平台:win10 x64 +VS 2015专业版 +opencv-2.4.11 + gtk_-bundle_2.24.10_win32
主要参考:1.代码:RobHess的SIFT源码:SIFT+KD树+BBF算法+RANSAC算法
2.书:王永明 王贵锦 《图像局部不变性特征与描述》
RobHess的SIFT源码分析:
(1) minpq.h和minpq.c文件
这两个文件中实现了最小优先级队列(Minimizing Priority Queue),也就是小顶堆,在k-d树的建立和搜索过程中要用到。
(2) kdtree.h和kdtree.c文件
这两个文件中实现了k-d树的建立以及用BBF(Best Bin First)算法搜索匹配点的函数。
如果你需要对两个图片中的特征点进行匹配,就要用到这两个文件。
请在看这个之前先看完以下内容:
SIFT四步骤:
步骤一:建立尺度空间,即建立高斯差分(DoG)金字塔dog_pyr
步骤二:在尺度空间中检测极值点,并进行精确定位和筛选创建默认大小的内存存储器
步骤三:特征点方向赋值,完成此步骤后,每个特征点有三个信息:位置、尺度、方向
KD树问题issue汇总
问题及解答:
(1)问题描述:SIFT检测的特征点后,为什么用KD树算法进行特征匹配?
答: 找到问题的本质:
之前网上有blog内曾经介绍过SIFT特征匹配算法,特征点匹配和数据库查、图像检索本质上是同一个问题,都可以归结为一个通过距离函数在高维矢量之间进行相似性检索的问题,如何快速而准确地找到查询点的近邻,不少人提出了很多高维空间索引结构和近似查询的算法。
一般说来,索引结构中相似性查询有两种基本的方式:
一种是范围查询,范围查询时给定查询点和查询距离阈值,从数据集中查找所有与查询点距离小于阈值的数据
另一种是K近邻查询,就是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,它就是最近邻查询。
同样,针对特征点匹配也有两种方法:
最容易的办法就是线性扫描,也就是我们常说的穷举搜索,依次计算样本集E中每个样本到输入实例点的距离,然后抽取出计算出来的最小距离的点即为最近邻点。此种办法简单直白,但当样本集或训练集很大时,它的缺点就立马暴露出来了,举个例子,在物体识别的问题中,可能有数千个甚至数万个SIFT特征点,而去一一计算这成千上万的特征点与输入实例点的距离,明显是不足取的。
另外一种,就是构建数据索引,因为实际数据一般都会呈现簇状的聚类形态,因此我们想到建立数据索引,然后再进行快速匹配。索引树是一种树结构索引方法,其基本思想是对搜索空间进行层次划分。根据划分的空间是否有混叠可以分为Clipping和Overlapping两种。前者划分空间没有重叠,其代表就是k-d树;后者划分空间相互有交叠,其代表为R树。
什么是k-d树?
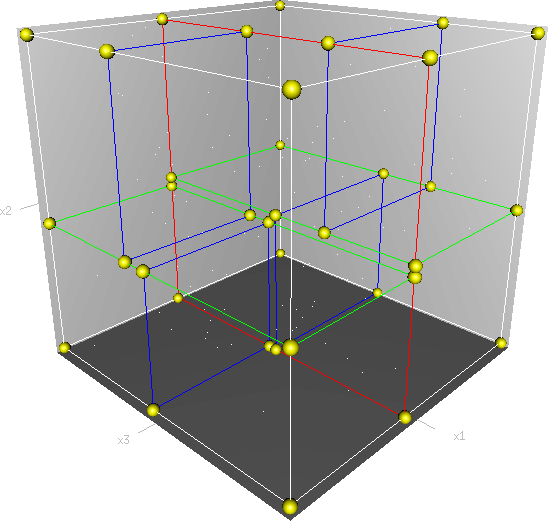
首先必须搞清楚的是,k-d树是一种空间划分树,说白了,就是把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。想像一个三维(多维有点为难你的想象力了)空间,kd树按照一定的划分规则把这个三维空间划分了多个空间,如下图所示:
(2)问题描述:RobHess的源码如何实现RANSAC,大概思路是这样的?
