【转】本文转自:https://blog.csdn.net/qq_36148847/article/details/79167267
python 具有一些比较流行的解析库,例如 lxml , 使用的是 XPath 语法,是大众普遍认为的网页文本信息提取的爬虫利器之一。
一. 关于 XPath
XPath 是 XML路径语言(XML Path Language),支持 HTML,是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中查找节点的能力。Xpath 可以通过元素和属性进行导航,相比 正则表达式,它同样可以在 XML 文档中查询信息,甚至使用起来更加简单高效。
在使用它进行爬虫前,先认识一下 XPath 。这里的案列例子引荐 w3school。
在 XPath 中,有七种类型的节点:元素(element)、属性(attribute)、文本(text)、命名空间(namespace)、处理指令(processing-instruction)、注释(commnt)以及文档(根)节点(root)。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
对于一个 XML 文件( HTML 文件可以通过 etree.HTML()方法 转为这种格式) ,他的 DOM 树一般看起来会是下面这样的:
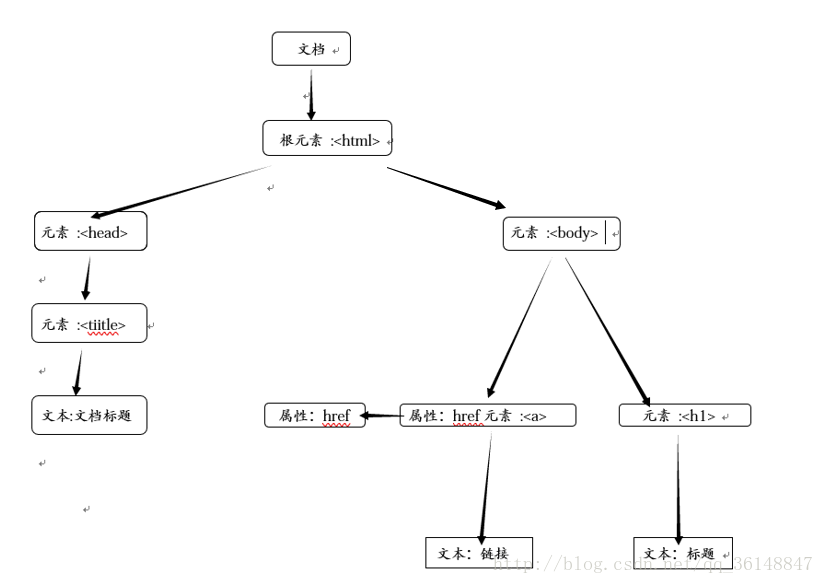
这是一个 XML 文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>1.节点关系
这里有节点 bookstore、 book、title、author、year、price。XML 文档本身就相当于数据结构树,这些节点层级结构看起来是像下面这样的:
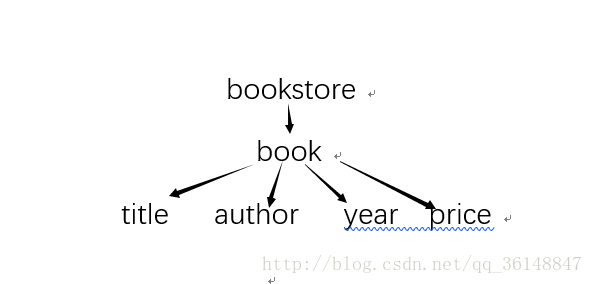
根据对树的概念,则有以下理解:
1. 父(Parent): bookstore 元素 为 book元素 的父;book 元素为 title、author、year 以及 price 元素 的父。
2. 子(Children):book 元素为 bookstore 元素的子;title、author、year 以及 price 元素为 book 元素的子。
3. 同胞(sibling):title、author、year 以及 price 元素都是同胞。
4. 先辈(Ancestor):title 元素的先辈是 book 元素和 bookstore 元素;其他 title 的同胞亦是如此。
5. 后代(Descendant):bookstore 的后代是 book、title、author、year 以及 price 元素;book 的后代为title、author、year 以及 price 元素。
2.如何获取节点信息?
