面向对象课程序设计第三单元总结
• 1>.梳理JML语言的理论基础、应用工具链情况
何谓JML语言?
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言 (Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义 手段。所谓接口即一个方法或类型外部可见的内容。
JML的两种主要用法:
(1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
(2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
JML语言的具体用法:
首先大体上分为 三部分——前置、过程、后置。
前置: requires 子句定义了需要满足的条件。
过程: assignable 子句定义了可以改变的成员。
后置: ensures 子句定义了方法要达到的效果。
其中子句中会用到各种表达式,常用的一些大致如下:
\result 表示返回结果, \old 表示方法执行前成员的状态;

\forall :全称量词修饰的表达式, \exists :存在量词修饰的表达式;
public normal_behavior 表示接下来的部分对 方法的正常功能给出规格;
public exceptional_behavior 表示接下来的部分对 方法的异常功能给出规格;
JML应用工具链:
关于JML工具,即在JML语言和具体实现java代码都已经完成之后,对其规格正确性的检验。包括OpenJml、SMT Solver、JML UnitNG等。
• 2>.部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例(简单方法即可,如果依然存在困难的话尽力而为即可,具体见更新通告帖), 并结合规格对生成的测试用例和数据进行简要分析
大概的JMLUnitNG使用方法过程:
生成JML测试文件:

编译测试用文件和MyPath文件:


执行测试操作:

最后得到结果:

有部分方法测试失败。
• 3>.三次作业的架构、实现、Bug修复
第一次作业:
架构:
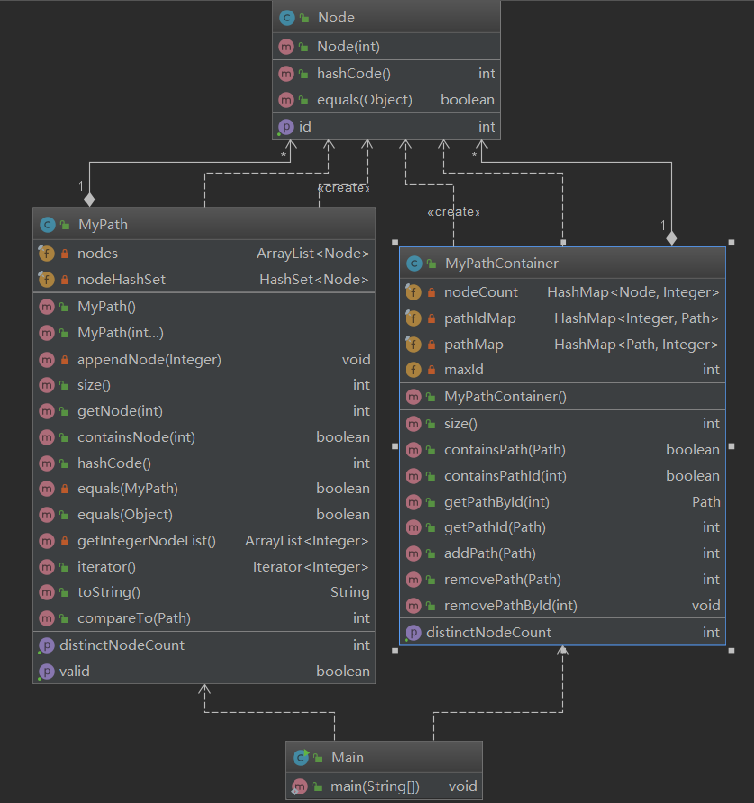
复杂度:
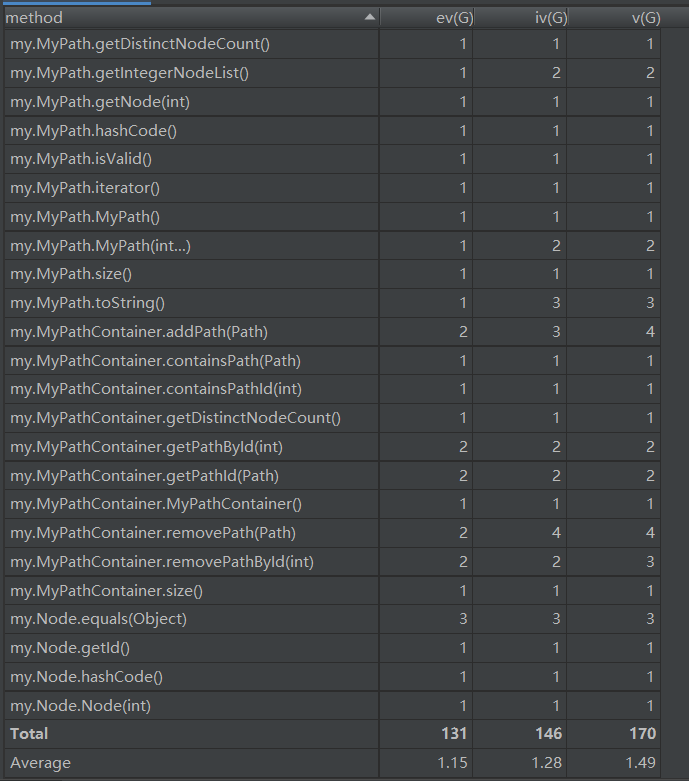
关于第一次作业,比较简单也没什么变化空间,方法方面按照JML语言完成代码。
其他一些具体实现:
MyPath方法使用ArrayList、HashSet双容器:(这是跟其他人学的,后来发现没有什么用,在第二次作业中更换回去了。
private final ArrayList<Node> nodes; private final HashSet<Node> nodeHashSet;
几乎所有实现都在第二次作业中继承了,具体在第二次作业部分分析,此处略。
作业2:
架构:
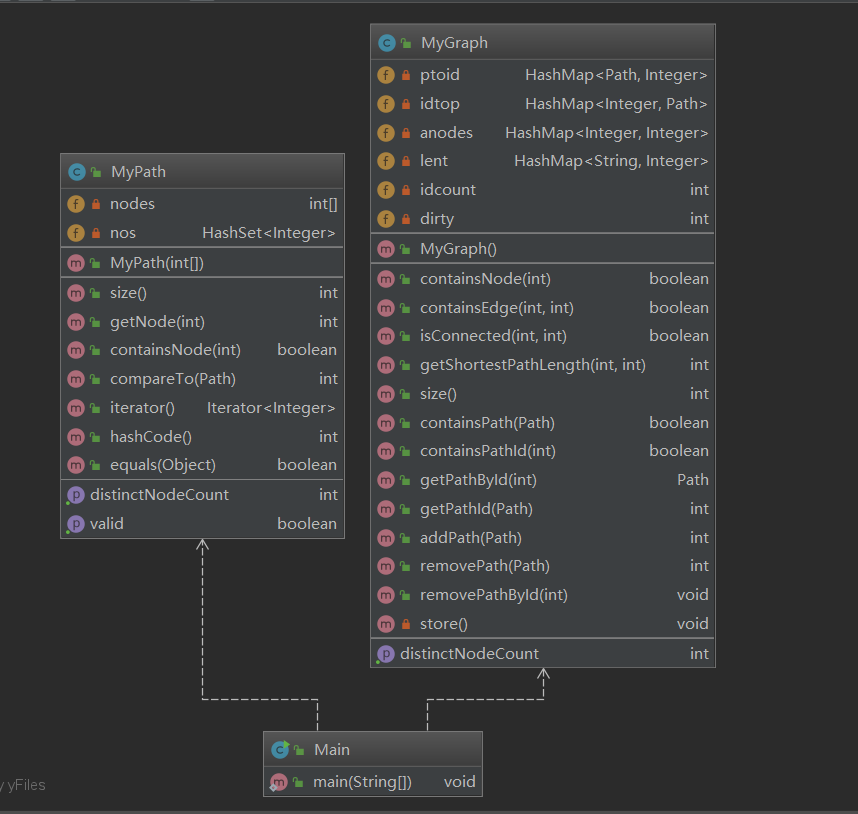
复杂度分析:

