作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
Hadoop综合大作业
1.以下是爬虫大作业产生的csv文件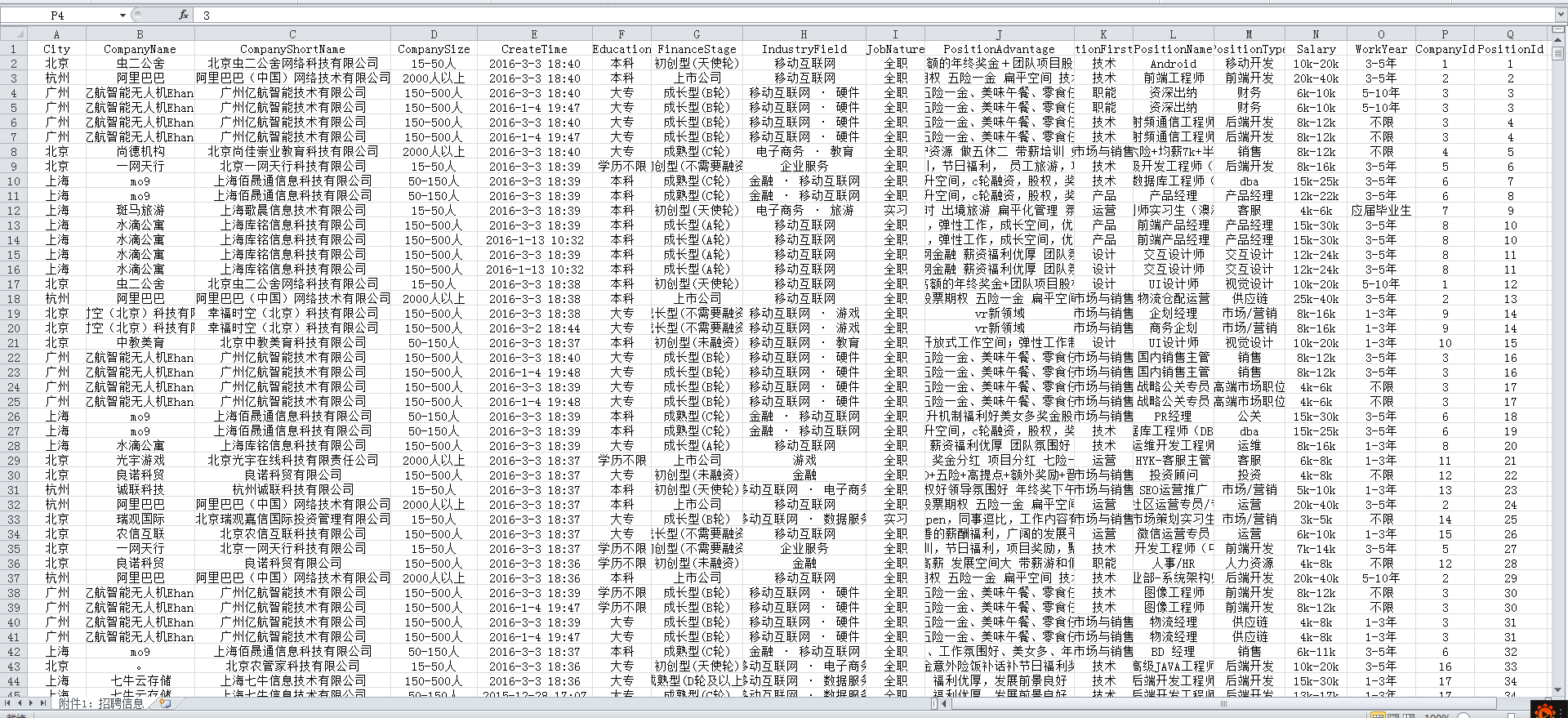
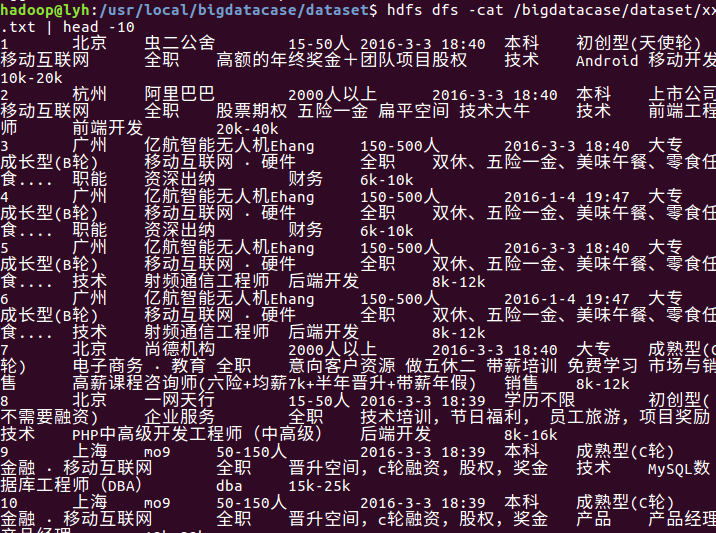
把csv上传到HDFS
