Web框架本质
什么是Web框架, 如何自己搭建一个简易的Web框架?其实, 只要了解了HTTP协议, 这些问题将引刃而解.
简单的理解: 所有的Web应用本质上就是一个socket服务端, 而用户的浏览器就是一个socket客户端.
用户在浏览器的地址栏输入网址, 敲下回车键便会给服务端发送数据, 这个数据是要遵守统一的规则(格式)的, 这个规则便是HTTP协议. HTTP协议主要规定了客户端和服务器之间的通信格式
浏览器收到的服务器响应的相关信息可以在浏览器调试窗口(F12键开启)的Network标签页中查看, 点击view source即可以查看原始响应数据(有些网页可能并没有该项)
访问码云网站的原始响应数据(节选)
HTTP/1.1 200 OK
Date: Thu, 16 May 2019 13:30:59 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
每个HTTP请求和响应都遵循相同的格式, 一个HTTP包含Header和Body两部分, 其中Body是可选的. HTTP响应的Header中有一个Content-Type表名响应的内容格式. 如text/html表示HTML网页
HTTP GET请求的格式

HTTP 响应的格式

以上内容总结为一句话便是: 要使自己写的Web server端正常运行起来, 必须要使我们自己的Web server端在给客户端回复消息时按照HTTP协议的规则加上响应状态行
自定义Web框架
一 响应指定内容的Web框架
浏览器访问127.0.0.1:9001将返回Hello World标题字样
import socket # 导入socket模块 def main(): # 实例化socket对象 sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 绑定IP地址与端口 sock.bind(('127.0.0.1', 9001)) # 监听 sock.listen() while True: conn, addr = sock.accept() data = conn.recv(1024) str = data.decode("UTF-8").strip(" ") print("浏览器请求信息>>>", str) # 如果浏览器请求信息非空则进行回复 if str: # 给回复的消息加上响应状态行 conn.send(b"HTTP/1.1 200 OK\r\n\r\n") conn.send(b"<h1>Hello World</h1>") conn.close() # 否则跳过本次循环, 开始下一次循环 else: continue if __name__ == "__main__": main()
二 响应HTML文件的Web框架
(1) 首先创建一个html文件
一个展示标题与当前时间的网页, 命名为index.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <style> #in1 { width: 400px; height: 60px; font-size: 26px; font-weight: bloder; line-height: 30px; border: none; } </style> <title>index</title> </head> <body> <h1>欢迎访问简易版Web框架主页</h1> <input type="text" id="in1"/> <script> var item; function f(){ var time = new Date(); // 实例化时间对象 var year = time.getFullYear(); // 获得年 var month = time.getMonth() + 1; // 获得月 var date = time.getDate(); // 获得日 var hours = time.getHours(); // 获得小时 var minutes = time.getMinutes(); // 获得分钟 var seconds = time.getSeconds(); // 获得秒 // 月份与日期的显示为两位数字如01月01日 if(month < 10 ){ month = "0" + month; } if(date < 10 ){ date = "0" + date; } // 时间拼接 var dateTime = year + "年" + month + "月" + date + "日" + hours + "时" + minutes + "分" + seconds + "秒"; // 利用ID获取到input元素 var inputEle = document.getElementById("in1"); // 将input元素的值设置为当前时间 inputEle.value = dateTime; } // 定义启动函数 function start(){ // 初始化当前时间 f(); // 利用定时器每隔一段时间执行获取当前时间与赋值函数f item = setInterval(f, 1000); } // 调用启动函数 start() </script> </body> </html>
在该html文件中可添加img标签, 其src属性值如果是网络地址也是可以直接在浏览器上现实的
