一次次的成绩滑坡,一次次的作业爆炸,觉得自己在下坡路上狂飙。每个单元都会有两次假象,前两次成绩还差强人意,第三次要不就是C组,这次甚至连C组都进不去了,还是对自己要求不严格,还是课下功夫不足!我反思!
梳理JML语言的理论基础、应用工具链情况
基本概念
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言,是一种行为接口规格语言。
一般而言,JML有两种用法:
-
开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
-
针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性,这在遗留代码的维护方面具有特别重要的意义。
基础语法整理
-
规格的注释方式:// @annotation 或者 /* @ annotation @ */;
-
requires 字句定义前置条件,即需要满足的条件;
-
assignable 列出此方法能够修改的类成员属性,不修改任何元素用\nothing,表示这是一个pure方法;
-
ensures字句定义后置条件,即调用方法后达到的效果;
-
规格的每个字句必须以分号结尾,否则JML工具无法解析;
-
表达式
-
\result表达式,即非void类型的方法执行后的返回值。
-
\old(expr)表达式,用来表示一个表达式在相应方法执行前的取值。
-
\forall表达式,全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
-
\exists表达式,存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
-
\sum表达式,返回给定范围内的表达式的和。
-
\max表达式,返回给定范围内的表达式的最大值。
-
\min表达式,返回给定范围内的表达式的最小值。
-
-
操作符
-
等价关系操作符:b_expr1<==>b_expr2或者b_expr1<=!=>b_expr2。
-
推理操作符:b_expr1==>b_expr2或者b_expr2<==b_expr1。
-
-
方法的正常行为和异常行为
-
正常功能:public normal_behavior
-
also
-
异常功能:public exceptional_behavior
-