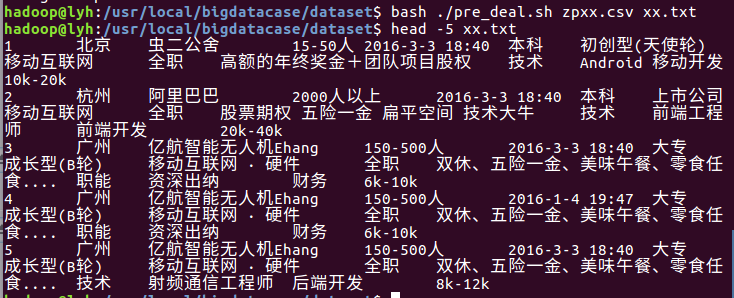
2.对CSV文件进行预处理生成无标题文本文件
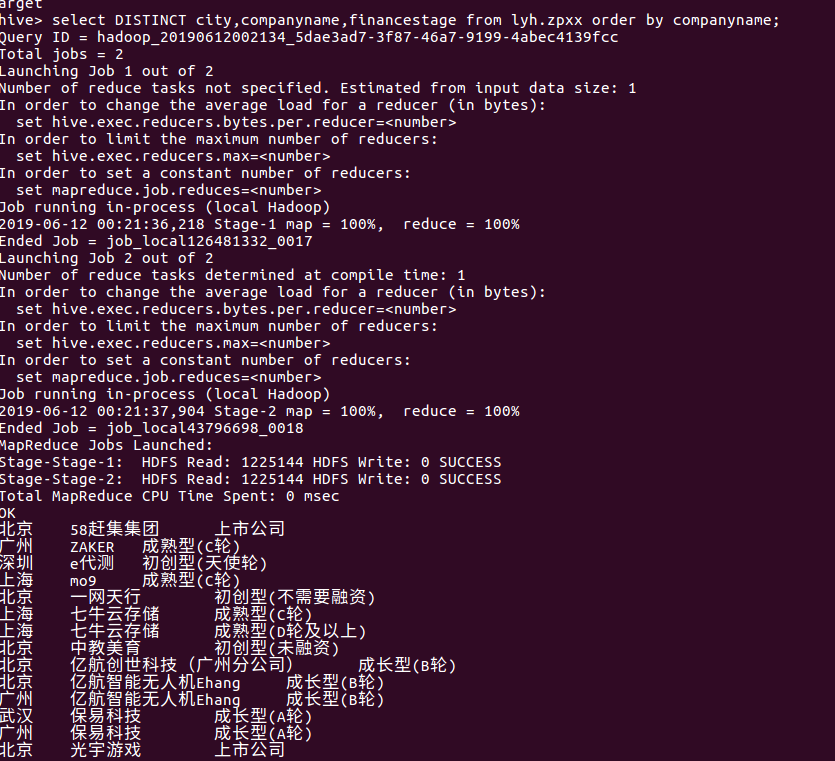
3.把hdfs中的文本文件最终导入到数据仓库Hive中,在Hive中查看并分析数据。

4.用Hive对爬虫大作业产生的进行数据分析
查询公司的类型,对公司的整体情况进行一个对比,了解哪些公司更具发展性:
