在学习爬虫的过程中难免会遇到验证码问题,作为纯自动化的爬虫是不可能手动去输入验证码的。
那么我们就要学会怎么去识别它。
而验证码也分很多种类,主要的几种:
(1)图像验证码:这是最简单的一种,也很常见。就比如CSDN登录几次失败之后就会出验证码。
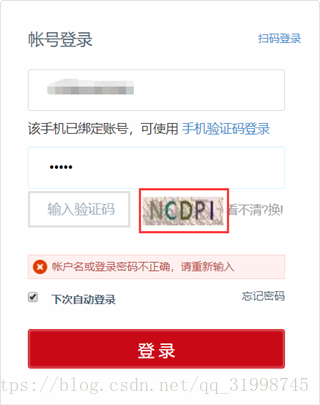
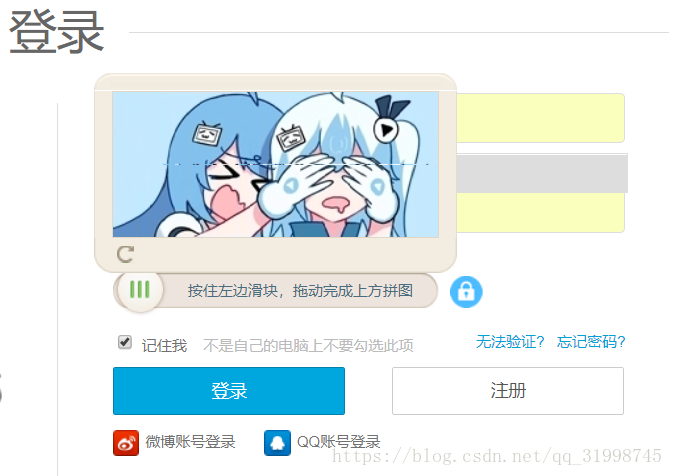
(2)滑块验证码:需要按住滑块并移到正确的位置。比如bilibili的登录验证。(这个我也写过识别代码,源码托管github:https://github.com/OSinoooO/bilibili_geetest。可以去看一看呀QAQ)
(3)点触验证码:需要识别图片中的文字或类型并按序点击。比如12306的登录验证。

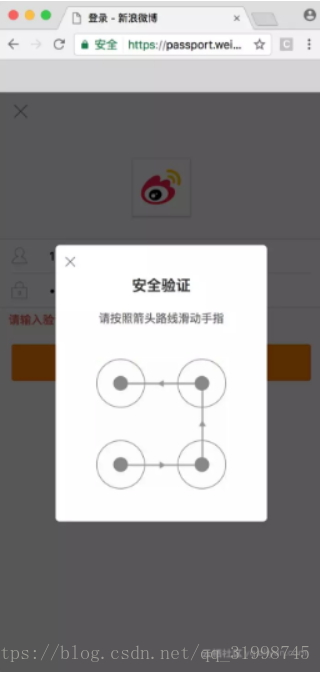
(4)宫格验证码:类似安卓的宫格解锁。比如新浪微博的宫格验证码。
准备工作
我们这次要识别的图像验证码,需要用到tesserocr库,但是安装tesserocr库之前,需要先安装好相应版本的tesseract。因为tesserocr是基于tesseract来封装的库。
安装tesseract
Github:https://github.com/tesseract-ocr/tesseract
下载地址:https://digi.bib.uni-mannheim.de/tesseract
语言包:https://github.com/tesseract-ocr/tessdata
官方文档:https://github.com/tesseract-ocr/tesseract/wiki
文件带dev的是开发版本,不带dev的是稳定版本。
选择需要的版本后开始下载,然后安装配置比较简单,就不多说了。语言包的作用就是可以识别多国语言,可在安装选项里选择,也可以自行下载。(下载后的语言包需要解压后放到Tesseract-OCR/tessdata目录下)
安装好之后打开cmd,输入tesseract,如果出现以下信息就说明安装成功。