signals字句:signals(Exception e) b_expr,当b_expr为true时,抛出括号中对应异常。
-
signals_only字句:signals_only 异常类型,表示满足前置条件时抛出相应异常。
-
应用工具链情况
-
使用OpenJML对实现的代码进行检查。
-
JML语法静态检查:给出JML语言上的语法错误。
-
程序代码静态检查:给出程序中可能存在的潜在问题。
-
运行时检查
-
-
使用JMLUnitNG根据JML语言自动生成TestNG测试。
-
基于JML生成测试文件
-
利用OpenJML的rac,生成含有运行时检查的特殊.class文件并替换原文件
-
运行TestNG测试。
-
部署SMT Solver,至少选择3个主要方法来尝试验证,报告结果(有可能要补充JML规格)
部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例(
按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
由于自己第三次作业提交的代码取得0分,所以自己在bug修复阶段自主重构了代码,本部分的分析基于重构代码来说(写的0分的代码自己都不想看了)关于0分的错误代码,我在第五部分bug分析部分来稍加阐述。
总体分析
和以往的单元作业一样,本单元的三次作业是一个层层递进且相互关联的作业结构,而且如果从开始就架构搭的好的话之后的作业实现起来改动应该非常小。当然这只是理想状态,我本人自然是重构一时爽,一直重构一直爽


由上图可以发现,三次作业要求我们实现的类均是继承的已有jar包的接口,也就是说我们必须实现继承接口中的所有方法。本单元作业偏向掌握规格设计,所有方法的规格说明均以给出,再加上指导书的说明,所以理解每个方法的实现思路并不难,关键在于如何具体实现。
简单举例,我们要实现的方法中有许多查询方法,如果每次查询时都重新计算一下,时间复杂度必然增加,而由数据限制可以发现,add或remove这种的图结构变更指令很少,所以应将时间复杂度分散到本就无法降低复杂度的写指令以及线性复杂度指令中,将之前计算出来的部分中间结果保存下来,以减少后续的计算复杂度。这就意味着在我们实现的方法中,按照规格要求的方法确实需要实现,但我们的实现可能并没有放到此方法中,此方法可能只是一个简单的输出(或return)操作,真正要求实现的操作分散到其他指令中实现。
