1、赛题信息
提交地址:https://challenge.xfyun.cn/topic/info?type=abstract-of-the-paper&ch=ymfk4uU
项目题目:
- 基于论文摘要的文本分类与关键词抽取挑战赛算法挑战大赛
- 关键词提取:根据摘要生成关键词
- 文本分类:判断是否为医学


2、解决方案
提供模型:
- 数学和词频统计:tfidf+逻辑回归
- 机器学习训练:bert版
- 大模型微调: chatglm+lora
运行环境
- Python 3.10.12
- 根目录的requirements.txt或docx/.yaml的conda导出
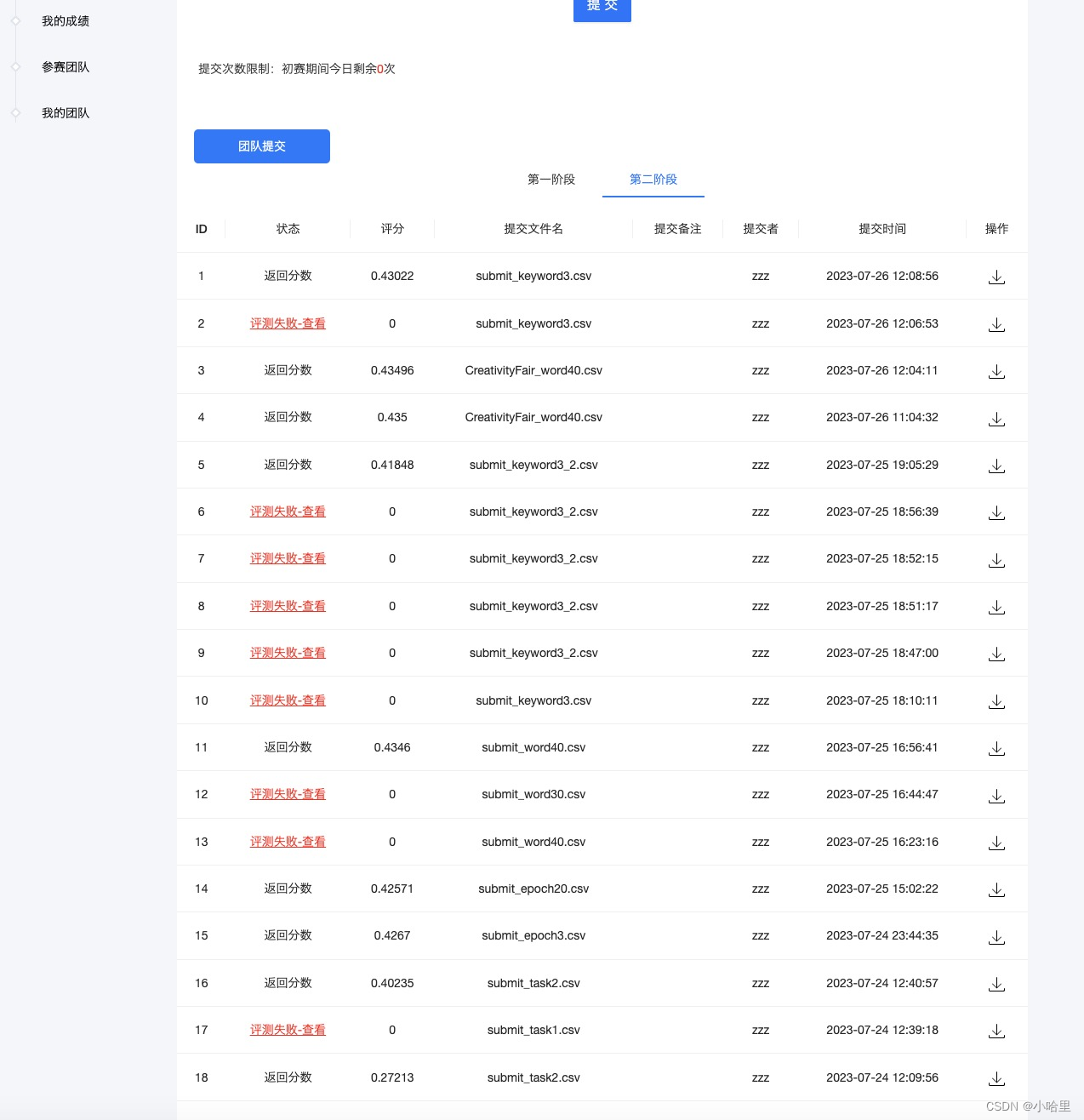
最后成绩
- RK17,1200队报名,121队提交,17/121 = 14%左右。
- 分数:0.435
task1用微调的GLM大模型+bert补充。
task2用纯bert跑3轮。
2.1 飞桨Baseline(提供代码)
- 快速跑通全流程,我们基于百度AI Studio,将本教程Baseline部署在线上平台,可一键fork运行代码,提交结果,看到成绩。
- 没啥好说的,一键运行就成,AIStudio就可以跑。
- 本地m1pro大概10秒内可以跑出来。
- 其实实际分数只有0.2左右,因为主办方A榜的数据给多了,关键词的结果直接给出来了,所以一模一样放上去自然大家都是0.9x,感觉没啥参考价值。
- 提交后获得假成绩。

基于论文摘要的文本分类与关键词抽取挑战赛
https://challenge.xfyun.cn/topic/info?type=abstract-of-the-paper&ch=ZuoaKcY
#%% md
## 3. 赛题解析
实践任务
本任务分为两个子任务:
1. 从论文标题、摘要作者等信息,判断该论文是否属于医学领域的文献。
2. 从论文标题、摘要作者等信息,提取出该论文关键词。
