一、关键词自动标注
1、关键词
关键词是指能够反映文本语料主题的词语或短语,是快速了解文档内容、把握主题的重要方式。
2、概述
关键词自动标注大概可以分为两大类,一为关键词分配,另一个为关键词提取。
关键词分配是从一个预先构建好的受控词表中推荐若干个词或者短语分配给文档作为关键词。
关键词提取是从文档内容中寻找并推荐关键词,而没有指定的词库。
3、关键词提取
关键词提取一般分为两个步骤,一是生成关键词候选表,二是采用算法选择关键词。
(1)生成关键词候选表
1)去除停用词
2)只提取指定词性的词,如,名词、形容词、动词等
3)其他规则筛选等
(2)算法选用
现有的算法根据是否依赖外部知识库,大致可以分为两大类:一是依赖外部知识库,如:TF-IDF等;二是不依赖外部知识库,如:Textrank等。
此外还有监督方法,将关键词抽取转为序列标注,或基于神经网络的方法等。
4、TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或者或一个语料库中的其中一份文件的重要程度。
字词的重要随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
(1)原理
词频,即TF,指的是某一个给定的词语在该文件中出现的次数,通常进行归一化。
逆向文档频率,即IDF,是一个词语普遍重要性的度量,通常由总文件数目除以包含该词语的文件数目得到的商取对数得到。
实际上可以将IDF看成一个重要性的调整参数,在词频的基础上,对每一个词分配一个重要性度量,最常见的词给与小权重,而最不常见的词给与大的权重,最后将词频与权重相乘得到某个词对文章的重要性度量。
5、TextRank
TextRank算法是基于GOOGLE的提出的pageRank算法改进而来,详细可以参考我的另一篇博文:pageRank
(1)原理
TextRank与pageRank不同之处,在于权重系数的增加:
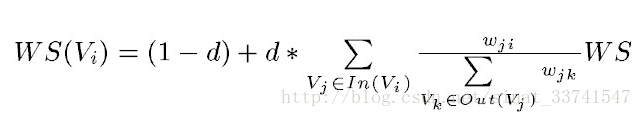
(2)权重系数
在经过处理构造出候选关键词后,得到候选关键词表T = [C1, C2, C3…CN]
对于关键词表构建长度为K的窗口,当两个词A和B在该窗口中同时出现时,认为当前两个节点有关联,在pageRank中就是两个网页间有超链接跳转,对所有的词进行统计之后归一化,就得到权重系数,这也称为共现关系。
之后进行迭代计算,就得到关键词选项了。
二、自动摘要
自动摘要与关键词自动标注类似,是从文章中自动抽取出关键句。
1、概述
自动摘要主要分为两大类,一种是抽取式,即直接从文章存在的句子中抽取出最重要的几句作为关键句;另一种是生成式,这种方法在实现难度上远高于前者,在理解文章语义的基础上重新概括生成文本。
一般采用的都是抽取式方法进行自动摘要。
2、应用
自动文摘与关键词自动标注一样可以采用TextRank进行抽取,唯一不同的是权值的计算方式,这里可以用句子之间的相似性进行替代。
在自动摘要中,对文档进行断句,分词等预处理后,得到每个句子的词列表。之后可以使用文档相似度算法,如BM25等进行计算,得出的相似度作为权值进行迭代计算,最后得到评分最高的句子。
关于TF-IDF和TextRank算法,在python的jieba包中都有算法实现。