其中,MyPath类在三次作业中几乎没有变化(只有在第三次作业为MyPath类增加了计算不满意的度的一个方法),而从第一次作业要求实现的MyPathContainer类到第二次作业的MyGraph类到第三次作业的MyRailwaySystem类,这三个类的实现均是建立在上个实现类的基础之上,因而所以说三次作业有很紧密的关联。
三次作业始终贯彻的方法
-
将时间复杂度分散到本就无法降低复杂度的增删指令以及线性复杂度指令中,将之前计算出来的部分中间结果保存下来,以减少后续的计算复杂度。
-
查询指令十分简单,只是返回一个计算好的结果,所有复杂和易错的点全在于add和remove时对现有数据结构的维护,尤其是remove指令,
可能涉及到推倒重来的一个过程。 -
node的范围是整个INT,因而为所有的节点(node)建立到点的序号(nodeId)的映射关系,类似path和pathId的映射关系,方便构建邻接矩阵等。
-
增删指令中涉及到对点和边的改动。add指令先增点,再增边,因为这样才能建立点(node)和点的序号(nodeId)之间的映射关系,然后再增加边;相反,remove时先删边,再删点,以防在删边的过程中点已不存在使得异常。
三次作业架构的重构
-
自己有个地方掌握的非常不好,就是在多个类要维护同一个数据结构时,总觉得将数据结构在不同类之间相互传递有些麻烦,而且又由于这三次作业每个类的代码量均没有达到超过500行的代码量,所以在之前作业的类中实现的方法我是采用了复制粘贴到新的类中作为方法实现。
-
三次作业中实现的MyPath类均没有变化,直接延续下来。(第三次作业新增方法计算不满意度但很简单实现)
-
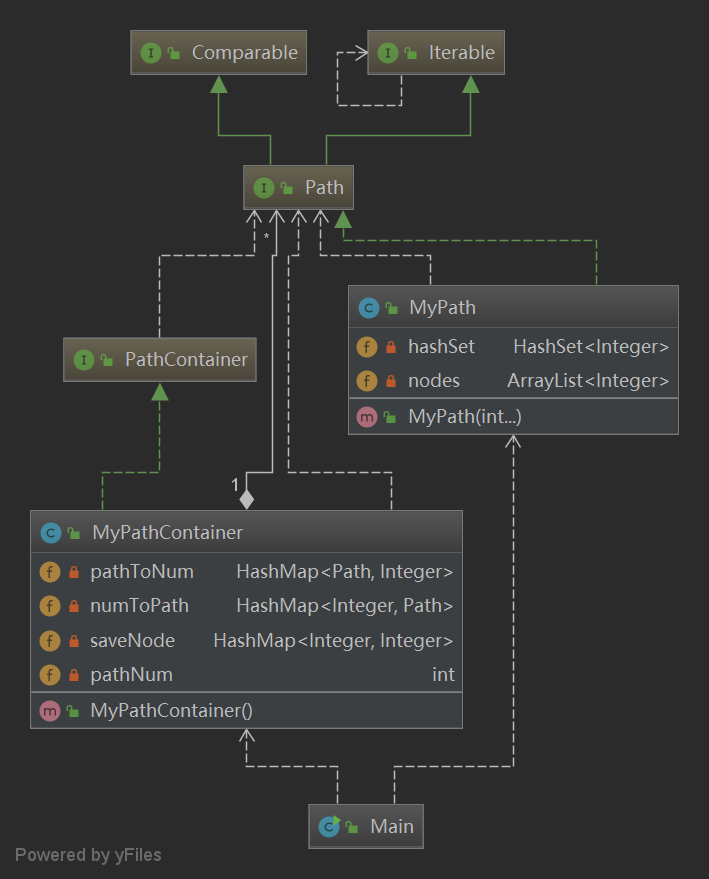
第一次作业实现的MyPathContainer类中实现的方法直接延续到第二次作业中的MyGraph类中。
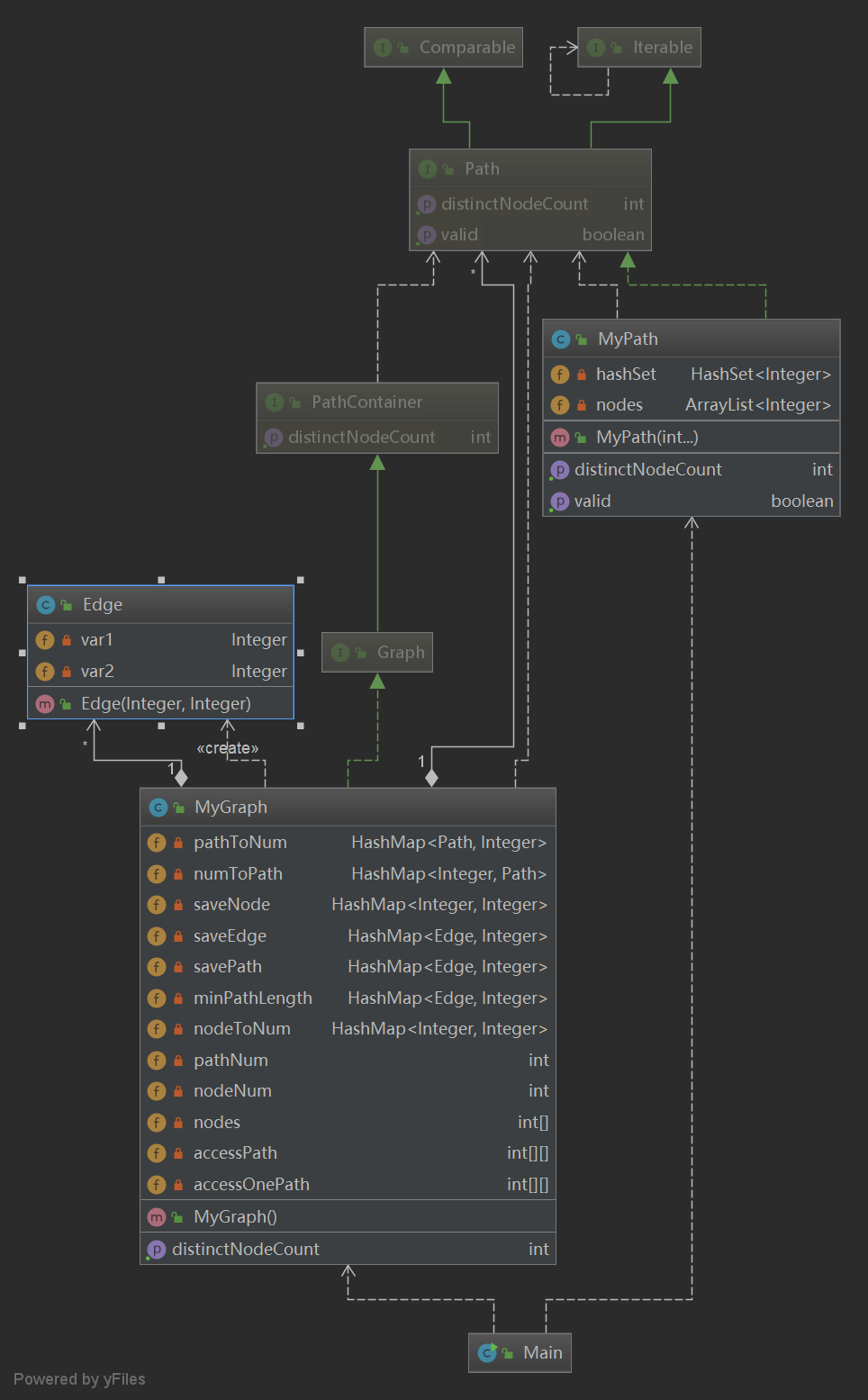
然后由于第二次作业新增要求,我在第一次作业实现的数据结构基础上新增数据结构来实现新的要求,并且自己在第二次作业中自己重新定义一个Edge类来记录边的信息。
第一次作业的数据结构
-
HashMap<Integer, Path> numToPath; // <pathId, path>
-
HashMap<Path, Integer> pathToNum; // <path, pathId>
