继续往下讲就是分区了

对于ORACLE来讲,分区是咱们开发中最常用的,什么样的场景下要进行分区,主要是针对于大数据量的表,频繁查询的表,
我只是说数据量大的表,并没有说物理的这个大,比如你搞一个文件表,数据库文件,里面来一个file文件,你搞一个file文件这种表,
然后你去做分区,那样的话其实也不是很快的,我们这里说的怎么去做分区,是按照数据量来的,不是按照物理的大小来的,按照物理
大小其实ORACLE应付不了太大的数据,资深的ORACLE DBA,做运维这方向,一个表得有多大吗,多少个G吗,你想不到,你们猜一猜,
一张表,当然是存放file文件的表,存放一些图片,还有一些其他的东西,你们猜一下这张表有多大,300G,就是一张表300G,你猜猜
这张表有多少东西,就是一张300G的file表,就是那个文件表,就是怎么说呢,累积好多年的一些图片数据,我问他怎么办,没什么
解决的办法,就是光备份就得备份好几天,因为什么啊,大数据你可以存在其他的地方,你这么大的数据量,当然DBA不是JAVA这个方向,
就是再索引你这个也太大了,就是300G,你想想,300G是什么概念,一张表300个G,像有些需求啊,咱们去做项目的时候,也会有张文件表,
数据库里面必须有张文件表,文件表应该存一些比较特殊的文件信息,你像一些无关紧要的信息,却还是很海量的信息,我们一般是
放在类似于数据仓库,和文件服务器上,咱们在数据库里面给一个字段,给一个文件服务器的路径,给他写到里边,然后浏览器直接
访问这条记录的时候,有一个path路径,直接到界面上能够显示出来,都是这么去做的,当然也是好多年了,也没人去管,好了不用讨论
这个事了,首先咱们说分区的事,ORACLE表分区最好一个区间不要大于500W条,500W条应该是一个工作限,你按什么分区,一个区间
500W条数据,这个东西你要自己去衡量,自己去判断的,首先分区,怎么去做分区,使用什么分区,还是用实际的业务逻辑去考虑的,
ORACLE 11g提供了7种的分区功能,非常强大,满足90%以上的需求,一般来讲咱们队分区应该是非常的有了解了,应该是这样的,
ORACLE里面一共分这些种,咱们一起来看一下,range分区,hash,list,复合,间隔,system,这7种分区,首先说第一种分区

