一、首先:以下代码都是在LINUX上执行的,因为新版本celery已经不支持windows系统,运行会报错。
Celery是处理大量消息的一个分布式系统,那他是如何运行的呢?
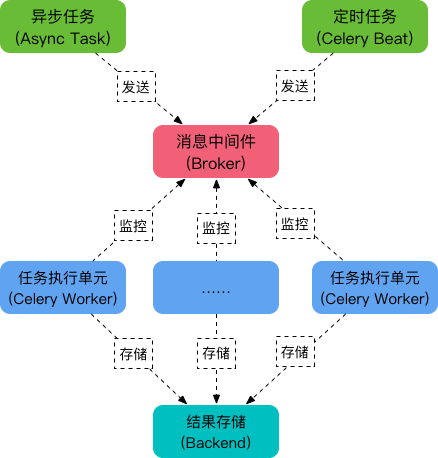
可以看到,Celery 主要包含以下几个模块:
- 任务模块 Task包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列。
- 消息中间件 BrokerBroker,即为任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis 等。
- 任务执行单元 WorkerWorker 是执行任务的处理单元,它实时监控消息队列,获取队列中调度的任务,并执行它。
- 任务结果存储 BackendBackend 用于存储任务的执行结果,以供查询。同消息中间件一样,存储也可使用 RabbitMQ, Redis 和 MongoDB 等。
celery还可以异步执行任务,定时任务,周期任务。
下面创造一个执行单元:

task.py
from celery import Celery import time my_task = Celery('task',broker='redis://127.0.0.1:6379', backend='redis://127.0.0.1:6379') # broker和backend都设置为redis # 任务执行单元 @my_task.task def func1(x,y): time.sleep(10) return x + y
再建立一个派送任务的py
from task import func1 res = func1.delay(2,4) # 用delay去向执行单元派送任务并传参 print(res.id)
先运行worker,让他处于ready状态,如果有数据就可以直接处理数据:
celery worker -A task -l INFO # -A 指定worker所在的Celery app的文件名,就是task # -l 是日志打印的级别 # -c 10 可以同时开启10个worker处理
结果如下,说明worker已经待命,可以处理数据了。
[tasks] . task.func1 [2019-05-20 16:37:28,752: INFO/MainProcess] Connected to redis://127.0.0.1:6379// [2019-05-20 16:37:28,768: INFO/MainProcess] mingle: searching for neighbors [2019-05-20 16:37:29,797: INFO/MainProcess] mingle: all alone [2019-05-20 16:37:29,841: INFO/MainProcess] celery@hjj-virtual-machine ready.
同时我们运行我们的发送命令的py
python3 res.py
运行结果如下:
[2019-05-20 16:39:07,699: INFO/MainProcess] Connected to redis://127.0.0.1:6379// [2019-05-20 16:39:07,712: INFO/MainProcess] mingle: searching for neighbors [2019-05-20 16:39:08,741: INFO/MainProcess] mingle: all alone [2019-05-20 16:39:08,771: INFO/MainProcess] celery@hjj-virtual-machine ready. [2019-05-20 16:40:07,600: INFO/MainProcess] Received task: task.func1[fb4ad8bc-488a-4aba-ba37-1b554b08346a] [2019-05-20 16:40:17,634: INFO/ForkPoolWorker-2] Task task.func1[fb4ad8bc-488a-4aba-ba37-1b554b08346a] succeeded in 10.023761188000208s: 6
同时给我们res.py打印的res是一个uuid:
e14727fc-15b3-47eb-8df5-4930d7cc337c
我们调用res.get()可以取到这个uuid实际的运行结果。
以上是最简单的一个celery应用,让大家明白celery运行的一个流程。
PS: 我们除了调用delay外,还可以调用apply_async事实上,delay方法封装了 apply_async,如下:
def delay(self, *partial_args, **partial_kwargs): """Shortcut to :meth:`apply_async` using star arguments.""" return self.apply_async(partial_args, partial_kwargs)
也就是说,delay 是使用 apply_async 的快捷方式。apply_async 支持更多的参数,它的一般形式如下:
countdown:指定多少秒后执行任务
task1.apply_async(args=(2, 3), countdown=5) # 5 秒后执行任务
eta (estimated time of arrival):指定任务被调度的具体时间,参数类型是 datetime
from datetime import datetime, timedelta # 当前 UTC 时间再加 10 秒后执行任务 task1.multiply.apply_async(args=[3, 7], eta=datetime.utcnow() + timedelta(seconds=10))