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
下面为最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性 |
下面为根据上面所提到的案例 XML 文档编辑的路径表达式:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
3谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
继续使用上面 XML 文档例子,列出带有谓语的一些路径:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
4.选取未知节点
XPath 通配符 * 可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 配任何元素节点。 |
| @* | 配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
这是一个实例:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
5.选取若干路径
使用 | 运算符,实现选取若干个路径。
这是一个实例:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
6.XPath 轴
轴定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
7.位置路径表达式
绝对位置路径:/step/step/...
相对位置路径:step/step/...
其中,步(step) = 节点测试(node-test)+ 零个或更多谓语(predicate),语法为:轴名称::节点测试[谓语]
下面是一个梳实例:
| 实例 | 结果 |
|---|---|
| child::book | 选取所有属于当前节点的子元素的 book 节点。 |
| attribute::lang | 选取当前节点的 lang 属性。 |
| child::* | 选取当前节点的所有子元素。 |
| attribute::* | 选取当前节点的所有属性。 |
| child::text() | 选取当前节点的所有文本子节点。 |
| child::node() | 选取当前节点的所有子节点。 |
| descendant::book | 选取当前节点的所有 book 后代。 |
| ancestor::book | 选择当前节点的所有 book 先辈。 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| child::*/child::price | 选取当前节点的所有 price 孙节点。 |
8.XPath 运算符
下面为可用在 XPath 表达式中的运算符列表:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。 如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80。 | 如果 price 是9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。 如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。 如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
六、功能函数
使用功能函数能够更好的进行模糊搜索
| 函数 | 用法 | 解释 |
|---|---|---|
| starts-with | xpath(‘//div[starts-with(@id,”ma”)]‘) | 选取 id 值以 ma 开头的 div 节点 |
| contains | xpath(‘//div[contains(@id,”ma”)]‘) | 选取 id 值包含 ma 的 div 节点 |
| and | xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘) | 选取 id 值包含 ma 和 in 的 div 节点 |
| text() | xpath(‘//div[contains(text(),”ma”)]‘) | 选取节点文本包含 ma 的 div 节点 |
二. XPath 的运用
获取 XPath 的方式有两种:
- 观察找规律获取XPath
- 使用Chrome浏览器( 网页上击中目标数据,右击->选择审查元素(或者使用F12打开) 获取X Path 的标签,右击->Copy XPath)。
1.引用
提前确保已经安装好 lxml 库,通过 from lxml import etree 引用
2.解析文本方式
常用 HYML()方式 解析 html文件,lxml.etree 也提供了 fromstring() 解析字符串,XML()方法 解析XML对象 ,parse()方法 解析文件类型对象。
3.XPath 在 python 中的使用
在 Python 爬虫 中通过 lxml 库来使用 XPath 定位网页标签的数据。
这是一个使用 Model :
import requests
from lxml import etree
url = 'your url'
content = requests.get(url).content #获取 url 网页源码
html = etree.HTML(content)#将网页源码转换为 XPath 可以解析的格式
element =html.xpath('//*[class='class']/div/text()') #可能为列表或节点
print(element)
这是下面常用于测试的网页源码:
<!DOCTYPE html ">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<link rel="canonical" href="http://blog.csdn.net/qq_36148847" />
<meta http-equiv="Cache-Control" content="no-siteapp" />
<link rel="alternate" media="handheld" href="#" />
<meta name="shenma-site-verification" content="5a59773ab8077d4a62bf469ab966a63b_1497598848" />
