教育或医学的标准情况是我们有一个持续的衡量标准,但随后我们对那些具有临床/实际意义的连续措施有了切入点。一个例子是BMI,我听到30个问题。您可以通过70分作为成绩测试进行成绩测试。当这种情况发生时,研究人员有时可能会对BMI模型超过30或通过/失败感兴趣。实质性问题通常属于模拟某人超过/低于该临床显着阈值的概率的线条。因此,我们使用逻辑回归等方法对连续测量进行二分,并分析新的二元响应。
回到介绍统计数据,你会听到这样的话:“不要将你的预测者分成两部分,你就会丢掉信息/差异/权力......”。当然,这同样适用于结果,并且大多数人宁愿使用常规线性回归而不是逻辑回归。但是,在上述情况中,我们经常因为实质性原因而将结果二分为二。
我发现了Moser和Coombs 1的2004 年医学统计学论文,标题为“几乎一年前的连续结果变量的优势比”,而不是二分法。我最近才仔细阅读。作者重申,当你将结果二分时,你会丢掉信息。并且它们表明你并不需要将结果二分为二,以获得优势比。关于这篇论文的好处是,在他们进入跨越几行的方程之前,这篇论文很容易理解。以下是摘要:
- 你认为,α + X β + ε = ÿ Çα+Xβ+ε=ÿC,其中y cÿC是一个连续的结果,即一些变量,XX,乘以它们的系数ββ,加上截距,αα,还有一些错误,εε,导致你的持续结果,y cÿC。
- 你相信一些门槛(t )(Ť)是临床意义重大,所以你削减y cÿC在tŤ这样y c的所有值ÿC超过tŤ现在是1,其他都是0; 我们称这个新变量为y bÿb。
- 然后,您在y b上执行逻辑回归ÿb,这确实是仅仅检索原始模型的尝试,α + X β + ε = ÿ Çα+Xβ+ε=ÿC。为什么不直接模拟y cÿC?
关于这一点,有几点值得一提:
- 我们可以总结如下:y b = 1我˚Fα + X β + ε > 吨ø 吨ħ é ř 瓦特我小号Ëy b =0ÿb=1一世Fα+Xβ+ε>ŤØŤHË[Rw ^一世小号Ëÿb=0。
- 如果我们调整阈值,比如说1点放弃它,它不会改变X βXβ,它只影响截距:y b = 1我˚Fα - 1个+ X β + ε > 吨- 1ÿb=1一世Fα- 1+Xβ+ε>Ť- 1
- 这里指出,通过改变阈值影响的唯一系数是截距αα; 在ββ不受调整阈值的影响。所以我们关心的关系不受阈值的影响-- 稍后会详细介绍。
- 最后,在逻辑回归中,我们不估计εε,我们假设它是标准的物流。这会影响到如果我们想在y c上使用线性回归ÿC要从逻辑回归中获得结果,我们需要做一些调整。2
所以这是他们的建议:
- 估计连续结果的线性模型,y cÿC
- 你的系数是ββ,然后变换它们:π σ × √ 3β其中 σ = 回归的残差标准差πσ×3β哪里 σ= 回归的残差标准差
- 这些是您的对数赔率,您可以对它们进行取幂以获得优势比。
- 我们不关心这个线性回归的截距,因为它会受到阈值的影响,我们正在使用一种对阈值视而不见的方法。
那么这种方法在实践中如何运作?任何尝试在使用逻辑回归进行分析之前在不同阈值下对连续变量进行二分法的人都会知道估计的系数会发生变化并且可能会发生很大变化!这是否与声称结果不应取决于阈值一致?我们可以使用模拟检查。首先,我将介绍数据生成过程:
set.seed(12345) # Set seed for reproducible results
# Our single x variable is binary with 50% 0s and 50% 1s
# so like random assignment to treatment and control
# Our sample size is 300
dat <- data.frame(x = rbinom(300, 1, .5))
# Outcome ys = intercept of -0.5, the coefficient of x is 1 and there is logistic error
dat$yc <- -.5 + dat$x + rlogis(nrow(dat))
yc 看起来像:
hist(dat$yc, main = "")
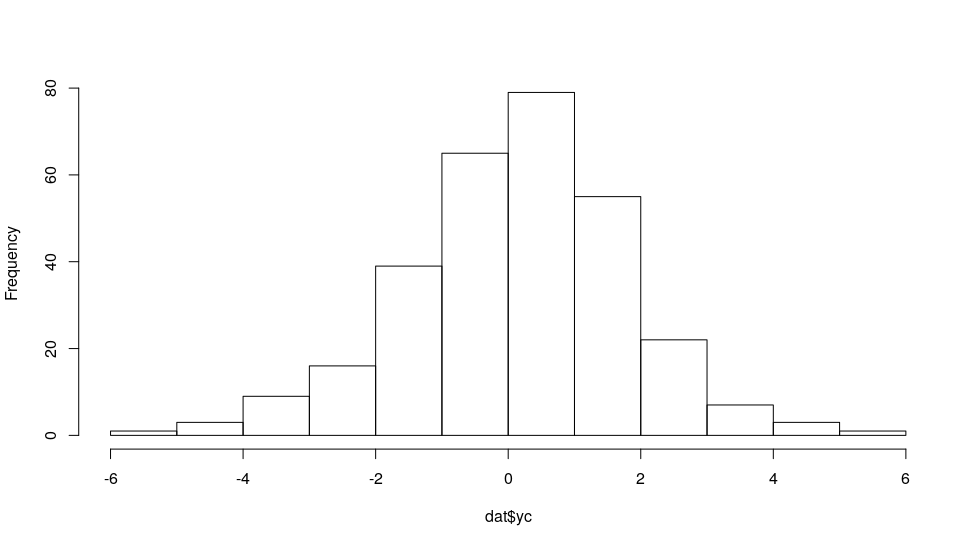
![]()
然后,我们可以yc在不同点上对结果进行二分,以确定这是否会影响x我们使用逻辑回归的估计系数:
coef(glm((yc > -2) ~ x, binomial, dat))["x"] # Cut it at extreme -2
x
0.9619012
coef(glm((yc > 0) ~ x, binomial, dat))["x"] # Cut it at midpoint 0
x
1.002632
coef(glm((yc > 2) ~ x, binomial, dat))["x"] # Cut it at extreme 2
x
0.8382662
所以数字有点不同。如果我们yc直接应用线性回归怎么办?