-
HashMap<Integer, Integer> saveNode; // <node, nodeCount>
第二次作业新增数据结构
-
HashMap<Edge, Integer> saveEdge; // 记录所有不重复的边及出现次数
-
HashMap<Edge, Integer> savePath; // 记录所有的可达路径及出现次数
-
HashMap<Edge, Integer> minPathLength; // 记录所有路径的最短长度
-
HashMap<Integer, Integer> nodeToNum; // 记录节点和节点序号的映射关系
-
int[] nodes; // 记录节点序号和节点的映射关系
-
int[][]accessPath; // 可达矩阵 -
int[][]accessOnePath; // 邻接矩阵
-
-
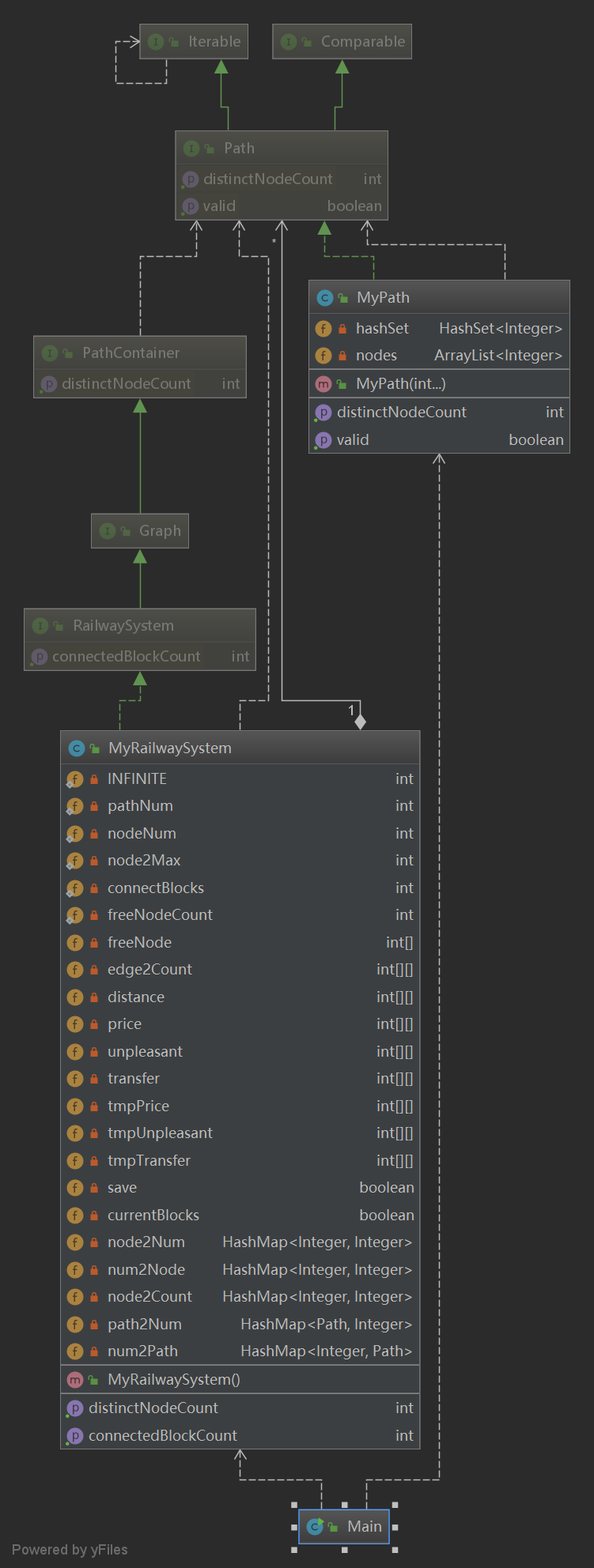
数据结构方面,第三次作业和第二次作业相比,没有minPathLength数据结构,路径的最短长度是通过distance数组来记录的;没有accessPath和accessOnePath数据结构,这两个结构体的作用也是通过判断对应distance数组中的元素是否是无穷大(初始化为INFINITE)来判断。同时还有些微小的改动,比如将saveEdge更名为edge2Count等等。
-
方法实现方面,第二次作业中一些简单的查询方法比如getPathById此类的可以在第三次作业中直接复用,另外比较主要的一个方法是获得最短路径长度,自己在第二次作业中采用的是通过bfs算法计算最短路径长度,在我提交的零分程序中此方法也直接复用,之后添加了一些新增请求的计算方法,但在之后的重构代码中,由于其他查询指令都是通过floyd算法实现的,因而为实现一种算法、不同建图方式的统一,计算最短路径长度也更新为Floyd算法。add和remove指令涉及到数据结构的维护,自然需要重写。
第三次作业新增数据结构
-
int[][]distance // 距离矩阵 -
int[][]price // 记录两个站点间的最少票价 -
int[][]unpleasant // 记录两个站点间的最少不满意度 -
int[][]transfer // 记录两个站点间的最少换乘 -
int[][]tmpPrice // 临时记录本路径中涉及到的最短票价 -