<title>任世间混沌,独化蓝翅鸟 - CSDN博客</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<link rel="Stylesheet" type="text/css" href="http://static.blog.csdn.net/skin/skin-yellow/css/style.css?v=2.2" />
<link id="RSSLink" title="RSS" type="application/rss+xml" rel="alternate" href="/qq_36148847/rss/list" />
<link rel="shortcut icon" href="http://c.csdnimg.cn/public/favicon.ico" />
</head>
<body>
<div id="header">
<div class="header">
<div id="blog_title">
<h2>
<a href="http://blog.csdn.net/qq_36148847">任世间混沌,独化蓝翅鸟</a></h2>
<h3>我渴望听见世界的声音,如果可以,你能为我驻足吗?</h3>
</div>
</div>
</div>
<ul id="blog_rank">
<li>访问:<span>114次</span></li>
<li>积分:<span>71</span> </li>
<li >等级: <span style="position:relative;display:inline-block;z-index:1" >
<img src="http://c.csdnimg.cn/jifen/images/xunzhang/jianzhang/blog1.png" alt="" style="vertical-align: middle;" id="leveImg">
<div id="smallTittle" style=" position: absolute; left: -24px; top: 25px; text-align: center; width: 101px; height: 32px; background-color: #fff; line-height: 32px; border: 2px #DDDDDD solid; box-shadow: 0px 2px 2px rgba (0,0,0,0.1); display: none; z-index: 999;">
<div style="left: 42%; top: -8px; position: absolute; width: 0; height: 0; border-left: 10px solid transparent; border-right: 10px solid transparent; border-bottom: 8px solid #EAEAEA;"></div>
积分:71 </div>
</span> </li>
<li>排名:<span>千里之外</span></li>
</ul>
<ul id="blog_statistics">
<li>原创:<span>6篇</span></li>
<li>转载:<span>1篇</span></li>
<li>译文:<span>0篇</span></li>
<li>评论:<span>0条</span></li>
</ul>
<div id="panel_Category" class="panel">
<ul class="panel_head"><span>文章分类</span></ul>
<ul class="panel_body">
<li>
<a href="/qq_36148847/article/category/7415046" onclick="_gaq.push(['_trackEvent','function', 'onclick', 'blog_articles_wenzhangfenlei']); ">Algorithm</a><span>(1)</span>
</li>
<li>
<a href="/qq_36148847/article/category/7415349" onclick="_gaq.push(['_trackEvent','function', 'onclick', 'blog_articles_wenzhangfenlei']); ">operation</a><span>(1)</span>
</li>
<li>
<a href="/qq_36148847/article/category/7415629" onclick="_gaq.push(['_trackEvent','function', 'onclick', 'blog_articles_wenzhangfenlei']); ">language</a><span>(1)</span>
</li>
<li>
<a href="/qq_36148847/article/category/7416384" onclick="_gaq.push(['_trackEvent','function', 'onclick', 'blog_articles_wenzhangfenlei']); ">Linux</a><span>(1)</span>
</li>
<li>
<a href="/qq_36148847/article/category/7416385" onclick="_gaq.push(['_trackEvent','function', 'onclick', 'blog_articles_wenzhangfenlei']); ">命令行</a><span>(1)</span>
</li>
<li>
<a href="/qq_36148847/article/category/7416386" onclick="_gaq.push(['_trackEvent','function', 'onclick', 'blog_articles_wenzhangfenlei']); ">渗透测试</a><span>(1)</span>
</li>
</ul>
</div>
</body>
</html>
(1)属性 @ 定位
下面是一个实例:
selector = etree.HTML(html)
# 使用@属性定位
links = selector.xpath('//a/@href')
for link in links:
print(link) 输出:
/qq_36148847/article/category/7415046
/qq_36148847/article/category/7415349
/qq_36148847/article/category/7415629
/qq_36148847/article/category/7416384
/qq_36148847/article/category/7416385
/qq_36148847/article/category/7416386
