2019-06-13
1< scrapy的安装
命令行安装
pip install scrapy
<常见错误是缺少 wim32api
安装win32api
pip install pywin32
<还有就是twisted没有安装
到链接找到对应的版本下载安装
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

命令行打开输入pip install 把文件拖进来就OK了
2<scrapy基础
scrapy优点:
- 提供了内置的HTTP缓存,以加速本地开发
- 童工了自动节流调节机制,而且具有遵守robots.txt的内置的能力
- 可以定义爬行深度的限制,以避免爬虫进入死循环链接
- 会自动保留会话
- 执行自动HTTP基本认证,不需要明确保存状态
- 可以自动填写登入表单
- scrapy有一个内置的中间件,可以自动设置请求中的引用头referrer
- 支持通过3XX响应重定向,也可以通过HTML元刷新
- 避免被网站使用的<noscript>meta重定向困住,以检测没有JS支持的页面
- 默认使用CSS选择器或者Xpath编写解析器
- 可以通过Splash或任何其他技术Selenium呈现JavaScript页面
- 拥有强的社区支持和丰富的插件和扩展来扩展其功能
- 提供了通用的蜘蛛来抓取常见的格式,站点地图CSV和XML
- 内置支持以多种格式(JSON,CSV,XML,JSON-lines)导出收集的数据并储存在多个后端FTP S3 本地文件系统中
Scrapy 架构
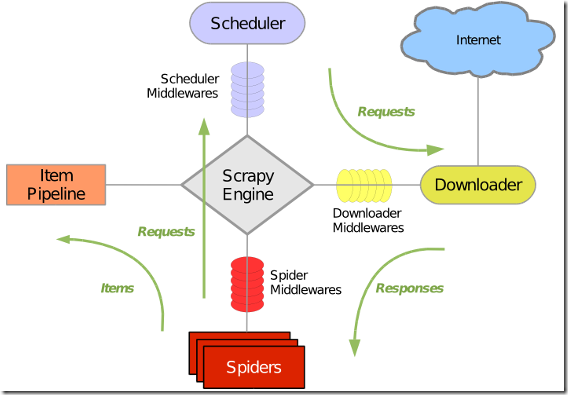
Scrapy 执行过程
1 引擎打开一个网站 open a domain 找到处理该网站的Spider并向该Spider请求第一个爬取的URL
2 引擎从Spider中获取第一个要爬取的URL并在调度器Scheduler中以Request调度
3 引擎向调度器请求下一个要爬取的URL
4 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件请求request方向转发给下载器
5 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回Response方向)发送给引擎
6 引擎从下在其中接收Response并通过Spider中间件(输入方向)发送给Spider处理
7 Spider处理Response并返回爬取到的Item及(跟进的新的Request给引擎
8 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将Spider返回的Request给调度器
9 从第2步 重复知道调度器中没有更多的Request,引擎关闭对该网站的执行进程
3<scrapy使用
scarpy 使用命令操作
创建一个scrapy工程
scrapy startproject <your-project-name> # 例如 创建一个名为first_spider工程 scrapy startproject first_spider
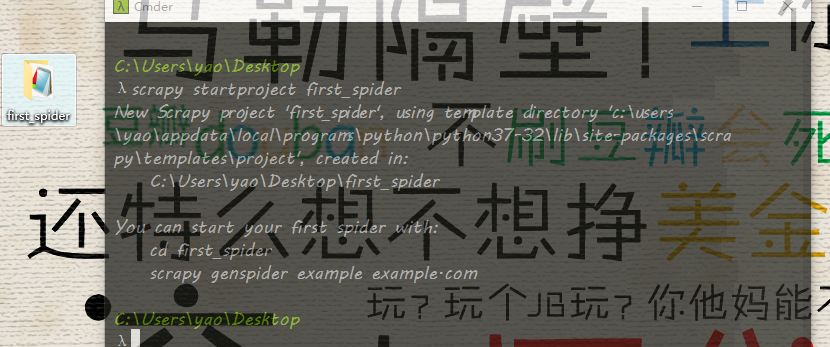
所在的目录就创建了一个first_spider的目录
我们看一下这个目录的结构
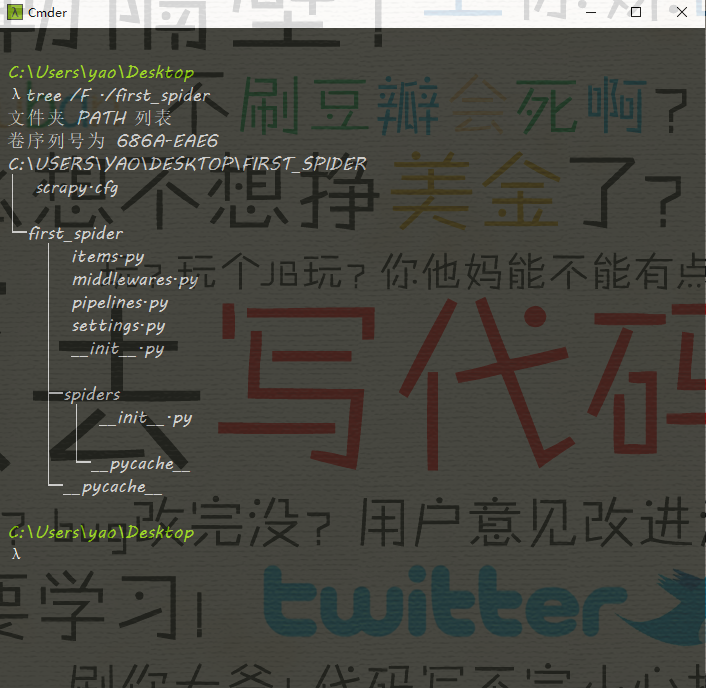
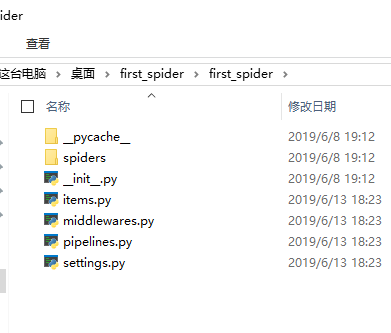
- __init__.py #包定义
- items.py #模型定义
- pipeline.py #管道定义
- settings.py #配置文件
- spiders #蜘蛛文件夹
- __init__.py #默认的蜘蛛代码文件
- scrapy,py #Scrapy的运行配置文件
创建一个scrapy工程