在该html文件中的css样式与js操作同样可以直接在浏览器上显示出来
(2) 准备服务端程序, 文件命名为server.py
import socket # 导入socket模块 import os # 导入os模块 def main(): # 利用os模块拼接路径 html_path = os.path.join(os.path.dirname(__file__), "index.html") # 实例化socket对象 sk = socket.socket() # 绑定IP地址与端口 sk.bind(('127.0.0.1',9001)) # 监听 sk.listen() # 计数 i = 1 while True: # 等待浏览器连接获取连接 conn, _ = sk.accept() # 接收浏览器请求 data = conn.recv(1024) # 将浏览器请求转换为字符串并格式化 str = data.decode('utf-8').strip(" ") # 打印浏览器响应 print('浏览器请求信息>>>:', str, i) # 计数自加 i += 1 # 如果浏览器请求内容并不为空, 响应浏览器请求 if str: # 为响应的数据加上相应状态行 conn.send(b'HTTP/1.1 200 ok \r\n\r\n') # 以bytes数据类型打开html文件 with open(html_path,'rb') as f: # 读取数据 data = f.read() # 发送html文件数据 conn.send(data) # 关闭与浏览器的连接 conn.close() # 若浏览器请求信息为空则关闭连接并跳过本次循环, 开始下一次循环 else: conn.close() continue if __name__ == "__main__": main()
注意: 该例子使用相对路径, index.html与server.py需在同一目录下
三 根据浏览器请求响应数据的Web框架
以上简易的框架基本上都是指定了要给浏览器返回什么数据, 这样肯定满足不了我们的需求, 那么如何才能根据浏览器的请求, 响应相对应的数据呢?
CSS, JS, 图片等文件都叫做网站的静态文件
(1) 为了测试, 首先创建一个html文件, 命名为index.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>index</title> <!-- 引入外部CSS文件 --> <link rel="stylesheet" href="css.css"> <!-- 引入外部JS文件 --> <script src="js.js"></script> </head> <body> <h1>欢迎访问Web框架首页</h1> <!-- 绑定事件 --> <div onmouseover="mOver(this)"; onmouseout="mOut(this)"> 把鼠标移到上面 </div> </body> </html>
(2) 接着创建一个CSS文件, 命名为css.css
div { /* 初始化元素背景色为绿色 */ background-color:green; /* 初始化元素宽200px */ width:200px; /* 初始化元素高200px */ height:200px; /* 初始化元素内填充40px */ padding:40px; /* 初始化字体颜色为白色 */ color:#ffffff; }
(3) 再创建一个JS文件, 命名为js.js
// 定义鼠标覆盖事件触发函数 function mOver(obj) { // 文字替换为"谢谢" obj.innerHTML="谢谢" // 背景颜色更改为红 obj.style.backgroundColor= "red"; } // 定义鼠标非覆盖状态事件触发函数 function mOut(obj) { // 文字替换为"把鼠标以到上面" obj.innerHTML="把鼠标移到上面" // 背景颜色更改为绿 obj.style.backgroundColor= "green"; }
(4) 准备服务端程序, 文件命名为server.py
import os # 导入os模块 import socket # 导入socket模块 # 导入线程模块 from threading import Thread # 实例化socket对象 server = socket.socket() # 绑定IP及端口 server.bind(("127.0.0.1", 9001)) server.listen() # 路径拼接 html_path = os.path.join(os.path.dirname(__file__), "index.html") css_path = os.path.join(os.path.dirname(__file__), "css.css") js_path = os.path.join(os.path.dirname(__file__), "js.js") def html(conn): """ 响应"/"请求 """ conn.send(b'HTTP/1.1 200 ok \r\n\r\n') with open(html_path, mode="rb") as