在中间状态结束之后)
SR接收方
SR 接收方的事件和动作:

SR 接收方的事件和动作(伪代码形式):
- 序号在
[rcv_base, rcv_base + N - 1]内的分组被正确接收 - 序号在
[rcv_base - N, rcv_base - 1]内的分组被正确接收
rdt_rcv(rcvpkt)
&& notcorrupt(rcvpkt)
&& rcvpkt.ackNum == i
-------------------------------------------------
if(i in [rcv_base, rcv_base + N -1]) {
sndpkt=make_pkt(i,ACK,checksum)//收到哪个序号,就返回哪个序号的ACK
udt_send(sndpkt)//发送该ACK
if (rcvpkt[i] == null) //如果以前没有收到过,则缓存起来
rcvpkt[i] = 收到的rcvpkt
if (i == rcv_base) {
find continuous_last_id//找到从rcv_base开始的,连续的,已缓存的,最后的分组id。可能就是rcv_base自己
extract(rcvpkt[rcv_base, continuous_last_id],data)
deliver_data(data)
rcv_base = continuous_last_id + 1
} else {
//其他情况是,数据是处于窗口之中,但是数据的序号却不是窗口左边界。
//这些数据就属于是 失序到达的分组。
}
}
if(i in [rcv_base - N, rcv_base - 1]) {
//注意这个rcv_base往前的一个区间
sndpkt=make_pkt(i,ACK,checksum)//收到哪个序号,就返回哪个序号的ACK
udt_send(sndpkt)//发送该ACK
}
可以看到,接收方响应的区间的总长度刚好是2N。
- 其他情况
default//已经超过窗口的分组
-------------------------------------------------
nothing//什么也不做
SR协议具体处理过程的示例
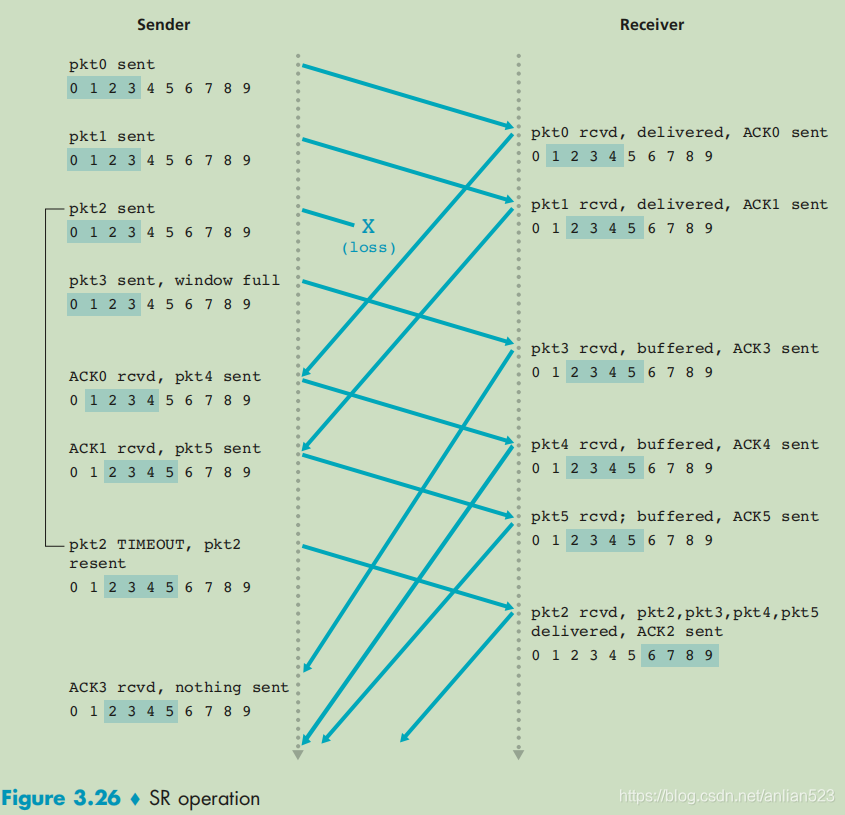