int[][]tmpUnpleasant // 临时记录本路径中的最少不满意度 -
int[][]tmpTransfer // 临时记录本路径中的最少换乘 -
tmp数组临时变量其实放到方法体里面也可
-
第一次作业

第二次作业

第三次作业

按照作业分析代码实现的bug和修复情况
第一次作业强测和互策均为出现bug;
第二次作业由于remove时忘记对邻接矩阵相应的数组元素清零导致强测炸掉两个点;
第三次作业惨不忍睹,我甚至不能理解这样混乱的程序怎么能过中测
-
在add和remove时我为相应的布尔型变量ifAddNewNode和ifDeleteNewNode赋真值,然后在相应的访问查询时再判断是否更新,但有些需要计算更新矩阵的地方没有更新
-
在add和remove时对矩阵的更新是分开处理的,remove时是重新遍历删完后存在的所有路径然后重新构建矩阵,add时以为不需要像remove一样复杂,所以只更新了新增路径涉及到的点和边,但更新过程中由于缺少和现有元素大小的判断导致错误
-
在remove后对删除点所在的邻接矩阵的一行(列)时,对矩阵其余行(列)的移动出现问题
-
remove时没有对nodeToPathNum(拆点后节点和序号的映射关系的Hash Map)数据结构清空
-
上面的错误都改正后,重新提交,第一个点AC,其余点或RUNTIME_ERROR或CPU_TIME_LIMIT_EXCEED,我把第二组数据下载下来和我的输出比对,结果完全一样,但耗时太长。判断:正确性在修改上述地方后得到很大改善(可能还存在一些没有改到的错误),但时间复杂度太高。
在周二提交作业出互测结果前我把我的程序发给同学信心满满地对拍,然后……他说我的程序跑一个5000行的测试数据跑了二十多分钟,我的内心是崩溃的(他还十分气愤地让我赔他电脑,我能脑补出电脑一直呼呼响的场景) -
这样缝缝补补,使得本来混乱的代码更加不堪入目!于是,我果断采取了最为暴力的一种方法,重构!一天半的时间,我写出了一份令我满意的代码!
-
大方法修改,从拆点法改为不拆点法(其实我最开始使用的不拆点法,但在周一晚上看到群里和讨论区有大佬讨论不拆点法复杂度太高,于是匆忙之下换方法,换成的拆点法,结果长时间的思考化为乌有,在这种方法下我的程序漏洞百出,后来实际证明大佬的不拆点方法其实跑的很快,但我怨不得别人,我自己没有仔细思考复杂度,就该是这样的惩罚!)