f: content = f.read() conn.send(content) conn.close() def css(conn): """ 响应"/css.css"请求 """ conn.send(b"HTTP/1.1 200 ok \r\n\r\n") with open(css_path, mode="rb") as f: content = f.read() conn.send(content) conn.close() def js(conn): """ 响应"/js.js"请求 """ conn.send(b"HTTP/1.1 200 ok \r\n\r\n") with open(js_path, mode="rb") as f: content = f.read() conn.send(content) conn.close() def NotFound(conn): conn.send(b"HTTP/1.1 200 ok \r\n\r\n") conn.send(b"<h1>404NotFound!</h1>") # 请求列表 request_list = [ ("/", html), ("/css.css", css), ("/js.js", js) ] def get(conn): """ 处理响应函数 """ try: # 异常处理 req = conn.recv(1024).decode("UTF-8") req = req.split("\r\n")[0].split()[1] # 打印浏览器请求 print(req) except IndexError: pass # 遍历请求列表进行响应 for request in request_list: # 若浏览器请求信息等于请求列表中的项,则进行响应 # 判断服务端是否能够进行响应 if req == request[0]: # 获取线程对象, 实现并发 t = Thread(target=request[1], args=(conn, )) # 启动线程 t.start() # 响应后结束遍历 break else: # 若本次循环未匹配则跳过本次循环开始下一次 continue else: # 若所有请求皆不匹配则调用NotFound函数, 表示无法响应 NotFound(conn) def main(): while True: # 利用线程实现并发 # 获取TCP连接 conn, _ = server.accept() t = Thread(target=get, args=(conn,)) t.start() if __name__ == "__main__": main()
注意: 该例子使用相对路径, index.html, css.css, js.js与server.py需在同一目录下
四 进阶版Web框架
以上的几版Web框架比较基础, 一些定义的函数使用起来也比较繁琐, 可定制性很差, 修改起来也比较困难.
利用Python提供的一些模块可以简化一些步骤, 并且使框架的可定制性更好, 可以方便其他人进行定制使用
结构示意图
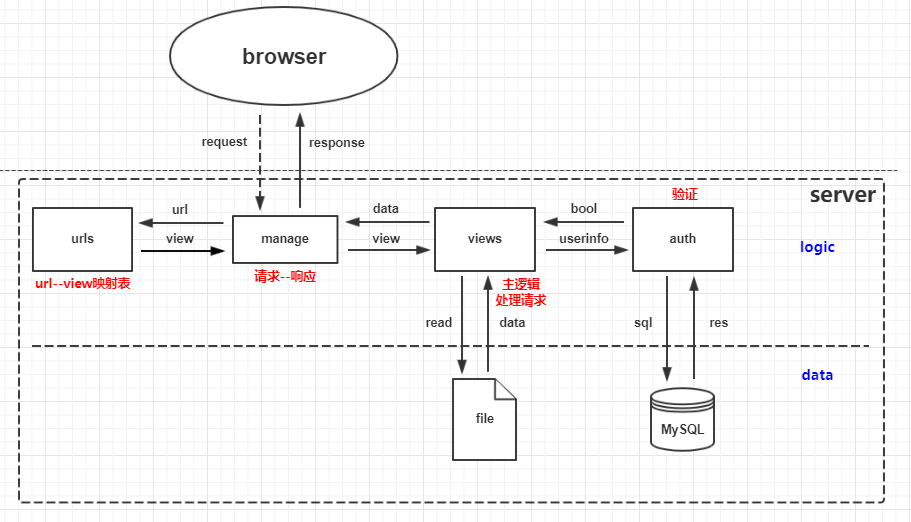
文件结构
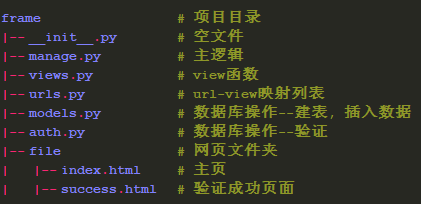
构建Web框架
(1) 构建目录
新建文件夹frame
1) 文件夹内创建__init__.py文件(内容为空)
2) 文件夹内新建文件夹file
(2) 准备html文件
index.html文件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <style> /* 时间展示样式 */ #in1{ width: 400px; height: 60px; font-size: 26px; font-weight: bloder; line-height: 30px; border: none; } </style> <title>index</title> </head> <body> <!-- 标题 --> <h1>欢迎访问简易版Web框架主页</h1> <!-- 动态替换(模板渲染), 刷新页面动态刷新 --> <h2>@</h2> <input type="text" id="in1"/> <!-- 认证表单 --> <form action="http://127.0.0.1:9001/auth/" method="post"> <label for="username">用户名</label> <input type="text" id="username" name="username"/> <label for="password">密码</label> <input type="password" id="password" name="password"/> <input type="submit"> </form> <script> var item; function f(){ var time = new Date(); var year = time.getFullYear(); var month = time.getMonth() + 1; var date = time.getDate(); var hours = time.getHours(); var minutes = time.getMinutes(); var seconds = time.getSeconds(); // 月份与日期的显示为两位数字如01月01日 if(month < 10 ){ month = "0" + month; } if(date < 10 ){ date = "0" + date; } // 时间拼接 var dateTime = year + "年" + month + "月" + date + "日" + hours + "时" + minutes + "分" + seconds + "秒"; var inputEle = document.getElementById("in1"); inputEle.value = dateTime; } function start(){ f(); item = setInterval(f, 1000); } start() </script> </body> </html>
success.html文件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>success</title> </head> <body> <h1>登陆成功</h1> </body> </html>
将以上两个html文件保存到file文件夹内
(3) models.py文件
首先需要创建一个数据库, 这里使用MySQL
-- 登录MySQL mysql -u用户名 -p密码 -- 查看数据库 SHOW DATABASES; -- 创建数据库 CREATE DATABASE 库名; /* 这里创建一个名为dbf的数据库 CREATE DATABASE dbf; */
利用pymysql模块操作数据库, 建表插入数据
models.py文件
import pymysql # 导入pymysql模块, 需要下载 # pip install pymysql def main(): conn = pymysql.connect( host = "127.0.0.1", # mysql主机地址 port = 3306, # mysql端口 user = "root", # mysql远程连接用户名 password = "123", # mysql远程连接密码 database = "dbf", # mysql使用的数据库名 charset = "UTF8" # mysql使用的字符编码,默认为utf8 ) # 实例化游标对象 cursor = conn.cursor(pymysql.cursors.DictCursor) # 创建表格 sql1 = """CREATE TABLE userinfo( id int PRIMARY KEY auto_increment, username char(12) NOT NULL UNIQUE, password char(20) NOT NULL ); """ # 向创建的表格中插入数据 sql2 = """INSERT INTO userinfo(username, password) VALUES ("a", "1"), ("b", "2"); """ # 将sql指令提交到缓存 cursor.execute(sql1) cursor.execute(sql2) # 提交并执行sql指令 conn.commit() # 关闭游标 cursor.close() # 关闭与数据库的连接 conn.close() if __name__ == "__main__": main()
(4) auth.py文件
用于验证用户登录信息
auth.py文件
import pymysql # 导入pymysql模块 def auth(username, password): conn = pymysql.connect( host = "127.0.0.1", # mysql主机地址 port = 3306, # mysql端口 user = "root", # mysql远程连接用户名 password = "123", # mysql远程连接密码 database = "dbf", # mysql使用的数据库名 charset = "UTF8" # mysql使用的字符编码,默认为utf8 ) # 打印用户信息: 用户名, 密码 print("userinfo", username, password) # 实例化游标对象 cursor = conn.cursor(pymysql.cursors.DictCursor) # sql查询指令 sql = "SELECT * FROM userinfo WHERE username=%s AND password=%s" # res获取影响行数 res = cursor.execute(sql, [username, password]) if res: # 数据库中存在该数据, 返回True return True else: # 数据库中不存在该数据, 返回False return False
(5) views.py文件
用于处理数据
views.py文件