第一个任务看作是一个文本二分类任务。机器需要根据对论文摘要等信息的理解,将论文划分为医学领域的文献和非医学领域的文献两个类别之一。第二个任务看作是一个文本关键词识别任务。机器需要从给定的论文中识别和提取出与论文内容相关的关键词。
数据集解析
训练集与测试集数据为CSV格式文件,各字段分别是标题、作者和摘要。Keywords为任务2的标签,label为任务1的标签。训练集和测试集都可以通过pandas读取。
## 4.实践思路&baseline
### 实践思路
本赛题可以分为两个子任务:
1. 从论文标题、摘要作者等信息,判断该论文是否属于医学领域的文献。
2. 从论文标题、摘要作者等信息,提取出该论文关键词。
#### 任务一:文本二分类
第一个任务看作是一个文本二分类任务。机器需要根据对论文摘要等信息的理解,将论文划分为医学领域的文献和非医学领域的文献两个类别之一。
针对文本分类任务,可以提供两种实践思路,一种是使用传统的特征提取方法(如TF-IDF/BOW)结合机器学习模型,另一种是使用预训练的BERT模型进行建模。使用特征提取 + 机器学习的思路步骤如下:
1. 数据预处理:首先,对文本数据进行预处理,包括文本清洗(如去除特殊字符、标点符号)、分词等操作。可以使用常见的NLP工具包(如NLTK或spaCy)来辅助进行预处理。
2. 特征提取:使用TF-IDF(词频-逆文档频率)或BOW(词袋模型)方法将文本转换为向量表示。TF-IDF可以计算文本中词语的重要性,而BOW则简单地统计每个词语在文本中的出现次数。可以使用scikit-learn库的TfidfVectorizer或CountVectorizer来实现特征提取。
3. 构建训练集和测试集:将预处理后的文本数据分割为训练集和测试集,确保数据集的样本分布均匀。
4. 选择机器学习模型:根据实际情况选择适合的机器学习模型,如朴素贝叶斯、支持向量机(SVM)、随机森林等。这些模型在文本分类任务中表现良好。可以使用scikit-learn库中相应的分类器进行模型训练和评估。