xpires:任务过期时间,参数类型可以是 int,也可以是 datetime
task1.multiply.apply_async(args=[3, 7], expires=10) # 10 秒后过期
二、在实际项目中的应用
celery.py,PS:这个名字是为了不用文件的方式启动,直接启动Celery_task目录名就可以,celery会自动去检索目录下所有的task,通过过include中的内容逐一去找
1 from celery import Celery 2 3 celery_task = Celery("task", 4 broker="redis://127.0.0.1:6379", 5 backend="redis://127.0.0.1:6379", 6 include=["Celery_task.task_one","Celery_task.task_two"]) 7 # include 这个参数适用于寻找目录中所有的task
task_one.py
1 from .celery import celery_task 2 import time 3 4 @celery_task.task 5 def one(x,y): 6 time.sleep(5) 7 return f"task_one {x+y}"
task_two.py
1 from .celery import celery_task 2 import time 3 4 @celery_task.task 5 def two(x,y): 6 time.sleep(5) 7 return f"task_two {x+y}"
my_celery:
1 from Celery_task.task_one import one 2 from Celery_task.task_two import two 3 4 one.delay(10,10) 5 two.delay(20,20)
运行:
celery worker -A Celery_task -l INFO
celery也可以通过此方式帮助我们达到一个异步处理数据的一个过程。不用阻塞等待结果在执行下一步。
三、定时任务(关键字:delay -- > apply_async)
我们还使用Celery_task这个示例来修改一下,my_celery中进行一下小修改
1 from Celery_task.task_one import one 2 from Celery_task.task_two import two 3 4 # one.delay(10,10) 5 # two.delay(20,20) 6 7 # 定时任务我们不在使用delay这个方法了,delay是立即交给task 去执行 8 # 现在我们使用apply_async定时执行 9 10 #首先我们要先给task一个执行任务的时间 11 import datetime,time 12 # 获取当前时间 此时间为东八区时间 13 ctime = time.time() 14 # 将当前的东八区时间改为 UTC时间 注意这里一定是UTC时间,没有其他说法 15 utc_time = datetime.datetime.utcfromtimestamp(ctime) 16 # 为当前时间增加 10 秒 17 add_time = datetime.timedelta(seconds=10) 18 action_time = utc_time + add_time 19 20 # action_time 就是当前时间未来10秒之后的时间 21 #现在我们使用apply_async定时执行 22 res = one.apply_async(args=(10,10),eta=action_time) 23 print(res.id) 24 #这样原本延迟5秒执行的One函数现在就要在10秒钟以后执行了
四、周期任务
1 from celery import Celery 2 from celery.schedules import crontab 3 4 celery_task = Celery("task", 5 broker="redis://127.0.0.1:6379", 6 backend="redis://127.0.0.1:6379", 7 include=["Celery_task.task_one","Celery_task.task_two"]) 8 9 #我要要对beat任务生产做一个配置,这个配置的意思就是每10秒执行一次Celery_task.task_one任务参数是(10,10) 10 celery_task.conf.beat_schedule={ 11 "each10s_task":{ 12 "task":"Celery_task.task_one.one", 13 "schedule":10, # 每10秒钟执行一次 14 "args":(10,10) 15 }, 16 "each1m_task": { 17 "task": "Celery_task.task_one.one", 18 "schedule": crontab(minute=1), # 每一分钟执行一次 19 "args": (10, 10) 20 }, 21 "each24hours_task": { 22 "task": "Celery_task.task_one.one", 23 "schedule": crontab(hour=24), # 每24小时执行一次 24 "args": (10, 10) 25 } 26 27 } 28 29 #以上配置完成之后,还有一点非常重要 30 # 不能直接创建Worker了,因为我们要执行周期任务,所以首先要先有一个任务的生产方 31 # celery beat -A Celery_task 32 # celery worker -A Celery_task -l INFO -P eventlet