""" 该模块存放浏览器请求对应的网页与urls模块中url_list列表中的项存在映射关系 若要添加新的内容, 只需要定义相应的函数, 并将函数名以字符串的形式加入到__all__列表中 """ import os # 导入os模块 import time # 导入time模块 import auth # 导入auth.py from urllib.parse import parse_qs # 导入parse_qs用于解析数据 # 展示所有可用方法 __all__ = [ "index", "authed" # "css" ] # 路径拼接(针对windows"/", linu需要把"/"改为"\") index_path = os.path.join( os.path.dirname(__file__), "file/index.html") success_path = os.path.join( os.path.dirname(__file__), "file/success.html") def index(environ): with open(index_path, mode="rb") as f: data = f.read().decode("UTF-8") # 将特殊符号@替换为当前时间, 实现动态网站 data = data.replace("@", time.strftime(("%Y-%m-%d %H:%M:%S"))) return data.encode("UTF-8") def authed(environ): if environ.get("REQUEST_METHOD") == "POST": try: request_body_size = int(environ.get("CONTENT_LENGTH", 0)) except (ValueError): request_body_size = 0 request_data = environ["wsgi.input"].read(request_body_size) print(">>>", request_data) # bytes数据类型 print("????", environ["QUERY_STRING"]) # "空的" - post请求只能按照以上方式获取数据 # parse_qs负责解析数据 # 不管是POST还是GET请求都不能直接拿到数据, 拿到的数据仍需要进行分解提取 # 所以引入urllib模块中的parse_qs方法 request_data = parse_qs(request_data.decode("UTF-8")) print("拆解后的数据", request_data) # {"username": ["a"], "password": ["1"]} username = request_data["username"][0] password = request_data["password"][0] status = auth.auth(username, password) if status: with open(success_path, mode="rb") as f: data = f.read() else: # 如果直接返回中文, 没有给浏览器指定编码格式, 默认是gbk, 需要进行gbk编码, 使浏览器能够识别 # 这里已经指定了编码 # start_response("200 OK", [("Content-Type", "text/html;charset=UTF8")]) data = "<h1>用户名或密码错误, 登陆失败</h1>".encode("UTF-8") return data if environ.get("REQUEST_METHOD") == "GET": print("????", environ["QUERY_STRING"]) # "username='a'&password='1'"字符出数据类型 request_data = environ["QUERY_STRING"] # parse_qs负责解析数据 # 不管是POST还是GET请求都不能直接拿到数据, 拿到的数据仍需要进行分解提取 # 所以引入urllib模块中的parse_qs方法 request_data = parse_qs(request_data) print("拆解后的数据", request_data) # {"username": ["a"], "password": ["1"]} username = request_data["username"][0] password = request_data["password"][0] print(username, password) status = auth.auth(username, password) if status: with open(success_path, mode="rb") as f: data = f.read() else: # 如果直接返回中文, 没有给浏览器指定编码格式, 默认使gbk, 需要进行gbk编码, 是浏览器能够识别 # 这里已经指定了编码 # start_response("200 OK", [("Content-Type", "text/html;charset=UTF8")]) data = "<h1>用户名或密码错误, 登陆失败</h1>".encode("UTF-8") return data # def css(environ): # with open("css.css", mode="rb") as f: # data = f.read() # return data