# First, we create an equation to extract the coefficients and
# transform them using the transform to logit formula above.
trans <- function (fit, scale = pi / sqrt(3)) {
scale * coef(fit) / sigma(fit)
}
trans(lm(yc ~ x, dat))["x"]
x
1.157362
所有这些数字彼此并没有太大的不同。如果我们取得它们以获得比值比,它们会更加不同。现在我们可以多次重复此过程来比较结果中的模式。我会重复2500次:
colMeans(res <- t(replicate(2500, {
dat <- data.frame(x = rbinom(300, 1, .5))
dat$yc <- -.5 + dat$x + rlogis(nrow(dat))
# v for very; l/m/h for low/middle/high; and t for threshold; ols for regular regression
c(vlt = coef(glm((yc > -2) ~ x, binomial, dat))["x"],
lt = coef(glm((yc > -1) ~ x, binomial, dat))["x"],
mt = coef(glm((yc > 0) ~ x, binomial, dat))["x"],
ht = coef(glm((yc > 1) ~ x, binomial, dat))["x"],
vht = coef(glm((yc > 2) ~ x, binomial, dat))["x"],
ols = trans(lm(yc ~ x, dat))["x"])
})))
vlt.x lt.x mt.x ht.x vht.x ols.x
1.0252116 1.0020822 1.0049156 1.0101613 1.0267511 0.9983772
这些数字是不同方法的平均回归系数。
v代表非常,l / m / h代表低/中/高,t代表阈值,ols是回归结果。因此,例如,vlt.x是来自极低阈值模型的平均x系数。
对于所有方法,这些估计系数平均为约1,这是我们编程的,好的!每种方法的变量如何?
boxplot(res)
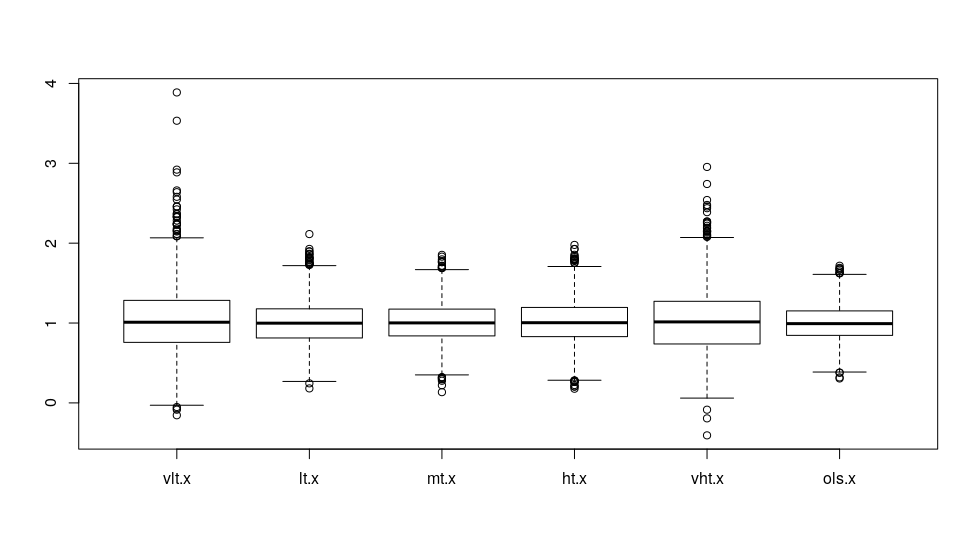
![]()
我们看到虽然平均值大致相同,但当阈值极端时,估计的系数变化更大。最小变量系数是变换后的线性回归系数,因此当我们使用线性回归方法时,结果有些稳定。阈值越极端,我们得到的变量系数就越多。这很有趣,因为我们经常将极端情况下的逻辑回归数据二分。
不同方法之间的估计系数模式如何?
