上文学习了 OCR 破解识别验证码,但是还是发现识别的精度不高,因此针对这个问题本文利用机器学习的方法去破解验证码。
本文所用的机器学习的方法为 余弦相似度 ,重点的思想是将图片的每一个像素点作为一个坐标点,构造成一个很长的向量。例如,假设某一张图片由200个像素点组成,每个像素点都以 RGB 颜色的值来表示,其取值范围为 0-255 ,利用该图片的向量和训练样本中的样本做 余弦相似对比 ,如果夹角越小值越大,也就是说两条向量越相似,则图片和训练样本越相似,那么就可以识别出这张图片所代表的验证码了,原理不难,下面是代码实现。
新建 3 个文件夹,分别命名为:iconset 、 jpg 、 py 。iconset 文件夹用于存放训练样本,训练样本下载:
jpg 文件夹用于存放需要识别的验证码,本文所用的 验证码 为:
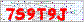
'''
遇到python不懂的问题,可以加Python学习交流群:1004391443一起学习交流,群文件还有零基础入门的学习资料
'''py 文件夹用于存放代码。读取图片出来,得到图像的统计直方图:
# !/usr/bin/python3.4
# -*- coding: utf-8 -*-
from PIL import Image
im = Image.open("../jpg/captcha.gif")
his = im.histogram()
返回的 his 为统计直方图,其类型是一个数组,长度为255,his[0] 代表 RGB 颜色 0 的数量有多少,例如该图例如最后一个元素为625,即255(代表的是白色)最多。将其统计直方图和 RGB 颜色的值构造成字典,并且按照由高到低排序:
values = {}
for i in range(0, 256):
values[i] = his[i]
temp = sorted(values.items(), key=lambda x: x[1], reverse=True)
print(temp)
可以看到颜色 255 最多,也就是白色最多,其次是 212 和 220。然后生成一张和原长宽相等的白底的空白图片:
# 获取图片大小,生成一张白底255的图片
im2 = Image.new("P", im.size, 255)
将统计直方图的颜色依次添加到白底图片中:
# 获得y坐标
for y in range(im.size[1]):
# 获得y坐标
for x in range(im.size[0]):
# 获得坐标(x,y)的RGB值
pix = im.getpixel((x, y))
# 这些是要得到的数字
if pix == 212:
# 将黑色0填充到im2中
im2.putpixel((x, y), 0)
im2.show(1)
多次重复上面的操作,可以发现 pix 的值为220和227的时候能打印出完整的验证码出来:
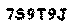
其实如果对于 RGB 颜色了解的人,一眼就可以看出验证码包含的红色最多,所以 pix 直接可以等于:
# 227红色
if pix == 227:
但是现实的图片不完整,观看统计直方图可以知道 220 非常多,也就是灰色很多,所以写成:
# 220灰色,227红色
if pix == 220 or pix == 227:
找到了颜色,然后将每一个数字字母按照颜色切割出来,因为得到的 im2 这张新的图片是白底黑字,所以只要不是白色就可以将其切割下来:
inletter = False
foundletter = False
start = 0
end = 0
letters = []
for x in range(im2.size[0]):
for y in range(im2.size[1]):
pix = im2.getpixel((x, y))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = x
if foundletter == True and inletter == False:
foundletter = False
end = x
letters.append((start, end))
inletter = False
得到的 letters 为:
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]
即可以将图片切割成6份,第一份是按照 x=6 到 x=14 纵向切割成一个条状,其他同理。
现在需要复习余弦相似度的公式:
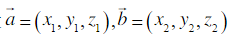
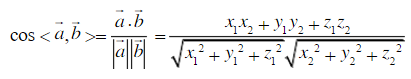
将公式编写成代码:
# 夹角公式
import math
class VectorCompare:
# 计算矢量大小
# 计算平方和
def magnitude(self, concordance):
total = 0
# concordance.iteritems:报错'dict' object has no attribute 'iteritems'
# concordance.items()
for word, count in concordance.items():
total += count ** 2
return math.sqrt(total)
# 计算矢量之间的 cos 值
def relation(self, concordance1, concordance2):
topvalue = 0
for word, count in concordance1.items():
if word in concordance2:
# 计算相乘的和
topvalue += count * concordance2[word]
return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2))
将图片按照每个像素点构造成一个向量:
# 将图片转换为矢量
def buildvector(im):
d1 = {}
count = 0
for i in im.getdata():
d1[count] = i
count += 1
return d1
读取训练集,将训练集的图片变成向量:
v = VectorCompare()
iconset = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '0', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k',
'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
import os
imageset = []
for letter in iconset:
for img in os.listdir('../iconset/%s/' % (letter)):
temp = []
if img:
temp.append(buildvector(Image.open("../iconset/%s/%s" % (letter, img))))
imageset.append({letter: temp})
训练识别:
# 开始破解训练
count = 0
for letter in letters:
# (切割的起始横坐标,起始纵坐标,切割的宽度,切割的高度)
im3 = im2.crop((letter[0], 0, letter[1], im2.size[1]))
guess = []
# 将切割得到的验证码小片段与每个训练片段进行比较
for image in imageset:
# image.iteritems:报错'dict' object has no attribute 'iteritems'
# 改成image.items()
for x, y in image.items():
if len(y) != 0:
# y[0]为训练集里面的字母图片,即正确的图片
# buildvector(im3))为切割出来的字母切片,用来和y[0]进行夹角比对
# x为iconset
# x依次显示为0,1,2,3,。。。,x,y,z
guess.append((v.relation(y[0], buildvector(im3)), x))
# 排序选出夹角最小的(即cos值最大)的向量,夹角越小则越接近重合,匹配越接近
guess.sort(reverse=True)
print("", guess[0])
count += 1
得到结果如下:
(0.9637681159420289, '7')
(0.96234028545977, 's')
(0.9286884286888929, '9')
(0.9835037060984447, 't')
(0.9675116507250627, '9')
(0.9698971168877263, 'j')