-
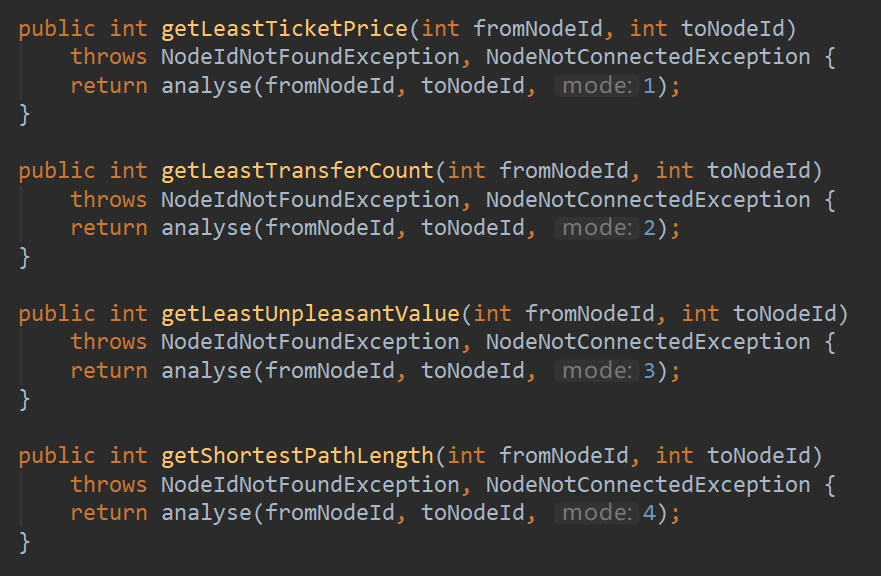
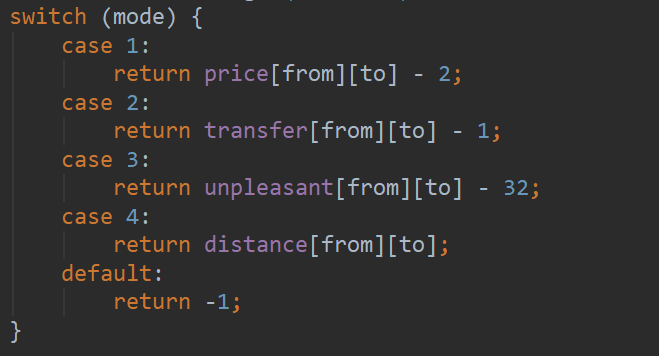
大方法修改,所有查询指令统一建模,使用统一的Floyd算法计算更新矩阵,如下图所示。
-
经过代码重构后,顺利通过所有测试点!程序跑的也很快!哭了
阐述对规格撰写和理解上的心得体会
正如开头提到的JML语言的两种用法,规格相比自然语言描述无歧义,逻辑更加完整,对一项长期需要维护的工程来说,方便了后期工作人员的维护工作。简单来说,规格增强代码的可读性,也使得代码的规范性更加好。
尽管规格有众多好处,但似乎规格应用的并不是非常广泛。而且规格不是轻易就写出来的,其实,写规格的过程本身就是一个构建代码框架的过程,自己也曾尝试写规格,刚开始是语法报错,到后面是刚开始写的规格和后面自己代码实现过程中有些冲突,甚至需要改规格。尽管现在,规格的语法我也没有掌握清楚,只能写一些基本的规格,但深究老师最后一次讲的类规格等等,确实有些难度。
本单元作业要求实现的功能代码规格均以给出,在实现的过程中其实是减少了思考的工作量,但我们也能很清晰的感觉到,规格只是说明了此方法实现的功能是什么,以及对前置条件和后置条件、结果等等做了限制,但中间方法具体要怎么实现其实还是要自己构思。(当然不考虑时间复杂度就不用管这么多了)
在本次撰写博客的过程中,我是第一次尝试JMLUnitNG,但效果并不是很理想,单单是安装过程就出现了许多问题,而且似乎其本身也并不完善,因而我觉得有些时候为了要刻意满足甚至会为程序员增加束缚,OpenJML可以检查简单的JML语法以及错误,但这些工具不要过分依赖(也依赖不起来),规格是给程序员看的,他能增加代码可读性,但测试等工作还是要自己来,不能完全依靠工具。
附三次作业的复杂度分析:
第1次作业
| Class | OCavg | WMC |
|---|---|---|
| Main | 1 | 1 |
| MyPath | 1.9 | 19 |
| MyPathContainer | 2.7 | 27 |
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| Main.main(String[]) | 1 | 1 | 1 |
| MyPath.MyPath(int...) | 1 | 2 | 2 |
| MyPath.compareTo(Path) | 4 | 3 | 5 |
| MyPath.containsNode(int) | 1 | 1 | 1 |
| MyPath.equals(Object) | 5 | 2 | 6 |
| MyPath.getDistinctNodeCount() | 1 | 1 | 1 |
| MyPath.getNode(int) | 1 | 1 | 1 |
| MyPath.hashCode() | 1 | 1 | 1 |
| MyPath.isValid() | 1 | 1 | 1 |
| MyPath.iterator() | 1 | 1 | 1 |
| MyPath.size() | 1 | 1 | 1 |
| MyPathContainer.MyPathContainer() | 1 | 1 | 1 |
| MyPathContainer.addPath(Path) | 3 | 5 | 6 |
| MyPathContainer.containsPath(Path) | 2 | 1 | 2 |
| MyPathContainer.containsPathId(int) | 1 | 1 | 1 |
| MyPathContainer.getDistinctNodeCount() | 1 | 1 | 1 |
| MyPathContainer.getPathById(int) | 2 | 1 | 2 |
| MyPathContainer.getPathId(Path) | 4 | 1 | 4 |
| MyPathContainer.removePath(Path) | 4 | 3 | 6 |
| MyPathContainer.removePathById(int) | 2 | 3 | 4 |
