这次去听了3天讲座,其实没啥特别的收货,但是记录下来,说不定有点意义。
这么几天的讲座,大部分还是将传统的算法用于深度学习,对于深度学习来说他仅仅是一个工具。所以,讲座中大部分大佬讲的是关于传统算法。
包括optical flow, karman filter,
为什么使用batch_normalization?其中很重要的原因是为了消除deformation,学习图像中的不变性。
jianbo shi:
Deeplab:https://arxiv.org/pdf/1606.00915.pdf
address the task of semantic image segmentation with deep learning.
1.highlight convolution with upsimpled filters, or 'atrous convolution' , as powerful tool in dense preditical task.
2. propose atrous spatial pyramid pooling(ASPP) to robustly segment objects at multiple scales.
3. improve the localization of object boundaries by combining methods from DCNNs and probabilitic models.
combination of max-pooling and downsampling in DCNNs achieves invariance but has a toll on localization accuracy.常用DCNNs方法是用最大池化+下采用,这虽然可以使用不变性,但是会对定位的精确性不利。overcome this by combining the responses at the final DCNN layer with a fully connected Conditional Random Field(CRF).
Introduction
DCNNs trained in an end-to-end manner have delivered strikingly better results than systems relying on hand-crafted features. Essential to this success is the built-in invariance of DCNNs to local image transformations, which allows them to learn increasingly abstract data representations。
对于分类任务来说,需要的就是这种不变性,但是对于密集的预测任务来说,这种空间信息的抽象是不期望的,如语义分割。
具体而言,我们考虑在image segmentation中的三个挑战:1、特征分辨率的减少2、目标存在于多个尺度下3、由于DCNNs不变性造成的定位精度下降
第一个挑战是由于重复的最大池化+下采样本导致的(之所以重复最大池化+下采样是为了分类)。为了克服这个阻碍并有效生成更加密集的feature maps,我们移除了DCNN最后几层的最大池化中的下采样运算器(operator),相反在后续卷积层中对过滤器进行上采样。
第二个挑战是检测目标尺度大小是多样的。一种标准的方法是通过将缩放的图像重新输入DCNN,再合成特征或者计算score maps。这个方法确实可以提高我们的性能,但需要以计算在所有深度卷积神经网络的层上对输入图像的多尺度版本为代价。相反受到SPP的启发,我们提出了一种在多个采样率上重采样(resampling)特定的特征层来做卷积的方法。我们用不同采样率的多个并行的多孔卷积层做这种映射,我们称这种技术为ASPP(atrous spatial pooling)。
第三个挑战是物体分类器要求对空间变换具有不变性,内在地限制了深度卷积神经网络的空间精度。减轻这个问题的一个方法是在计算最终的分割结果时,跳层从多个网络层中提取“超列”特征(U-net?)。需要提出的是,我们采用全连接条件随机场CRF,如论文22,提升了模型的能力可以抓取精细的细节。条件随机场广泛地应用于语义分割中,合并从局部像素和边缘(论文23,24),或超像素(论文25)中获得低阶信息的多路分类器中计算出来的分类分值。构建层次依赖模型(论文26,27,28),和/或分割用的高层依赖信息(论文29,30,31,32,33)的复杂度日益增加,我们使用了论文22提出的全连接配对条件随机场,计算效率更高,可以抓取精细的边缘细节,也适用于较长的依赖项。论文22中的模型增强了基于提升的像素级别分类器的性能。本文工作中,我们展示了,当它与深度卷积神经网络的像素级别分类器耦合的时候,可以取得更好的结果。
Related Work
第一类是采用自底向上的串联图像分割,然后基于DCNN对区域进行分类。例如提取边界框(bounding-box proposals)或区域掩码(masked regions)作为DCNN的输入,从而将形状结合到分类。
第二类是将卷积计算的DCNN特征用于密集图像标注,并将它们与语义分割结合起来。
第三类是使用DCNN直接提供密集的像素级标签,甚至可以放弃分割。本文就是这一类。
Methods
atrous convolution for dense feature extraction and field-of-view enlargement
用于密集特征提取和扩大视野域的atrous convolution
FCN类的方法使用DCNN时候,因为连续的最大池化和跨步(striding)会明显减少了生成特征映射的空间分辨率(通常每个方向是32倍),FCN论文中采用的补救措施是使用反卷积层,但需要额外的内存和时间。
我们使用在小波变换中研发的算法atrous,即空洞卷积。什么是空洞卷积?先看1-D情况下(如果觉得):