5. 模型训练和评估:使用训练集对选定的机器学习模型进行训练,然后使用测试集进行评估。评估指标可以选择准确率、精确率、召回率、F1值等。
6. 调参优化:如果模型效果不理想,可以尝试调整特征提取的参数(如词频阈值、词袋大小等)或机器学习模型的参数,以获得更好的性能。
Baseline中我们选择使用BOW将文本转换为向量表示,选择逻辑回归模型来完成训练和评估
代码演示如下:
# 获取前置依赖
!pip install nltk
# 导入pandas用于读取表格数据
import pandas as pd
# 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import CountVectorizer
# 导入LogisticRegression回归模型
from sklearn.linear_model import LogisticRegression
# 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
# 读取数据集
train = pd.read_csv('data/train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('data/test.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
# 提取文本特征,生成训练集与测试集
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])
# 引入模型
model = LogisticRegression()
# 开始训练,这里可以考虑修改默认的batch_size与epoch来取得更好的效果
model.fit(train_vector, train['label'])
# 利用模型对测试集label标签进行预测
test['label'] = model.predict(test_vector)
# 生成任务一推测结果
test[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)
#### 任务二:关键词提取
论文关键词划分为两类:
- 在标题和摘要中出现的关键词
- 没有在标题和摘要中出的关键词
在标题和摘要中出现的关键词:这些关键词是文本的核心内容,通常在文章的标题和摘要中出现,用于概括和提炼文本的主题或要点。对于提取这类关键词,可以采用以下方法:
- 词频统计:统计标题和摘要中的词频,选择出现频率较高的词语作为关键词。同时设置停用词去掉价值不大、有负作用的词语。
- 词性过滤:根据文本的词性信息,筛选出名词、动词、形容词等词性的词语作为关键词。
- TF-IDF算法:计算词语在文本中的词频和逆文档频率,选择TF-IDF值较高的词语作为关键词。
没有在标题和摘要中出现的关键词:这类关键词可能在文本的正文部分出现,但并没有在标题和摘要中提及。要提取这些关键词,可以考虑以下方法:
- 文本聚类:将文本划分为不同的主题或类别,提取每个主题下的关键词。
- 上下文分析:通过分析关键词周围的上下文信息,判断其重要性和相关性。
- 基于机器学习/深度学习的方法:使用监督学习或无监督学习的方法训练模型,从文本中提取出未出现在标题和摘要中的关键词。
# 引入分词器
from nltk import word_tokenize, ngrams
# 定义停用词,去掉出现较多,但对文章不关键的词语
stops = [
'will', 'can', "couldn't", 'same', 'own', "needn't", 'between', "shan't", 'very',
'so', 'over', 'in', 'have', 'the', 's', 'didn', 'few', 'should', 'of', 'that',
'don', 'weren', 'into', "mustn't", 'other', 'from', "she's", 'hasn', "you're",