安装tesserocr
tesseract安装好以后就可以安装tesserocr了。
Github: https://github.com/sirFz/tesserocr
PyPi:https://pypi.python.org/pypi/tesserocr
github上有较为详尽的安装说明,大多数情况下我们可以在cmd下通过pip来安装:(前提是安装了pip,一般python都自带)
pip install tesserocr
但是由于windows下tesserocr 2.3.0版本目前还没有,所以pip安装在Windows下面会报错。
解决方法之一是通过wheel安装:
1.下载tesserocr 2.2.2版本的wheel文件(注意与tesseract版本的对应)
2.通过如下命令安装:(需要与下载文件在同一目录下)
pip install 文件名.whl
PS:即使库能安装成功,有时候运行还是会出现错误(坑!!),推荐个博文:https://www.imooc.com/article/45278
至少我遇到的错误是解决了 - -
代码构建
完成上述准备工作之后,就可以开始写代码了。
代码逻辑是很简单的,为了便于理解和以后的调用,我把它封装成了一些方法:
初始化
from PIL import Image
import tesserocr, requests
# 图片下载链接
image_url = 'https://passport.csdn.net/ajax/verifyhandler.ashx'
# 图片保存路径
image_path = 'image/captcha.jpg'首先导入必要的包,然后初始化连接(可修改)和路径(可修改)。
图片下载和获取
def image_download():
"""
图片下载
"""
response = requests.get(image_url)
with open(image_path, 'wb') as f:
f.write(response.content)
def get_image():
"""
用Image获取图片文件
:return: 图片文件
"""
image = Image.open(image_path)
return image图像处理
def image_grayscale_deal(image):
"""
图片转灰度处理
:param image:图片文件
:return: 转灰度处理后的图片文件
"""
image = image.convert('L')
#取消注释后可以看到处理后的图片效果
#image.show()
return image
def image_thresholding_method(image):
"""
图片二值化处理
:param image:转灰度处理后的图片文件
:return: 二值化处理后的图片文件
"""
# 阈值,控制二值化程度,自行调整(不能超过256)
threshold = 160
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# 图片二值化,此处第二个参数为数字一
image = image.point(table, '1')
# 取消注释后可以看到处理后的图片效果
#image.show()
return image经过转灰度和二值化处理之后的图片更加容易识别,可以通过 show() 方法来显示处理后的图片。
处理前:

转灰度处理后:

二值化处理后:

图像识别
def captcha_tesserocr_crack(image):
"""
图像识别
:param image: 二值化处理后的图片文件
:return: 识别结果
"""
result = tesserocr.image_to_text(image)
return result调用tesserocr的image_to_text()方法识别:
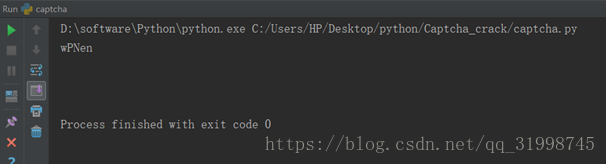
然后通过调用上述方法,就可以实现自动识别验证码了。
PS:不是每次识别都能成功,要想提高成功率,需要下载训练好的语言包。(下载网速巨慢!!!)
还有就是用深度学习的方法去训练机器~
源码(Github:https://github.com/OSinoooO/Gaptcha_crack)
from PIL import Image
import tesserocr, requests
# 图片下载链接
image_url = 'http://my.cnki.net/elibregister/CheckCode.aspx'
# 图片保存路径
image_path = 'image/captcha.jpg'
def image_download():
"""
图片下载
"""
response = requests.get(image_url)
with open(image_path, 'wb') as f:
f.write(response.content)
def get_image():
"""
用Image获取图片文件
:return: 图片文件
"""
image = Image.open(image_path)
return image
def image_grayscale_deal(image):
"""
图片转灰度处理
:param image:图片文件
:return: 转灰度处理后的图片文件
"""
image = image.convert('L')
#取消注释后可以看到处理后的图片效果
#image.show()
return image
def image_thresholding_method(image):
"""
图片二值化处理
:param image:转灰度处理后的图片文件
:return: 二值化处理后的图片文件
"""
# 阈值
threshold = 160
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# 图片二值化,此处第二个参数为数字一
image = image.point(table, '1')
#取消注释后可以看到处理后的图片效果
#image.show()
return image
def captcha_tesserocr_crack(image):
"""
图像识别
:param image: 二值化处理后的图片文件
:return: 识别结果
"""
result = tesserocr.image_to_text(image)
return result
if __name__ == '__main__':
image_download()
image = get_image()
img1 = image_grayscale_deal(image)
img2 = image_thresholding_method(img1)
print(captcha_tesserocr_crack(img2))