上图给出了发送方的pkt2丢包后,两方的具体处理过程。可以看到两方的滑动窗口并不一致,接收方的窗口总是移动地更快。
接收方情况简析
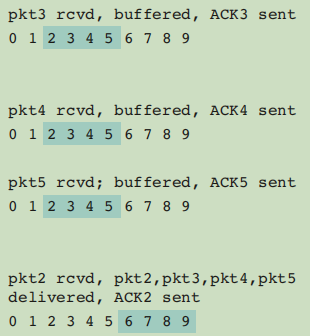
上面小图中(接收方),前三种情况,由于都不符合if (i == rcv_base)条件,所以接收方窗口没法移动,也就没法向上层交付数据。而最后一种情况,则符合了if (i == rcv_base)条件,所以就移动了窗口,且交付了数据给上层。
发送方情况简析
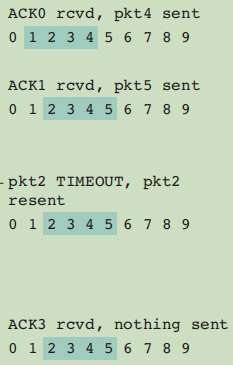
上面小图中(发送方),前两种情况,由于都符合了if (send_base==i)条件,所以就移动了发送方的窗口,且把新落到窗口内的数据也发送出去。而最后一种情况,由于不符合if (send_base==i)条件,也就没法移动窗口,也就不可能有数据新落到窗口内,所以也就没有东西可发。
接收方处理的区间长度为什么刚好是2N
这里可以解释一下,为什么接收方处理的区间长度刚好是2N:
-
因为极限情况下,接收方的窗口会刚好完全领先于发送方的窗口。
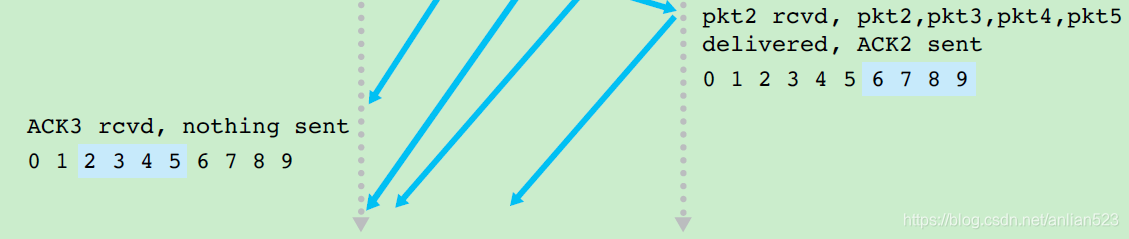
如上图,发送方窗口内为[2 3 4 5],而接收方窗口内为[6 7 8 9]。但接收方窗口只可能刚好领先发送方窗口,而不可能中间隔了序号。因为发送方只会发送自己窗口内的序号,极限情况下,发送方窗口内的分组全部被接收方接受到,但这些分组的ACK还都没有反馈给发送方。 -
在如上情况下,接收方给的
[2 3 4 5]的ACK如果丢失了,那么发送方还会重新发送[2 3 4 5]的分组的(响应定时器的到时事件)。那么接收方必须响应[2 3 4 5]并反馈ACK,以使得发送方的窗口向前移动。 -
综上,接收方之所以只处理
[rcv_base, rcv_base + N - 1]区间(即滑动窗口)和[rcv_base - N, rcv_base - 1]区间,是因为极限情况下接收方都只需要处理这两个区间。
窗口长度与序号空间大小
错误的窗口长度,会导致接收方不能正常工作。
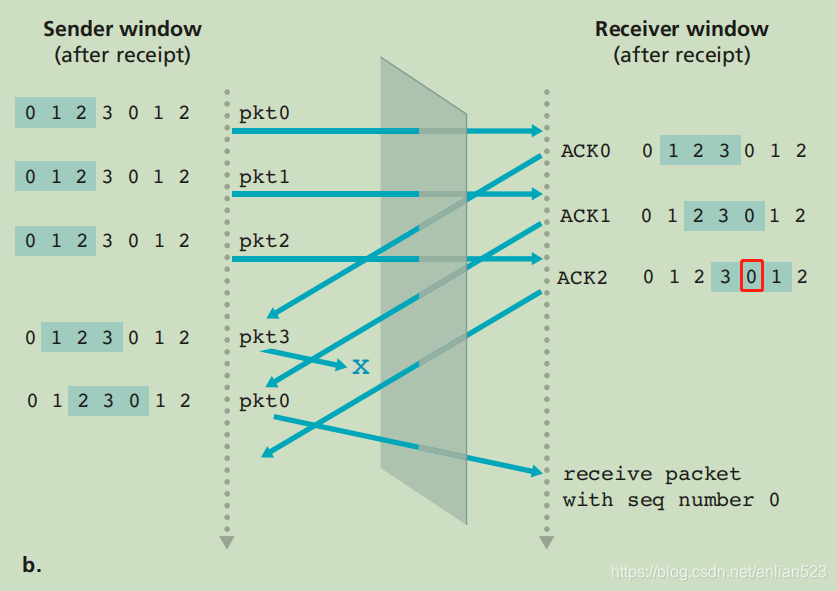
上图是一种正常情况:看最下面那个箭头,当接收方收到这个seqnum为0的pkt时,可以将红框内的0标记为已收到。