'ain', 'ours', 'them', 'he', 'hers', 'up', 'below', 'won', 'out', 'through',
'than', 'this', 'who', "you've", 'on', 'how', 'more', 'being', 'any', 'no',
'mightn', 'for', 'again', 'nor', 'there', 'him', 'was', 'y', 'too', 'now',
'whom', 'an', 've', 'or', 'itself', 'is', 'all', "hasn't", 'been', 'themselves',
'wouldn', 'its', 'had', "should've", 'it', "you'll", 'are', 'be', 'when', "hadn't",
"that'll", 'what', 'while', 'above', 'such', 'we', 't', 'my', 'd', 'i', 'me',
'at', 'after', 'am', 'against', 'further', 'just', 'isn', 'haven', 'down',
"isn't", "wouldn't", 'some', "didn't", 'ourselves', 'their', 'theirs', 'both',
're', 'her', 'ma', 'before', "don't", 'having', 'where', 'shouldn', 'under',
'if', 'as', 'myself', 'needn', 'these', 'you', 'with', 'yourself', 'those',
'each', 'herself', 'off', 'to', 'not', 'm', "it's", 'does', "weren't", "aren't",
'were', 'aren', 'by', 'doesn', 'himself', 'wasn', "you'd", 'once', 'because', 'yours',
'has', "mightn't", 'they', 'll', "haven't", 'but', 'couldn', 'a', 'do', 'hadn',
"doesn't", 'your', 'she', 'yourselves', 'o', 'our', 'here', 'and', 'his', 'most',
'about', 'shan', "wasn't", 'then', 'only', 'mustn', 'doing', 'during', 'why',
"won't", 'until', 'did', "shouldn't", 'which'
]
# 定义方法按照词频筛选关键词
def extract_keywords_by_freq(title, abstract):
ngrams_count = list(ngrams(word_tokenize(title.lower()), 2)) + list(ngrams(word_tokenize(abstract.lower()), 2))
ngrams_count = pd.DataFrame(ngrams_count)
ngrams_count = ngrams_count[~ngrams_count[0].isin(stops)]
ngrams_count = ngrams_count[~ngrams_count[1].isin(stops)]
ngrams_count = ngrams_count[ngrams_count[0].apply(len) > 3]
ngrams_count = ngrams_count[ngrams_count[1].apply(len) > 3]