上面的yi是atrous conv的输出,xi是1-d的输入信号,这里的速率参数r对应于我们采样输入信号的步长(striding)。在标准卷积中r=1(如下图a所示)。

(如果觉得1-D的图看起来很奇怪,想看图像处理中的2-d图片可以参考:https://blog.csdn.net/silence2015/article/details/79748729)
如下图所示,上排(即蓝色箭头)是对图片先下采样然后上采样的过程,其中stride=2即先将分辨率降低2倍,再上采样效果。
下排(红色箭头)则直接采用astrous conv,rate=2的效果,另外两者卷积核大小都选用相同的7*7。

对于DCNN的上下文,我们可以在层链中(a chain of layers)使用多孔卷积,这样可以在任意高的分辨率上计算最后的DCNN响应。比如,为了对VGG-16或ResNet-101网络中计算出来的特征响应的空间密度翻倍,我们发现最后的池化或卷积层会减小分辨率(分别是’pool5’或’conv5_1’),设置步长为1以避免信号抽取,并用速率为r=2的多孔卷积层取代所有后续的卷积层。这个方法应用于整个网络,就可以在原始图像分辨率上计算特征响应,但这样成本比较高。我们可以采用混合方法,达到一个比较好的效率/精度平衡,用速率r=4的多孔卷积增加计算的特征地图的密度(4倍),用另外一个因子为8的快速双线性插值在原始图像分辨率上恢复特征地图。双线性插值在这样的配置中足够了,因为分类得分值地图(对应对数概率)非常平滑,如图5所示。与论文14的去卷积方法不同,本方法将图像分类网络转换成稠密特征提取器,不需要学习更多的参数,得到更快的DCNN训练。

图5 Score map (input before softmax function) and belief map (output of softmax function) for Aeroplane. We show the score (1st row) and belief (2nd row) maps after each mean field iteration. The output of last DCNN layer is used as input to the mean field inference.
Atrous卷积还允许我们在任何DCNN层任意放大滤波器的视野域(field-of-view)。现有技术的DCNN通常采用空间上小的卷积核(通常为3×3),以便保持计算和包含的参数数量。速率为r的Atrous卷积在连续的滤波器值之间引入r-1个零,有效地将一个k×k滤波器的核大小扩大到ke = k +(k-1)(r-1)而不增加参数的数量或者计算。因此,它提供了一种有效的机制来控制视野域,and finds the best trade-off between accurate localization(small field-of-view) and context assimilation(large field-of-view)。
我们的DeepLab-LargeFOV模型变体[38]采用了在VGG-16'fc6'层中速率r = 12的atrous卷积,具有显着的性能提升.
在实现上,有两种方法可以有效地执行多孔卷积。第一种是插入空洞(零元素)或者对输入特征地图同等稀疏地采样,来对滤波器进行上采样。第二种方法,用一个与多孔卷积比例r相同的因子对输入特征地图进行子采样,对每个r×r可能的偏移,消除隔行扫描生成一个r2降低的分辨率地图。接下来对这些中间地图使用标准卷积,隔行扫描生成原始图像分辨率。将多孔卷积转换成常规卷积,这样我们就可以使用现有优化好的卷积例程。我们已经用TensorFlow框架实现了第二种方法。()
Multiscale Image Representations using Atrous Spatial Pyramid Pooling
我们实验了两种方法处理语义分割上的尺度变换。第一种方法是标准多尺度处理。我们用共享相同参数的并行DCNN分支,从多个(我们的实验里有3个)重新缩放尺度的原始图像中提取DCNN的的得分图。为了生成最后的结果,我们将并行的DCNN分支的特征映射进行双线性插值(到原图分辨率),并且融合它们,在不同尺度上获得每个位置的最大响应。在训练和测试时都这样做。多尺度处理明显增强了性能,但是需要对输入图像的多个尺度上在所有深度卷积神经网络层上计算特征响应。
第二种方法(受到何凯明大神SPP论文)中R-CNN空间金字塔池化方法成功的启发,任意一个尺度上的区域都可以用在这个单一尺度上重采样卷积特征进行精确有效地分类。我们实现了他们方法的一种变化形式,使用多个不同采样率上的多个并行多孔卷积层。每个采样率上提取的特征再用单独的分支处理,融合生成最后的结果。前面提到的“多孔空间金字塔池化”(DeepLab-ASPP)方法泛化了DeepLab-LargeFOV,如下图所示。