根据岗位的类型查询。此处查询要实习生的岗位有哪些,发现,需要实习生的企业不多。

查询不同类别的岗位需求,了解哪些岗位更需要人才:

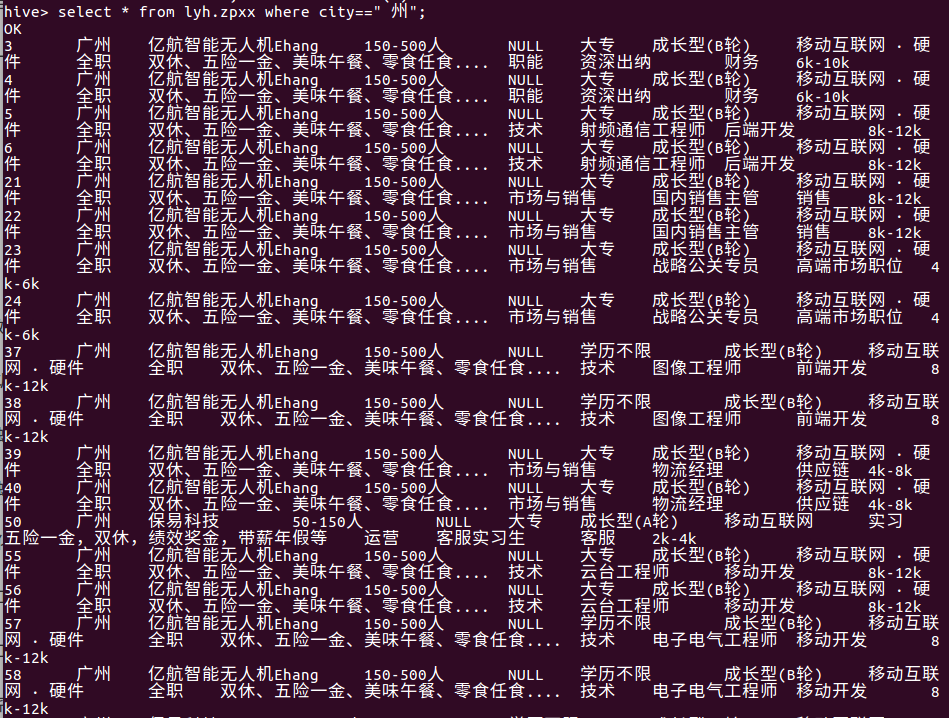
查询在广州市内的岗位需求,根据城市查询:
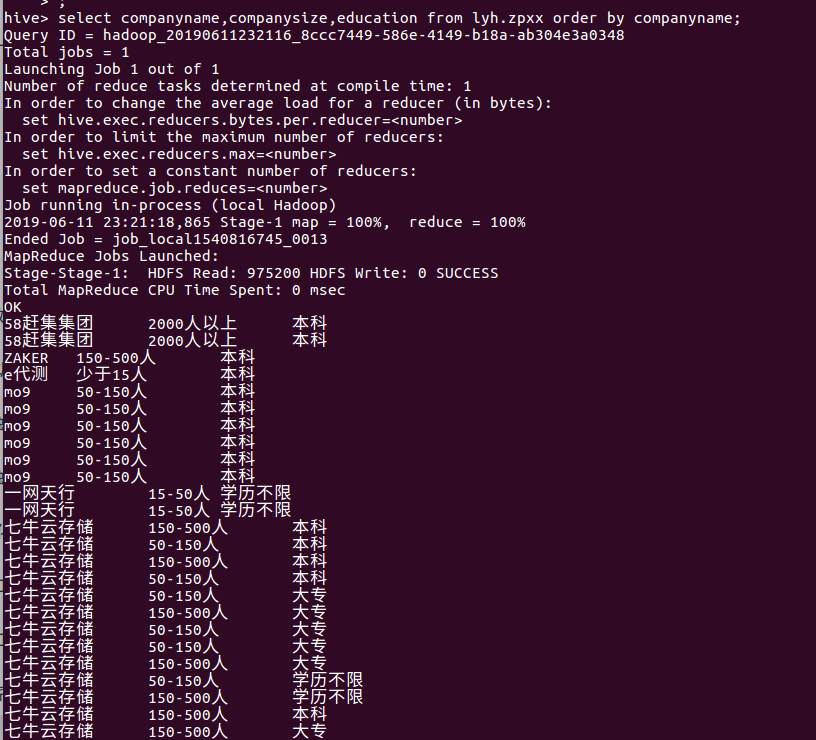
查询公司的规模,对学历的要求发现:大公司基本都要高学历的人员:
查看岗位福利,对比各公司岗位的情况: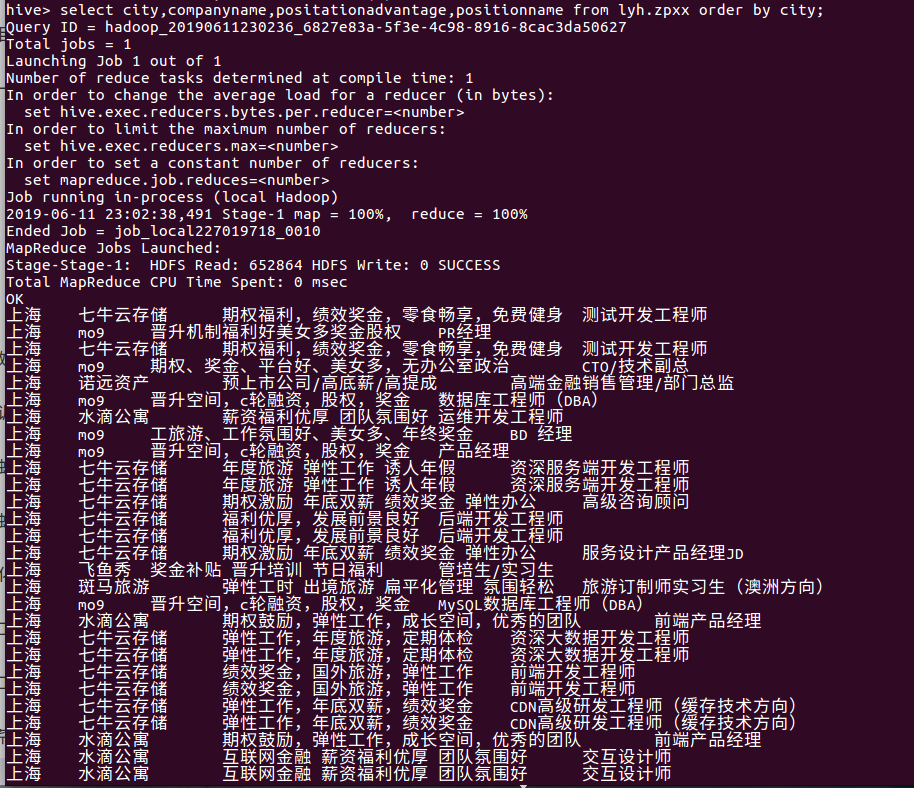
查询对比各公司同类岗位的薪水:

查询各岗位的薪水情况,发现偏技术型的岗位薪资更高: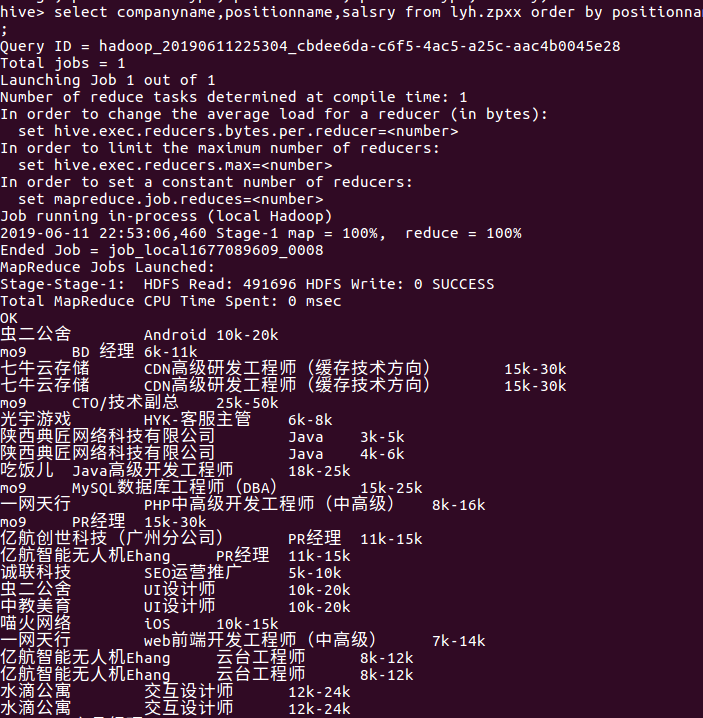
查询城市岗位需求量,发现北上广的城市需求较多:
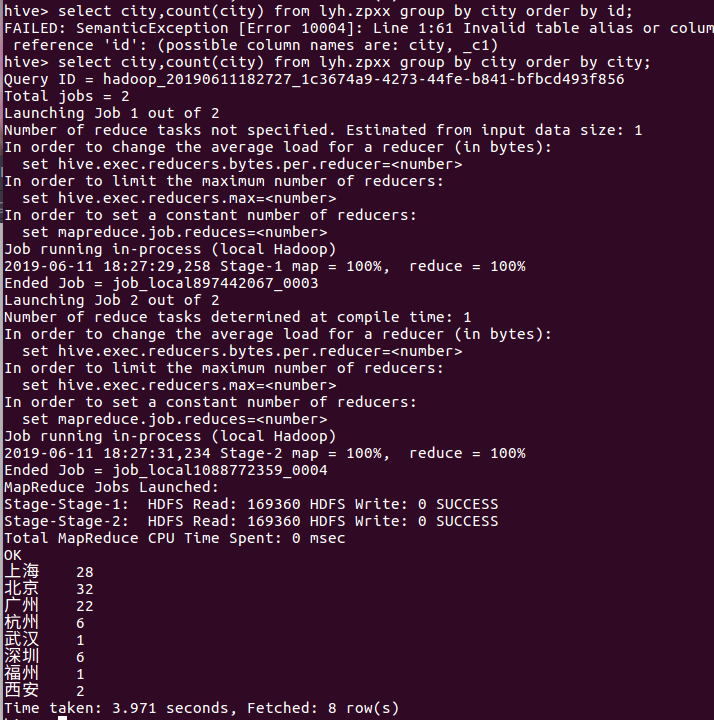
5.总结
总的来说,这次的项目是对旧知识的巩固和数据库的一个新的认识,但是遇到的问题也是有以下:
a.爬取的数据中文内容多,因此在导入linux系统时出现了中文乱码。
b.对于awk语言对数据的处理可以说是一窍不通,有待提高。
c.数据存入数据库表前未能对数据进行再一次的处理,进行数据库表内容查询分析时会出现一些非预期的错误。