ngrams_count['phrase'] = ngrams_count[0] + ' ' + ngrams_count[1]
ngrams_count = ngrams_count['phrase'].value_counts()
ngrams_count = ngrams_count[ngrams_count > 1]
return list(ngrams_count.index)[:6]
## 对测试集提取关键词
test_words = []
for row in test.iterrows():
# 读取第每一行数据的标题与摘要并提取关键词
prediction_keywords = extract_keywords_by_freq(row[1].title, row[1].abstract)
# 利用文章标题进一步提取关键词
prediction_keywords = [x.title() for x in prediction_keywords]
# 如果未能提取到关键词
if len(prediction_keywords) == 0:
prediction_keywords = ['A', 'B']
test_words.append('; '.join(prediction_keywords))
test['Keywords'] = test_words
test[['uuid', 'Keywords', 'label']].to_csv('submit_task2.csv', index=None)
完整baseline运行后a榜分数在0.97655左右
2.2 Bert和调参
-
百度飞桨无法使用torch,阿里云天池和谷歌Kaggle均无法联网从huggingface获得bert模型。
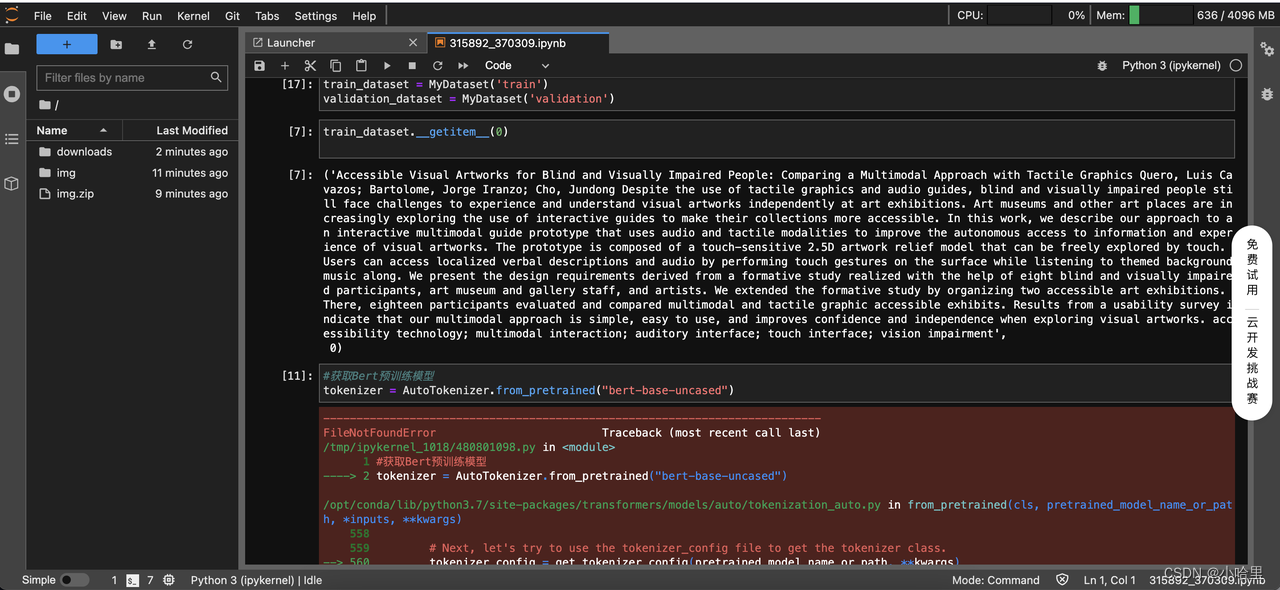
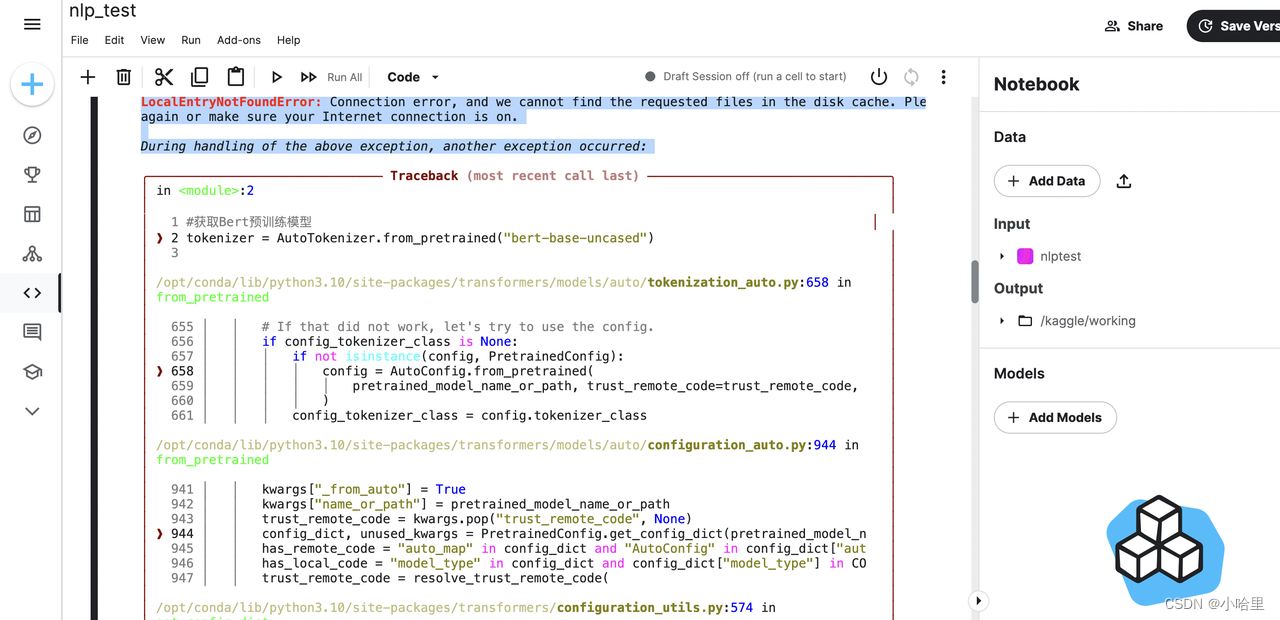
-
最后使用Google Colab,手动安装transfrom后成功运行。不得不提,colab网速是真的快,100-200Mb/s。