图4:多孔空间金字塔池化(ASPP)。为了分类中间像素(橙色),ASPP用不同采样率的多个并行滤波器开发了多尺度特征。视野有效区用不同的颜色表示。
Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery
准确定位和分类性能之间的权衡似乎是DCNN中固有的:模型越深,池化层越多,分类越成功,但是增加的不变性和顶层节点的大视野域只能产生平滑的响应。如图5所示(上上个图),DCNN的得分图只能预测物体的存在和粗略位置,但不能真正描绘他们的边界。
以前的工作追求两个方向来解决这一定位挑战。第一种方法是利用卷积网络中多层的信息来更好地估计物体边界(如FCN)。第二种是采用超像素表示(super-pixel representation),基本上将定位任务委托给低级别的分割方法。
我们将DCNN的识别能力与随机场优化的定位精度耦合在一起寻求解决方法,非常成功地处理定位挑战问题,产生了准确的语义分割结果并恢复了对象边界。
传统方法中,条件随机场(CRFs)用于平滑带噪声的分割图。通常,这些模型将邻近结点耦合(these models couple neighboring nodes),这样有利于将相同标签(label)分配给空间上接近的像素。定性的说,这些短程条件随机场基础函数会清除构建在局部手动特征上层弱分类器的错误预测。
与这些较弱的分类器相比,现代DCNN架构(例如我们在此工作中使用的架构)产生的得分图和语义标签预测在质量上是不同的。如图5所示,得分图通常非常平滑并产生均匀的分类结果。在这种情况下,使用short-range CRF可能是有害的,因为我们的目标应该是恢复详细的局部结构而不是进一步平滑它。用local-range CRFs关联中的反差灵敏势(constrast sensitive potentials),可以增强定位,但还是会漏掉细小结构,并且这种方法通常都需要处理离散优化问题(这种问题处理代价昂贵)。
为了克服short-range CRFs的局限性,我们在系统中整合了论文22的全连接随机场模型(fully connected CRF model)。模型使用了如下能量函数:

其中x是像素级的标签。我们将其用作单点势能θi(xi)=-log P(xi),其中P(xi)是DCNN计算的像素i处的标签分布概率。一对势能有相同的形式,可以用全连接图进行推理,比如,
连接图像像素所有配对,i,j。具体来说,如论文22,我们用如下表达式:
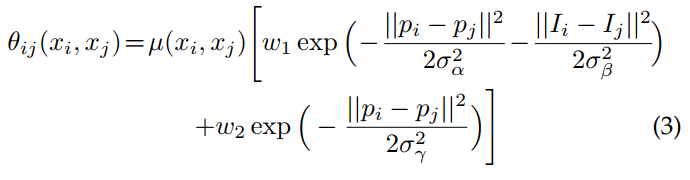
其中,如果xi≠xj,μ(xi,xj)=1,否则为0;在波茨模型(Potts model)中,只有显著标签的结点才会惩罚。表达式的剩下部分用了两个不同特征空间的高斯核;第一个是像素位置(记为p)和RGB颜色(记为I)间的双向核,第二个核是像素位置。超参数σασβσγ控制高斯核的尺度。第一个核强制相同和位置的像素具有相同的标记,第二个核在强制平滑时只考虑空间上的接近程度。
关键是,这个模型可以有效近似概率推理。在全分解平均场(under a full decomposable mean field)估计b(x)=Πi bi(x i)的信息传递更新可以表示成双边空间下的高斯卷积。高维滤波算法明显地加速了这个计算过程,使算法在实际中非常快,用论文22的实现方法,在PASCAL VOC图像上平均少于0.5秒。
参考博客:https://blog.csdn.net/GL_a_/article/details/80790463
扩展阅读,deeplabv3:https://blog.csdn.net/JYZhang_CVML/article/details/79587215
如何理解感受野:https://blog.csdn.net/chenyj92/article/details/53448161