(2) id 定位
下面是一个实例:
selector = etree.HTML(html)
# id定位提取文本
blog = selector.xpath('//ul[@id="blog_statistics"]/li/text()')
num = selector.xpath('//ul[@id="blog_statistics"]/li/span/text()')
for each in blog,num:
print(each)
输出:
['原创:', '转载:', '译文:', '评论:']
['6篇', '1篇', '0篇', '0条']
(3) 相对路径与绝对路径
下面是一个实例:
selector = etree.HTML(html)
#使用相对路径定位a标签的title
title1 = selector.xpath('//*[@id="blog_title"]/h2/a/text()')
#使用绝对路径定位a标签的title
title2 = selector.xpath('/html/body/div[@id="header"]/div[@class="header"]/div[@id="blog_title"]/h2/a/text()')
print(title1)
print(title2)
输出:
['任世间混沌,独化蓝翅鸟']
['任世间混沌,独化蓝翅鸟']
(4) XPath 与表格
下面为表格的实例网页源码:
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
<table bgcolor="#C5D7ED" cellpadding="6" cellspacing="1" width="100%">
<thead><tr align="center" bgcolor="#F1F7FC">
<th>产品</th>
<th>最低价</th>
<th>平均价</th>
<th>最高价</th>
<th>规格</th>
<th class="mds">日期</th>
</tr></thead>
<tbody>
<tr align="center" bgcolor="#FFFFFF"><td>黄心菜</td><td>0.50元/斤</td><td><b class="f_red">0.75元/斤</b></td><td>1.00元/斤</td><td>普通</td><td class="mds">2018-01-26</td></tr>
<tr align="center" bgcolor="#FFFFFF"><td>大头菜</td><td>0.40元/斤</td><td><b class="f_red">0.50元/斤</b></td><td>0.60元/斤</td><td>普通</td><td class="mds">2018-01-26<td></tr>
<tr align="center" bgcolor="#FFFFFF"><td><a href="http://www.114guoshu.com/pifa/qincai/" target="_blank"><strong class="keylink">芹菜</strong></a></td><td>0.70元/斤</td><td><b class="f_red">0.80元/斤</b></td><td>0.90元/斤</td><td>普通</td><td class="mds">2018-01-26</td><td></tr>
</tbody>
</table>下面为一个实例:
from lxml import etree
html = etree.HTML(html)
table = html.xpath("//tr[td]")
table1 = html.xpath('*/table/tbody/tr/td/text()')
print(table1)
print("---- 我是分割线 ---- ")
for row in table:
table2= [i for i in row.itertext()]
print(table2)
输出:
['黄心菜', '0.50元/斤', '1.00元/斤', '普通', '2018-01-26', '大头菜', '0.40元/斤', '0.60元/斤', '普通', '2018-01-26', '0.70元/斤', '0.90元/斤', '普通', '2018-01-26']
---- 我是分割线 ----
['黄心菜', '0.50元/斤', '0.75元/斤', '1.00元/斤', '普通', '2018-01-26']
['大头菜', '0.40元/斤', '0.50元/斤', '0.60元/斤', '普通', '2018-01-26']
['芹菜', '0.70元/斤', '0.80元/斤', '0.90元/斤', '普通', '2018-01-26']
介绍XPath的特殊用法:
(1) starts-with 解决标签属性值以相同字符串开头的情况
下面为一个实例:
from lxml import etree
html='''
<body>
<div id="aa">I'm aa</div>
<div id="ab">I'm ab</div>
<div id="ac">I'm ac</div>
</body>
'''
selector=etree.HTML(html)
content=selector.xpath('//div[starts-with(@id,"a")]/text()') # starts-with 方法提取 id 标签属性值开头为 a 的 div 标签
for each in content:
print(each)
输出:
I'm aa
I'm ab
I'm ac
(2) string(.) 的使用
下面是一个实例:
#浅谈 string() 的使用
#2) string(.) 标签套标签
selector = etree.HTML(html)
title = selector.xpath('//*[@id="blog_title"]/h3/text()')#这是一个列表 list
#//*[@id="blog_title"]/h3
print(title)
print(" ------ 我是分割线 ------ ")
data=selector.xpath('//div[@id="header"]')[0]#这是一个列表 list
print(data)# 输出标签
info=data.xpath('string(.)')#输出此枝干下的所有文本内容
print(info)
输出:
['我渴望听见世界的声音,如果可以,你能为我驻足吗?']
------ 我是分割线 ------
<Element div at 0x2888d564d88>
任世间混沌,独化蓝翅鸟
我渴望听见世界的声音,如果可以,你能为我驻足吗?