-
本地也安装对应环境也可以跑,修改Epoch为1后,成功运行获得结果
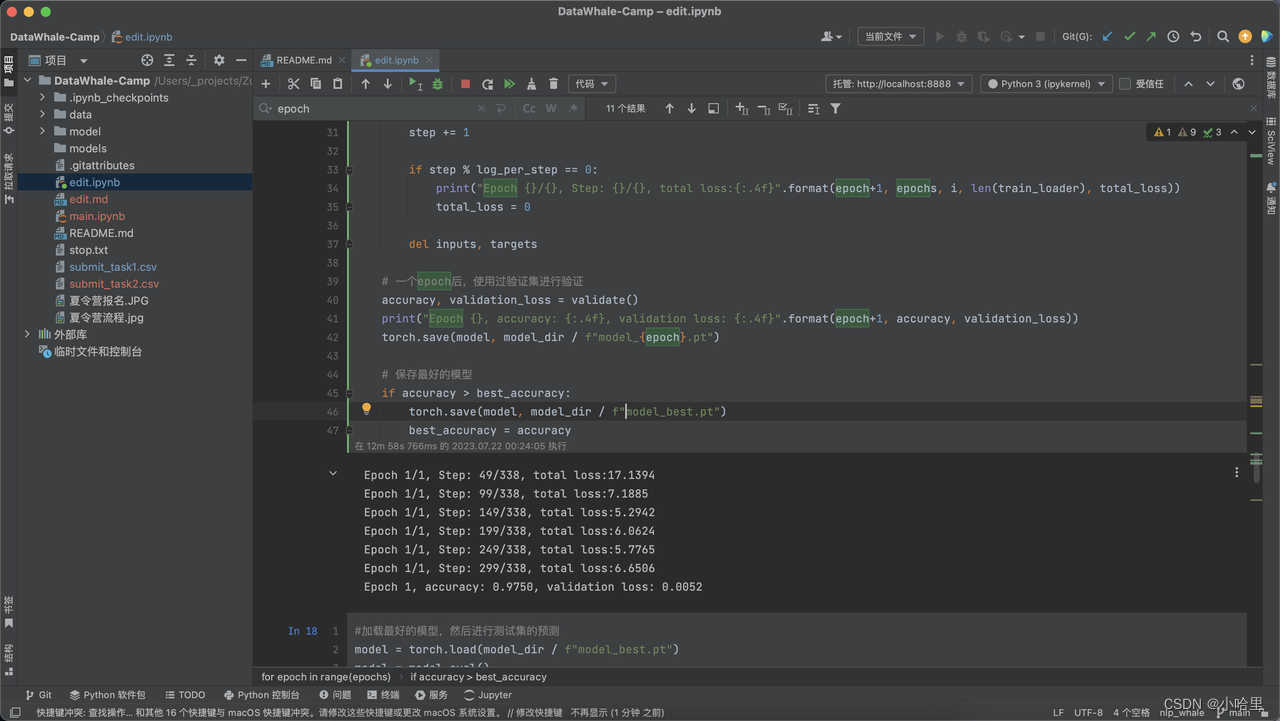
-
使用m1pro运行36+18分钟,得到3轮epoch的bert,提交获得分数0.42670。
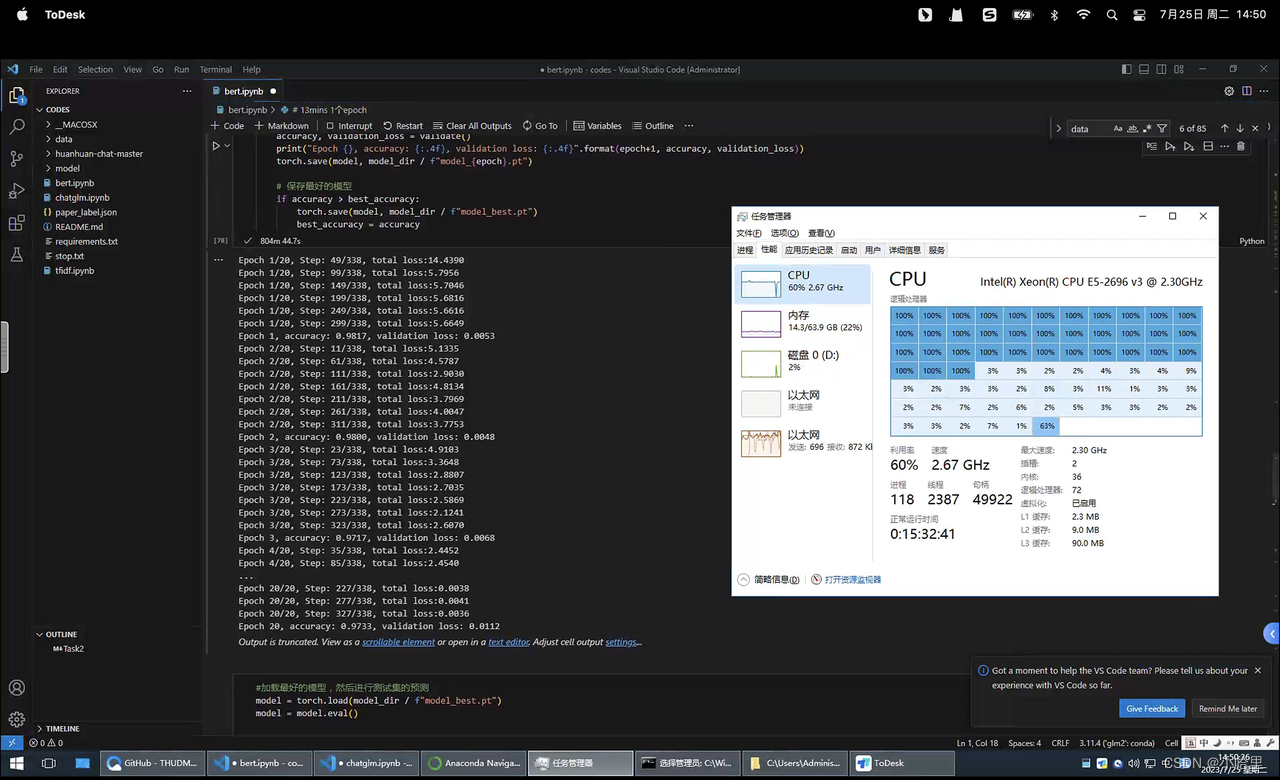
-
租了个服务器E5,36核72线程,使用10轮epoch进行运行。

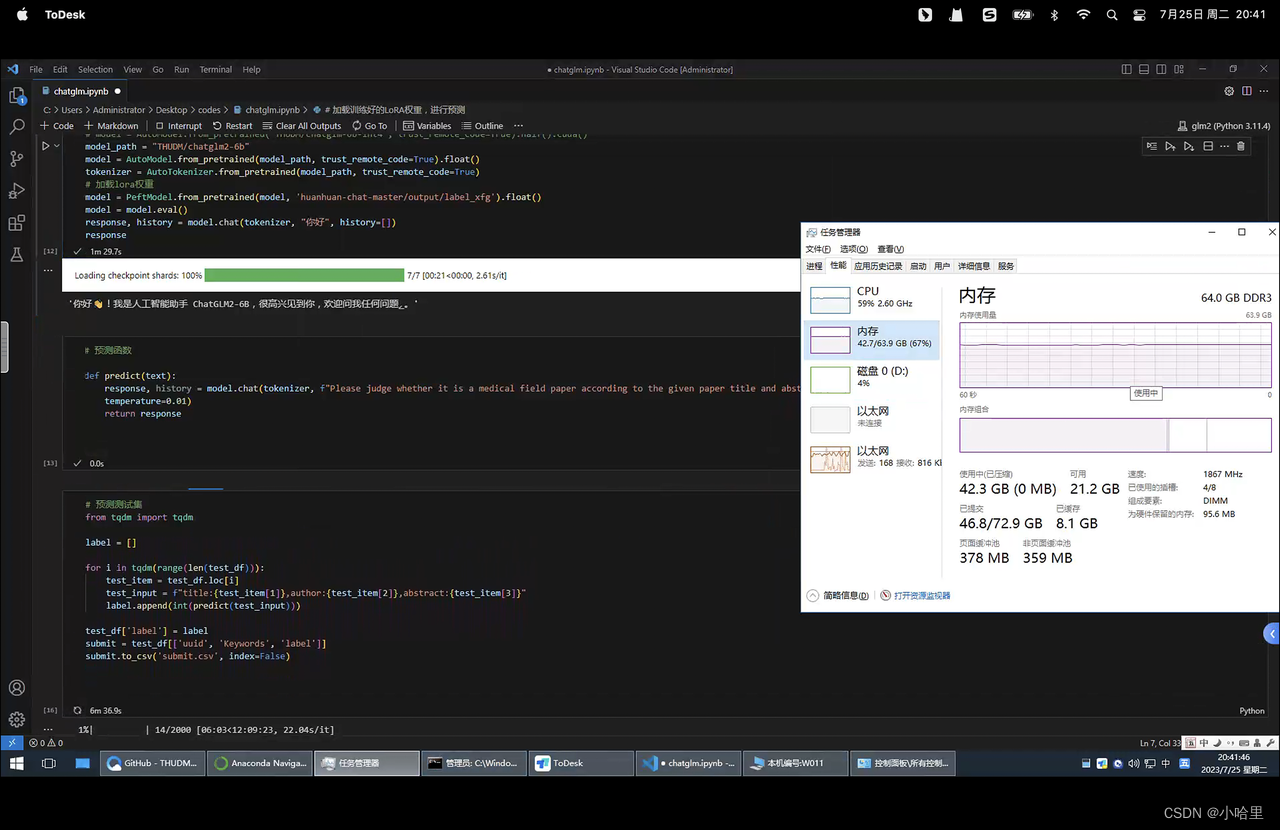
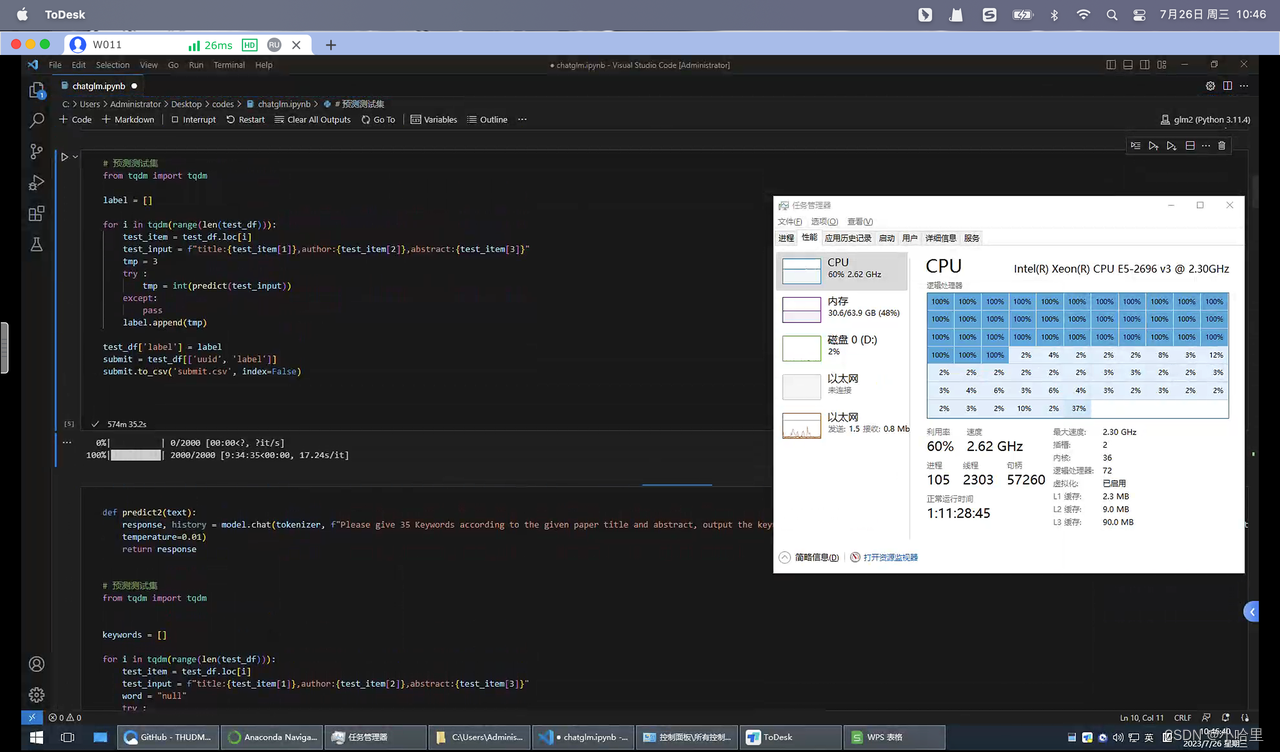
2.3 chatGLM+lora大模型
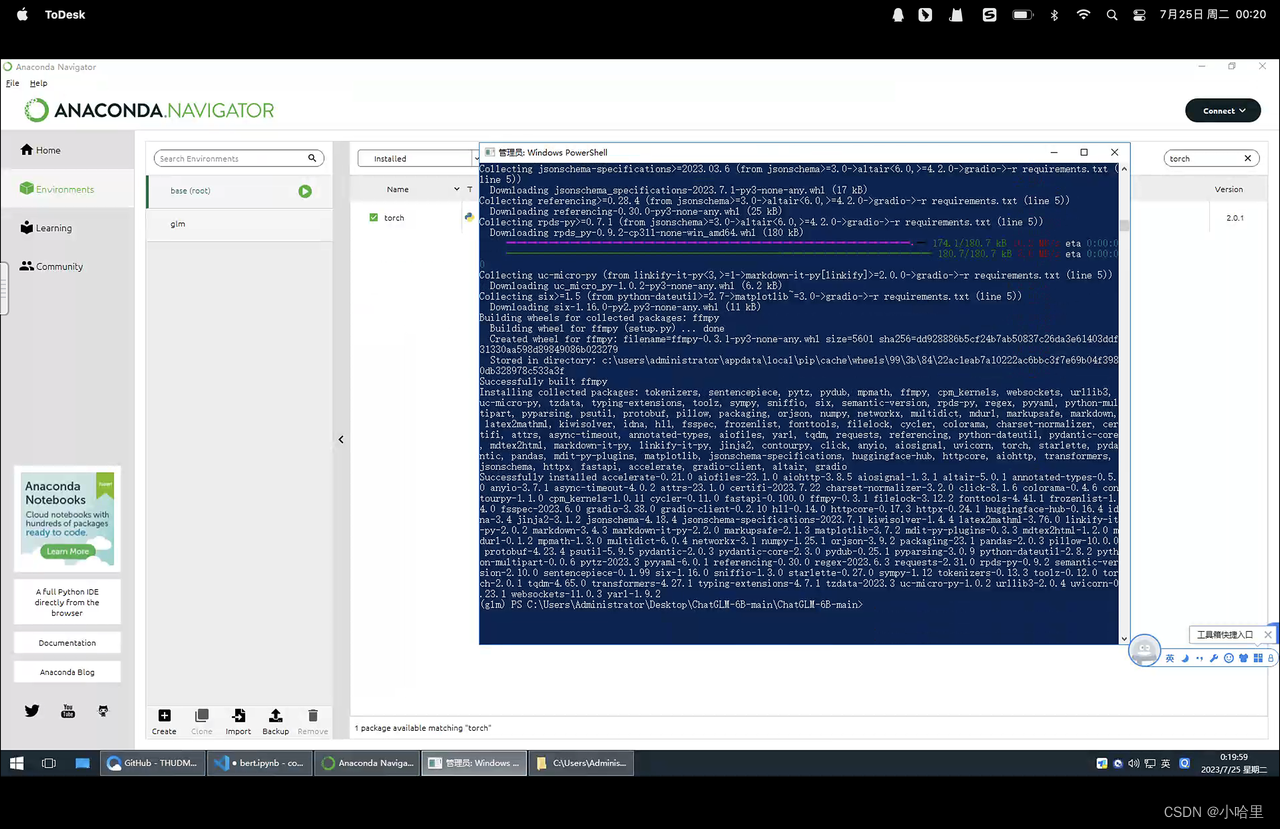
-
搭建GLM环境 微调脚本下载
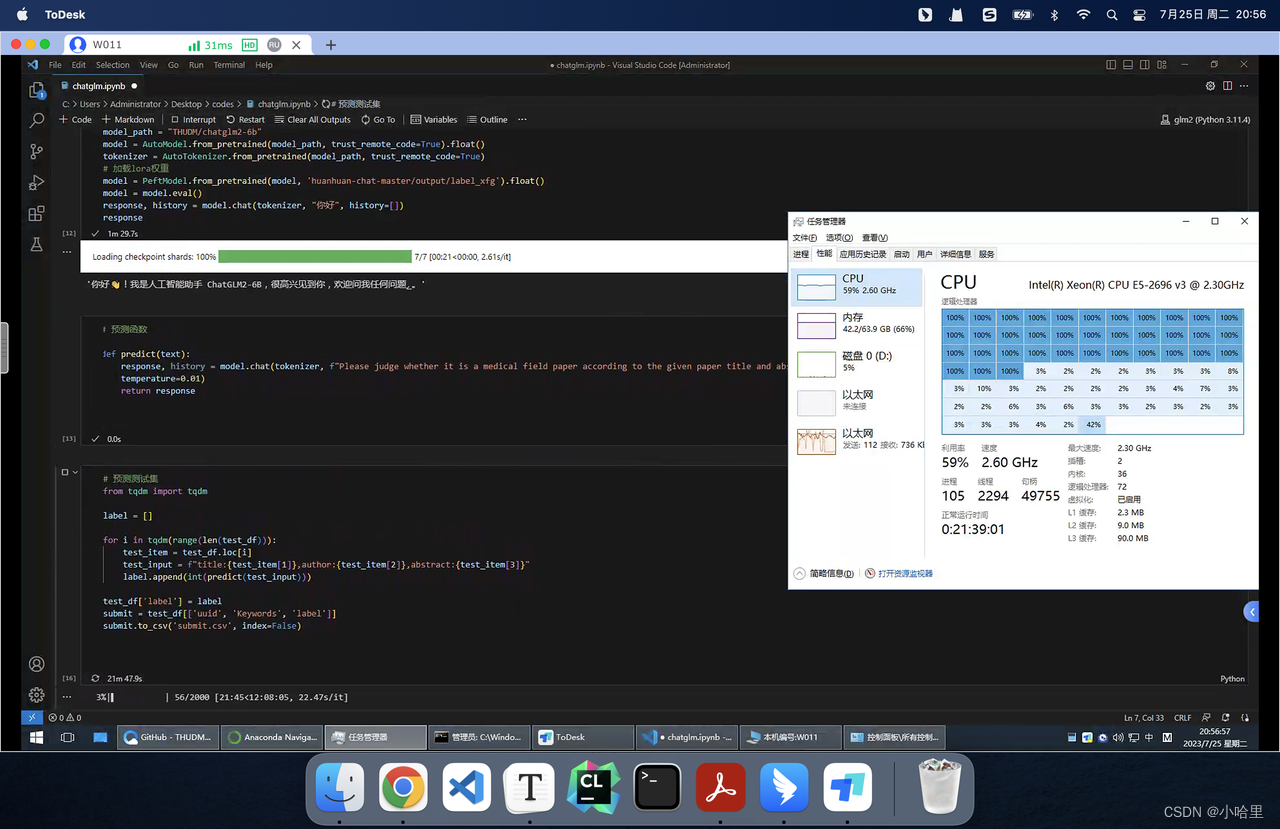
-
大模型运行

3、关于DataWhale-NLP
报名时间:2023/7/13 - 2023/7/20
起因是考研,下学期学校有个实习课,想看看能不能水个实习证明。
- 但是好像还是挺麻烦的,要一等奖或者2个方向三等奖或宣传大使(感觉打比赛要花时间,拉人头也挺麻烦)
- 加上学校的可能要学校自己的报告上盖章,可能大概是用不了的。
- 所以后来就跑路了,没怎么调代码,随便搞了一下,还是考研复习要紧。
简单记录下,报名到摸鱼组队还是花了可能有将近半天的时间的。

关于宣传大使:
- 方式一:将我们的活动推文/活动海报,分享到校内公众号/社群/朋友圈等(推荐指数:⭐⭐)
方式二:自己重新制作活动推文/活动海报,分享到校内公众号/社群/朋友圈等(推荐指数:⭐⭐⭐)
方式三:将推文或海报分享到个人自媒体(推荐指数:⭐⭐⭐) - 10 荣誉证书 20
荣誉证书+贴纸+装饰挂绳+钥匙扣 30
荣誉证书+贴纸+鼠标垫 50
荣誉证书+贴纸+立牌+简历指导 60
荣誉证书+贴纸+卫衣+简历指导