[3]是窗口内的 期待、但未收到 的分组。[0]是窗口内的 已缓存、未交付 的分组(即失序到达的分组)。[1]也是窗口内的 期待、但未收到 的分组。
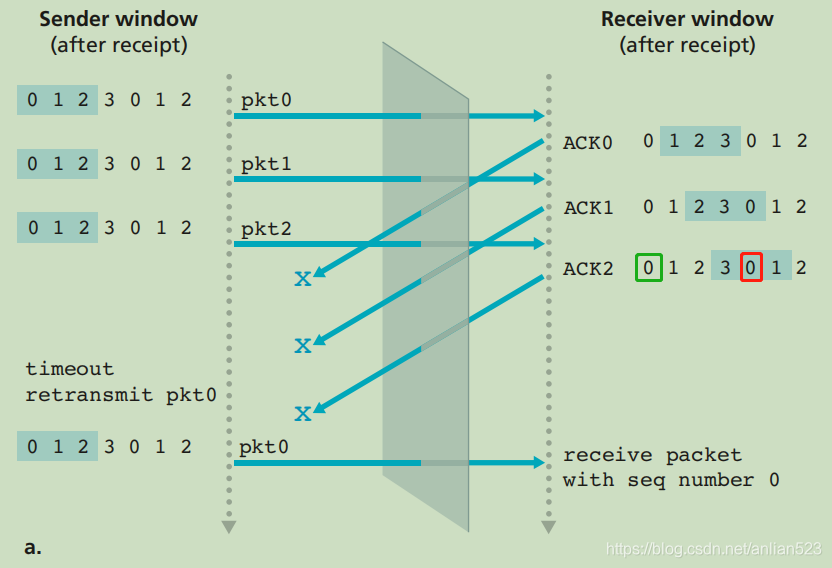
上图则是一种错误发生时的情况:还是看最下面那个箭头,当接收方收到这个seqnum为0的pkt时,不可以将红框内的0标记为已收到,因为这个pkt实际是指绿框内的0。但实际上,在这样的窗口长度与序号空间大小下,接收方并不能区分出,这个pkt到底是红框内的0还是绿框内的0。所以,窗口长度的设计很重要。
总之结论是,窗口长度必须小于或等于序号空间大小的一半。再看上面的例子,窗口长度是3,而序号空间[0 1 2 3]的长度为4,这样的组合就会出错了。
分组重新排序
之前所有的讨论都建立在“分组在发送方和接收方之间的信道中不能被重新排序”的假设之上。但由于实际情况下 发送方和接收方之间不是单根物理线路,而是一个网络,所以分组排序是可能会发生的。
具体表现就是:一个具有序号或确认号x的分组的旧副本,可能会出现,即使发送方和接收方的窗口中都没有包含x。
由于序号空间是循环使用的,那么这种旧副本被收到后且刚好落在了窗口里,可能会导致错误发生。为了防止错误发生,做了如下处理:
The approach taken in practice is to ensure that a sequence number is not reused until the sender is “sure” that any previously sent packets with sequence number x are no longer in the network. This is done by assuming that a packet cannot “live” in the network for longer than some fixed maximum amount of time.
- 在发送方没有确信 之前发送的pkt.x已经不在网络中 之前,序号x不能被重新使用;
- 在发送方确信 之前发送的pkt.x已经不在网络中 之后,序号x才可以被重新使用(注意理解原文的not…until…)。
- 这是通过假设数据包在网络中“生存”的时间不能超过某个固定的最大时间量来完成的。在高速网络的TCP拓展中,最长的分组寿命被假定为大约3分钟。
可靠数据传输需要使用到的机制