我们看到此处MyPath的compareTo方法严重过多。同时这个方法内部具有一层循环,这也可能是我后期超时的原因之一。
具体方法分析:
关于MyPath,感觉ArrayList没必要,而且还要从已经存在的数组存入新开的ArrayList,故而直接用普通的数组代替,同时另外使用一个HashSet容器。在寻找是否存在时使用HashSet,在根据地址取值的时候用数组。
关于MyGraph,成员部分使用了四个HashMap与两个int变量:
1 private HashMap<Path,Integer> ptoid = new HashMap<>(); 2 private HashMap<Integer,Path> idtop = new HashMap<>(); 3 private HashMap<Integer,Integer> anodes = new HashMap<>(); 4 private HashMap<String,Integer> lent; 5 private int idcount = 1; 6 private int dirty = 0;
ptoid和idtop分别是路径对编号的映射与编号对路径的映射。
anodes是路径结点对它出现次数的映射。这是为了存入所有存在的路径结点并且方便路径增删。
lent是字符串对数值的映射,字符串在下面定义,格式如(fromNodeId+"+"+toNodeId) 也即两个结点中间以加号相连,后面的数值则表示这两个结点的最短距离。
idcount是在新增路径是为新路径标号所用。
dirty则表示目前是否有新路径增删操作。在执行add、remove操作后置1,在执行store()方法后置0;
store()方法是本次作业的核心方法,它的用途是更新lent哈希图,计算当前所有结点之间的最短距离。具体如下:
1 private void store() { 2 lent = new HashMap<>(); //将原有HashMap抛弃重新声明一个(因为添加与删除操作的复杂度远高于重新建立) 3 for (Map.Entry<Integer,Integer> entry : anodes.entrySet()) { //第一层循环,anodes里的所有结点提取 4 int b = entry.getKey(); 5 ArrayList<Integer> flist = new ArrayList<>(); //建立ArrayList flist 6 HashSet fset = new HashSet(); //建立HashSet fset
7 ArrayList<Integer> faths = new ArrayList<>(); //建立ArrayList faths 8 int temp = 0; //遍历结点 temp 9 int last = 0; //尾节点 last 10 flist.add(b); //将当前路径结点加入flist表示起始结点 11 fset.add(b); //双容器,fet和flist操作相同 12 faths.add(0); //将当前结点与起始结点的距离放入faths(当前为0) 13 int flag; //距离标志,初始为0 14 while (temp <= last) { //循环,当遍历结点在尾节点之前时继续循环 15 flag = faths.get(temp) + 1; //距离+1(因为下面的循环寻找与当前结点有边的结点,如此它和起始结点的距离即是当前结点与起始结点的距离+1) 16 for (Map.Entry<Integer,Integer> entry2 : anodes.entrySet()) {//二层循环,对所有结点的循环 17 int a = entry2.getKey(); 18 if (!fset.contains(a) && containsEdge(flist.get(temp),a)) {//当存在边且这个结点尚未被加入过容器(没有统计过即没有更近的距离) 19 flist.add(a); //置入双容器 20 fset.add(a); 21 faths.add(flag); //距离统计 22 lent.put(b+"+"+a,flag); //将两个结点和距离加入lent哈希图。 23 last++; //尾结点后移一个 24 } 25 } 26 temp++; //遍历结点后移一个 27 } 28 } 29 }
如此,第二次作业的两个新增方法就只需要:
isConnected(): 先查看脏位是否为1,1则执行store()方法更新lent。然后在lent中寻找
return (lent.containsKey(fromNodeId+"+"+toNodeId))
getShortestPathLength(): 先查看dirty同上,然后
return lent.get(fromNodeId+"+"+toNodeId);
十分简单,耗时也不长。
但是!!!!!:)
第三次作业
但是第三次作业就麻烦到去世……
开始尝试了仍然继承前两次的方法。仍然使用path数组+HashSet,新容器用上次四个HashMap外加新的HashMap bnodes来表示每个结点与分块的对应。
同时加入新的脏位dirtyb,加入分块统计位numb来表示块的数量。
1 private HashMap<Path,Integer> ptoid = new HashMap<>(); 2 private HashMap<Integer,Path> idtop = new HashMap<>(); 3 private HashMap<Integer,Integer> anodes = new HashMap<>(); 4 private HashMap<String,Integer> lent; 5 private HashMap<Integer,Integer> bnodes; 6 private int numb = 0; 7 private int idcount = 1; 8 private int dirty = 0; 9 private int dirtyb = 0;
再加入新的storeb()方法,具体实现类似于上次的store()方法,用来更新bnods。
至此能轻松完成块统计指令。
但是关于满意度、最少换乘路径便实现地十分艰难,最后一直超时甚至弱中测也过不了。
过程中学习了讨论区指出的邻接矩阵方法,用新的存储格式将path的结点打散重新存储。但没有写完……
BUG修复部分
所有的BUG都是超时问题,前两次的方法实现开始十分简单粗劣,第一次就完全随便写的没有考虑什么复杂度问题,然后强测超时一半后改变了数据存储结构、将部分常用方法的部分操作转移到其他方法中,再引入其他容器,针对不同操作使用不用容器最后全过了没有什么例外情况。第三次一直想着继承前两次的结构,最后发现这种结构无法继续下去。所以最后所谓的“BUG修复”,变成了完完全全的推倒重做。
• 4>.阐述对规格撰写和理解上的心得体会
- 本次虽然只有根据JML写代码,而没有反向要求,但是也同时掌握了JML语言的基础应用
- 根据规格架构写代码不可以像之前那样想到什么功能就将相应实现方法写出来,再继续后续思考。为了整体架构的合理性、简洁性,必须一开始就有一定的全局观念,并充分考虑后续拓展空间。
- 由此也体会到了一些工程化编程的思想逻辑,关于如何根据已有规格实现具体方法,以及数据结构的具体应用。