答:(2.1)代码及说明:——match.c
//特征匹配
fprintf( stderr, "Building kd tree...\n" ); //建立kd树
kd_root = kdtree_build( feat2, n2 ); //根据图2的特征点集feat2建立k-d树,返回k-d树根给kd_root
//遍历特征点集feat1,针对feat1中每个特征点feat,选取符合距离比值条件的匹配点,放到feat的fwd_match域中
for( i = 0; i < n1; i++ ) //逐点匹配
{
feat = feat1 + i; //第i个特征点的指针
//在kd_root中搜索目标点feat的2个最近邻点,存放在nbrs中,返回实际找到的近邻点个数
k = kdtree_bbf_knn( kd_root, feat, 2, &nbrs, KDTREE_BBF_MAX_NN_CHKS ); //找2个最近点
if( k == 2 ) //只有进行2次以上匹配过程,才算是正常匹配过程
{
d0 = descr_dist_sq( feat, nbrs[0] ); //feat与最近邻点的距离的平方
d1 = descr_dist_sq( feat, nbrs[1] ); //feat与次近邻点的距离的平方
//若d0和d1的比值小于阈值NN_SQ_DIST_RATIO_THR,则接受此匹配,否则剔除
if( d0 < d1 * NN_SQ_DIST_RATIO_THR ) //最近点与次最近点距离之比要小才当做正确匹配,然后画一条线
{
//pt1,pt2为连线的两个端点,将目标点feat和最近邻点作为匹配点对
pt1 = cvPoint( cvRound( feat->x ), cvRound( feat->y ) );
pt2 = cvPoint( cvRound( nbrs[0]->x ), cvRound( nbrs[0]->y ) );
pt2.y += img1->height; //由于两幅图是上下排列的,pt2的纵坐标加上图1的高度,作为连线的终点
cvLine( stacked, pt1, pt2, CV_RGB(255,0,255), 1, 8, 0 ); //画出连线
m++; //统计匹配点对的个数
feat1[i].fwd_match = nbrs[0]; //使点feat的fwd_match域指向其对应的匹配点
}
}
free( nbrs ); //释放近邻数组
}
fprintf( stderr, "Found %d total matches\n", m ); //总共找到多少组匹配
display_big_img( stacked, "Matches" );
cvWaitKey( 0 );
(2.2)kdtree_build代码及说明:
答:
struct kd_node* kdtree_build( struct feature* features, int n )
{
struct kd_node* kd_root;
if( ! features || n <= 0 )
{
fprintf( stderr, "Warning: kdtree_build(): no features, %s, line %d\n",
__FILE__, __LINE__ );
return NULL;
}
//初始化
kd_root = kd_node_init( features, n ); //n - 特征数量,初始化根
expand_kd_node_subtree( kd_root ); //kd树扩展
return kd_root;
}
(2.2.1)kd_node_init代码及说明:
答:
static struct kd_node* kd_node_init( struct feature* features, int n )
{
struct kd_node* kd_node;
kd_node = malloc( sizeof( struct kd_node ) );
memset( kd_node, 0, sizeof( struct kd_node ) ); //0填充
kd_node->ki = -1;
kd_node->features = features;
kd_node->n = n;
return kd_node;
}
(2.2.2)expand_kd_node_subtree代码及说明:
答:
static void expand_kd_node_subtree( struct kd_node* kd_node )
{
/* base case: leaf node */
if( kd_node->n == 1 || kd_node->n == 0 )
{ //叶子节点 //伪叶子节点
kd_node->leaf = 1;
return;
}
assign_part_key( kd_node ); //get ki,kv
partition_features( kd_node ); //creat left and right children,特征点ki位置左树比右树模值小,kv作为分界模值
//kd_node中关键点已经排序
if( kd_node->kd_left )
expand_kd_node_subtree( kd_node->kd_left );
if( kd_node->kd_right )
expand_kd_node_subtree( kd_node->kd_right );
}
(2.3)kdtree_bbf_knn代码及说明:
答:
//KD树近邻搜索改进之BBF算法
int kdtree_bbf_knn( struct kd_node* kd_root, struct feature* feat, int k,
struct feature*** nbrs, int max_nn_chks )
{
struct kd_node* expl;
struct min_pq* min_pq;
struct feature* tree_feat, ** _nbrs;
struct bbf_data* bbf_data;
int i, t = 0, n = 0;
if( ! nbrs || ! feat || ! kd_root )
{
fprintf( stderr, "Warning: NULL pointer error, %s, line %d\n",
__FILE__, __LINE__ );
return -1;
}
_nbrs = calloc( k, sizeof( struct feature* ) );
min_pq = minpq_init();
minpq_insert( min_pq, kd_root, 0 ); //把根节点加入搜索序列中
//队列有东西就继续搜,同时控制在t<200步内
while( min_pq->n > 0 && t < max_nn_chks )
{
//刚进来时,从kd树根节点搜索,exp1是根节点
//后进来时,exp1是min_pq差值最小的未搜索节点入口
//同时按min_pq中父,子顺序依次检验,保证父节点的差值比子节点小.这样减少返回搜索时间
expl = (struct kd_node*)minpq_extract_min( min_pq );
if( ! expl )
{
fprintf( stderr, "Warning: PQ unexpectedly empty, %s line %d\n",
__FILE__, __LINE__ );
goto fail;
}
//从根节点(或差值最小节点)搜索,根据目标点与节点模值的差值(小)
//确定在kd树的搜索路径,同时存储各个节点另一入口地址\同级搜索路径差值.
//存储时比较父节点的差值,如果子节点差值比父节点差值小,交换两者存储位置,
//使未搜索节点差值小的存储在min_pq的前面,减小返回搜索的时间.
expl = explore_to_leaf( expl, feat, min_pq );
if( ! expl )
{
fprintf( stderr, "Warning: PQ unexpectedly empty, %s line %d\n",
__FILE__, __LINE__ );
goto fail;
}
for( i = 0; i < expl->n; i++ )
{
//使用exp1->n原因:如果是叶节点,exp1->n=1,如果是伪叶节点,exp1->n=0.
tree_feat = &expl->features[i];
bbf_data = malloc( sizeof( struct bbf_data ) );
if( ! bbf_data )
{
fprintf( stderr, "Warning: unable to allocate memory,"
" %s line %d\n", __FILE__, __LINE__ );
goto fail;
}
bbf_data->old_data = tree_feat->feature_data;
bbf_data->d = descr_dist_sq(feat, tree_feat); //计算两个关键点描述器差平方和
tree_feat->feature_data = bbf_data;
//取前k个
n += insert_into_nbr_array( tree_feat, _nbrs, n, k );
}
t++;
}
minpq_release( &min_pq );
for( i = 0; i < n; i++ ) //bbf_data为何搞个old_data?
{
bbf_data = _nbrs[i]->feature_data;
_nbrs[i]->feature_data = bbf_data->old_data;
free( bbf_data );
}
*nbrs = _nbrs;
return n;
fail:
minpq_release( &min_pq );
for( i = 0; i < n; i++ )
{
bbf_data = _nbrs[i]->feature_data;
_nbrs[i]->feature_data = bbf_data->old_data;
free( bbf_data );
}
free( _nbrs );
*nbrs = NULL;
return -1;
}