| MyPathContainer.size() | 1 | 1 | 1 |
第二次作业
| Class | OCavg | WMC |
|---|---|---|
| Edge | 1.67 | 5 |
| Main | 1 | 1 |
| MyGraph | 4.05 | 77 |
| MyPath | 1.9 | 19 |
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| Edge.Edge(Integer,Integer) | 1 | 1 | 1 |
| Edge.equals(Object) | 3 | 2 | 5 |
| Edge.hashCode() | 1 | 1 | 1 |
| Main.main(String[]) | 1 | 1 | 1 |
| MyGraph.MyGraph() | 1 | 1 | 1 |
| MyGraph.add(Path) | 1 | 11 | 11 |
| MyGraph.addPath(Path) | 3 | 3 | 4 |
| MyGraph.breadthFirstSearch() | 6 | 10 | 17 |
| MyGraph.containsEdge(int,int) | 1 | 1 | 1 |
| MyGraph.containsNode(int) | 1 | 1 | 1 |
| MyGraph.containsPath(Path) | 2 | 1 | 2 |
| MyGraph.containsPathId(int) | 1 | 1 | 1 |
| MyGraph.getDistinctNodeCount() | 1 | 1 | 1 |
| MyGraph.getPathById(int) | 2 | 1 | 2 |
| MyGraph.getPathId(Path) | 4 | 1 | 4 |
| MyGraph.getShortestPathLength(int,int) | 5 | 2 | 5 |
| MyGraph.isConnected(int,int) | 4 | 1 | 4 |
| MyGraph.remove(Path) | 1 | 6 | 6 |
| MyGraph.removeEdge(Path) | 1 | 5 | 5 |
| MyGraph.removeNode(Path) | 1 | 4 | 10 |
| MyGraph.removePath(Path) | 4 | 1 | 4 |
| MyGraph.removePathById(int) | 2 | 1 | 2 |
| MyGraph.size() | 1 | 1 | 1 |
| MyPath.MyPath(int...) | 1 | 2 | 2 |
| MyPath.compareTo(Path) | 4 | 3 | 5 |
| MyPath.containsNode(int) | 1 | 1 | 1 |
| MyPath.equals(Object) | 5 | 2 | 6 |
| MyPath.getDistinctNodeCount() | 1 | 1 | 1 |
| MyPath.getNode(int) | 1 | 1 | 1 |
| MyPath.hashCode() | 1 | 1 | 1 |
| MyPath.isValid() | 1 | 1 | 1 |
| MyPath.iterator() | 1 | 1 | 1 |
| MyPath.size() | 1 | 1 | 1 |
第三次作业
| Class | OCavg | WMC |
|---|---|---|
| Main | 1 | 1 |
| MyPath | 2.45 | 27 |
| MyRailwaySystem | 3.37 | 91 |
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| Main.main(String[]) | 1 | 1 | 1 |
| MyPath.MyPath(int...) | 1 | 2 | 2 |