GGally::ggpairs(as.data.frame(res))
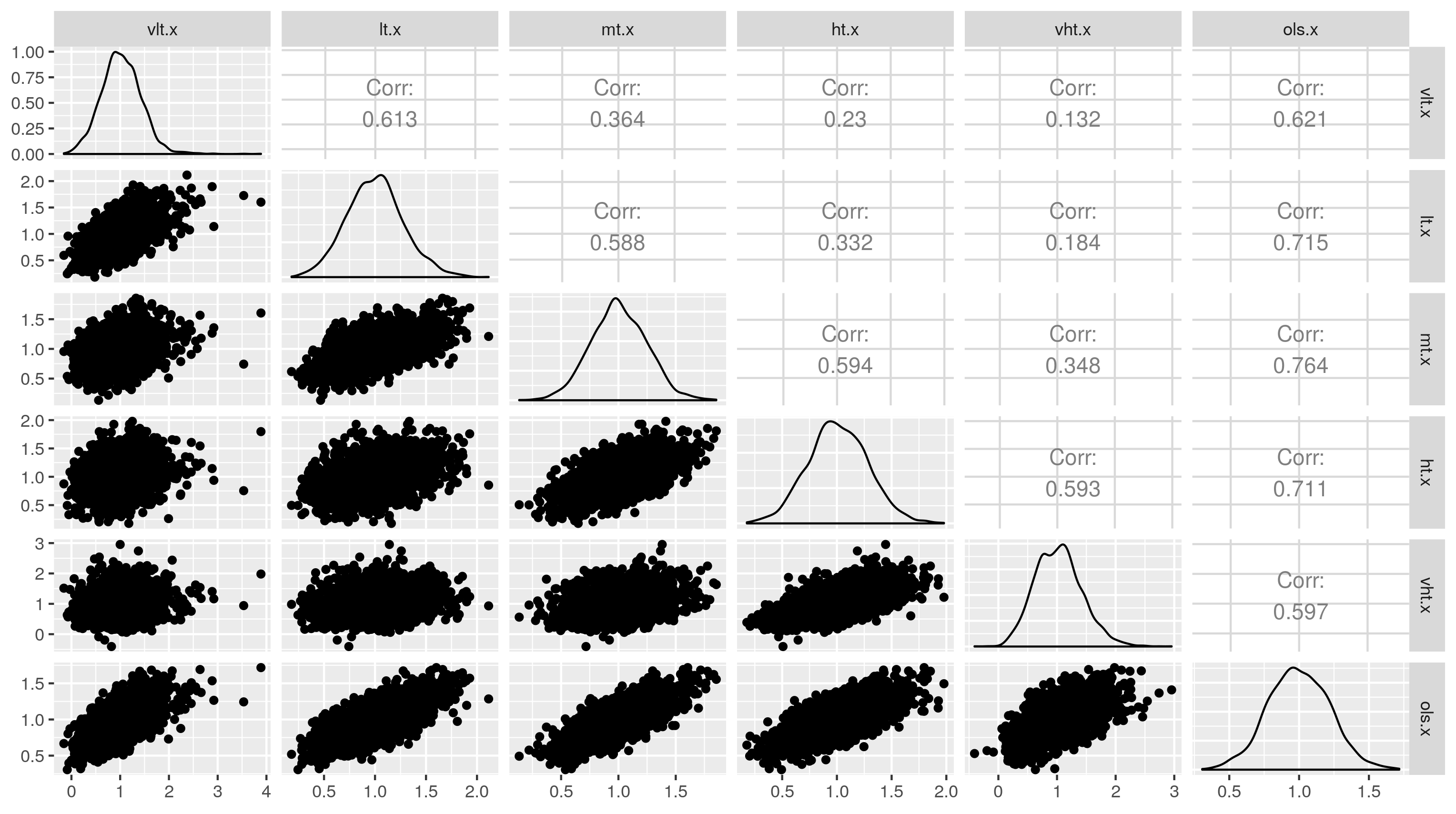
![]()
我们看到尽管所有方法声称平均x系数为1 y,但是当阈值非常低时估计系数与阈值非常高时的估计系数非常弱相关(.13)。这些差异只是反映了阈值,在实际数据分析中可能会产生误导。人们可能认为,不同阈值的广泛不同的估计表示不同的人口参数(真实系数)。每种方法最高度相关的方法是线性回归方法。线性回归方法与中间阈值结果最强相关。它也是最稳定的,似乎没有偏见。
基于这些结果,人们可能认为我们应该始终对连续变量进行建模,然后使用Moser和Coombs的公式转换我们的系数,如果我们想要对数几率和/或比值比。Moser和Coombs得出了这个结论。
实质上,当数据在极端阈值下被二分时,我们是否应该相信这些发现?或者我们应该使用变换的线性回归系数?
预测因子与结果之间的关系也可能因结果的不同分位数而不同--分位数回归探讨的情况。可以使用分位数回归方法来查看原始连续结果中是否存在这种情况。
有问题吗?联系我们!
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() QQ:3025393450
QQ:3025393450


![]()
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询服务
![]()