(6) urls.py文件
映射表
urls.py文件
from views import index, authed """ 可在此处按照类似格式添加任意内容 例如再向url_list列表中添加一项, 按照如下格式 ("/css.css", css), 只需要再在views.py文件中创建一个对应的函数即可 """ url_list = [ ("/", index), ("/auth/", authed) # ("/css.css", css) ]
(7) manage.py文件
主逻辑
manage.py文件
from urls import url_list from wsgiref.simple_server import make_server def application(environ, start_response): """ :param environ: 包含所有请求信息的字典 :param start_response: 封装响应信息(相应行与响应头) :return: [响应主体] """ # 封装响应信息 start_response("200 OK", [("Content-Type", "text/html;charset=UTF8")]) # 打印包含所有请求信息的字典 print(environ) # 打印请求路径信息 print(environ["PATH_INFO"]) path = environ["PATH_INFO"] for p in url_list: if path == p[0]: data = p[1](environ) break else: continue else: data = b"<h1>Sorry 404!, NOT Found The Page</h1>" # 返回响应主体 # 必须遵守此格式[内容] return [data] if __name__ == "__main__": # 绑定服务器IP地址与端口号, 调用函数 frame = make_server("127.0.0.1", 9001, application) # 开始监听HTTP请求 frame.serve_forever()
至此一个简易的Web框架就搭建好了, 我再来简单介绍一下启动步骤
启动步骤
(1) 首先按照步骤, 执行(3) models.py文件
1) 创建数据库
2) 执行models.py
(2) 执行manage.py启动服务器
(3) 根据指定IP及端口, 使用浏览器访问
这里指定127.0.0.1:9001
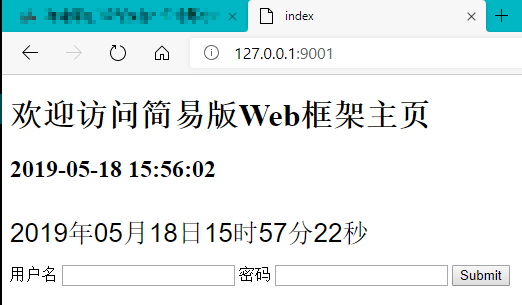
效果演示
index页面
登录成功

登录失败
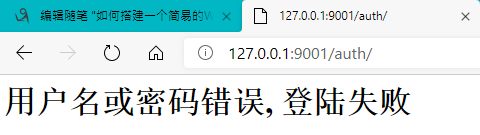
错误请求
包/模块解析
以上的框架中用到了两个比较重要的包/模块: wsgiref模块与urllib包, 下面介绍一下
wsgiref模块
WSGI简介引用
WSGI(Web Server Gateway Interface)是一种规范, 它定义了使用Python编写的web应用程序与web服务器程序之间的接口格式, 实现web应用程序与web服务器程序间的解耦
常用的WSGI服务器有uwsgi、Gunicorn. 而Python标准库提供的独立WSGI服务器叫做wsgiref, Django开发环境用的就是这个模块来做服务器
wsgire模块简介引用
wsgiref模块其实就是将整个请求信息给封装了起来, 比如它将所有请求信息封装成了一个叫做request的对象, 那么直接利用request.path就能获取到本次请求的路径. request.method就能获取到本次请求的请求方式(GET/POST)等
urllib包
urllib简介《Python参考手册(第4版)》
urllib包提供了一个高级接口, 用于编写需要与HTTP服务器、FTP服务器和本地文件交互的客户端. 典型的应用程序包括从网页抓取数据、自动化、代理、Web爬虫等. 这是可配置程度最高的库模块之一
由于urllib包中功能模块众多且功能强大, 在此不做过多介绍, 仅介绍本框架所用模块
在views.py中我们通过 from urllib.parse import parse_qs 导入了urllib包下的parser模块中的parse_qs方法
parse模块《Python参考手册(第4版)》
urllib.parser模块用于操作URL字符串, 如"http://www.python.org"
其中parse_qs方法:
parse_qs(qs [, keep_blank_values [, strict_parsing]])
解析URL编码的(MIME类型为application/x-www-form-urlencoded)查询字符串qs, 并返回字典, 其中键是查询变量名称, 值是为每个名称定义的值列表. keep_blank_values是一个布尔值标志,控制如何处理空白值. 如果为True, 则它们包含在字典中, 值设置为空字符串; 如果为False(默认值), 则将其丢弃。strict_parsing是一个布尔值标志, 如果为True, 则将解析错误转换为ValueError异常. 默认情况下会忽略错误
以上就是本人在学习Django框架前的学习总结, 可供学习参考