| MyPath.compareTo(Path) | 4 | 3 | 5 |
| MyPath.containsNode(int) | 1 | 1 | 1 |
| MyPath.equals(Object) | 5 | 2 | 6 |
| MyPath.getDistinctNodeCount() | 1 | 1 | 1 |
| MyPath.getNode(int) | 1 | 1 | 1 |
| MyPath.getUnpleasantValue(int) | 8 | 2 | 8 |
| MyPath.hashCode() | 1 | 1 | 1 |
| MyPath.isValid() | 1 | 1 | 1 |
| MyPath.iterator() | 1 | 1 | 1 |
| MyPath.size() | 1 | 1 | 1 |
| MyRailwaySystem.MyRailwaySystem() | 1 | 1 | 3 |
| MyRailwaySystem.addPath(Path) | 3 | 7 | 9 |
| MyRailwaySystem.analyse(int,int,int) | 10 | 3 | 11 |
| MyRailwaySystem.bfs() | 3 | 3 | 9 |
| MyRailwaySystem.calculate() | 1 | 1 | 1 |
| MyRailwaySystem.containsEdge(int,int) | 2 | 2 | 3 |
| MyRailwaySystem.containsNode(int) | 1 | 1 | 1 |
| MyRailwaySystem.containsPath(Path) | 2 | 2 | 2 |
| MyRailwaySystem.containsPathId(int) | 1 | 1 | 1 |
| MyRailwaySystem.floyd(int) | 5 | 1 | 7 |
| MyRailwaySystem.getConnectedBlockCount() | 1 | 2 | 2 |
| MyRailwaySystem.getDistinctNodeCount() | 1 | 1 | 1 |
| MyRailwaySystem.getLeastTicketPrice(int,int) | 1 | 1 | 1 |
| MyRailwaySystem.getLeastTransferCount(int,int) | 1 | 1 | 1 |
| MyRailwaySystem.getLeastUnpleasantValue(int,int) | 1 | 1 | 1 |
| MyRailwaySystem.getPathById(int) | 2 | 1 | 2 |
| MyRailwaySystem.getPathId(Path) | 2 | 3 | 4 |
| MyRailwaySystem.getShortestPathLength(int,int) | 1 | 1 | 1 |
| MyRailwaySystem.getUnpleasantValue(Path,int,int) | 2 | 2 | 2 |
| MyRailwaySystem.ifFreeNodeContainsNode(int) | 3 | 1 | 3 |
| MyRailwaySystem.isConnected(int,int) | 4 | 2 | 5 |
| MyRailwaySystem.remove(Path,int) | 1 | 4 | 8 |
| MyRailwaySystem.removePath(Path) | 4 | 1 | 4 |
| MyRailwaySystem.removePathById(int) | 2 | 1 | 2 |
| MyRailwaySystem.size() | 1 | 1 | 1 |
| MyRailwaySystem.updateAdd(Path) | 1 | 2 | 11 |
| MyRailwaySystem.updateAll() | 1 | 2 |