咱们的range分区,range分区其实就是区域分区,就是你从逻辑上给我划分一个区域,然后按照这个区域把这个表进行一个分区,
原先的一个数据库表存在一个文件里,就是咱们对应的数据库文件里,那现在我做分区了以后,就是把多个表拆分成了多个块,就是有
多个数据库文件,那么大家想一件事,你说这样去做分区的话,画个图,就是我分区的概念是什么啊,我在这里简单的说一下,无论你怎么样的
分区,其实都是一样的,都是一个概念,就是原先咱们一张表不做分区的时候,咱们的一个表是存在数据库一个文件上的,就是咱们磁盘上有
一个小文件,专门就对应这张表去存,这个文件就存这个表的信息,然后我分区了以后,就相当于什么,相当于不存在一个地方了,把第一个
区间,第二个区间,第三个区间,分别的放在不同的物理的位置,可能有3个文件,那么现在问题就产生了,咱们的语法必须得结合create
table去实现,就是说什么啊,你在创建表的时候,然后紧连着指定partition,你不能先创建表,表创建完了以后你再去指定partition,
这是不行的,你只能是创建表的时候一并去指定partition,去指定分区,只有这样才行,因为你一旦表创建完了之后,一个数据文件已经
创建完了,就是我这个表所有的数据都放在这个文件里了,所以你再分区,这个表去拆成几个文件,这个不现实,一些运维的手段,运维什么
手段呢,利用一些抽取工具一部分一部分的逐渐的去建立,所以说这些都不是咱们要考虑的事了,就是现在要告诉你的事情是create
table的时候,直接指定加上partition,这样的话才能一个表按照你的物理的文件去存储,所以说为什么语法是这样的呢,就是因为
这个原因,以表单位还是以库为单位,这个你自己可以去定义,这个就无所谓了咱们先看一个小例子吧,首先我就create一个table,
然后指定一个分区,就可以这样去做,你把咱们来写一写吧,现在我就来写一个分区的小例子,我这个分区也是有小例子的,所以我就
不怎么想去写他了,创建一个SQL Window,看这个例子吧,首先我是做什么事呢
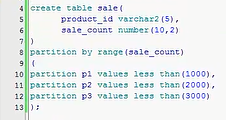
range分区,是按照区域进行分区,分区一定是在create table的时候进行指定的,这是要记住的一个问题,我们先看看
数据库里面有没有相关的一个表,也没有,因为创建一个table叫做sale,薪资,两个字段,一个叫product_id,一个叫sale_count,
一个是id,一个是计数,然后这个数就随随便便写了一个,现在这个表创建完了以后,正常来讲这里要打一个分号,但是我没有这么去做,
我直接说partition by,指定range分区,然后括号里面的内容是什么意思呢,指定分区的字段是什么,说白了就是指定分区的字段是什么,
就是咱们上节课讲的MYSQL,我可以指定一个type类型,一个type类型做什么事啊,我按照type等于1的,里面可能有10条数据,10条数据
可能有5条数据等于1,有5条type等于2,然后把type等于1的放到另外一个数据库中,或者是另外一个表中,这里面放这5条,剩下的都
等于2了,就是这个意思,这个其实也是一样的,咱们要指定的分区是什么,按照这个sale_count去做一个分区,然后现在我既然指定是
range分区,所以说我要指定区间,partition p1,分区的名称是你自己去定义的,我指定一个p1,values less than(1000),这什么
意思,也就是小于1000的这个数值,给我放到p1这个区间,小于等于2000的放到p2这个区间,小于等于3000的放到p3这个区间,
现在咱们去创建一下,创建完了以后咱们在数据库里面多了一个表了,select * from SALE,他和普通的表没有任何的区别

没有什么变化,无非就是一个SALE,你从这里看不出有什么特点,包括你查询的时候也看不出有什么特点,那怎么能看出特点呢,
咱们应该看这个,查看分区的情况,应该看这个,这个是所有的分区的情况,select * from user_tab_partitions,不仅仅是这
一张表的情况,user_tab_partitions,select这张表,之前也会建立很多分区,很多IVERTAL分区,其他你不考虑,首先你看这三个,
SALE这个table,已经指定了三个分区,PATITION_NAME是p1,p2,p3,然后就是HIGH_VALUE,就是他的上限,这个上限是1000,这个上限是
2000,下面的肯定是3000了,还有些其他的字段,他这个字段很多,就不详细去说了

其实你还可以更详细的去看这张表,下面也有,select * from table partition(p1),select * from sale这张表,
SELECT * FROM SALE PARTITION(p1),我们可以这样去查

我可以去查,当然我们刚才分了三个区间,P1,P2,P3,我可以这么联合的去查
SELECT * FROM SALE PARTITION(P1);
SELECT * FROM SALE PARTITION(P2);
SELECT * FROM SALE PARTITION(P3);
这三个区间的数据可能都是空的,现在我就去做一个插入的操作,
INSERT INTO SALE VALUES('1',500);
INSERT INTO SALE VALUES('1',1300);
INSERT INTO SALE VALUES('1',2441);
commit;
INSERT INTO SALE VALUES('1',3500);
第一个字段可能是一个字符串的值,这里面有一个number,比如说是100,咱们多插入几个,他这里是1000,第一个是500吧,
第二个是1300,第三个是2000到3000之间的区间,那我2400,随便给个值,然后再来一个3500,现在先把这三条数据插进去

然后我SELECT * FROM 表的时候你还是看不出来

三条数据还是这样的,你看不出任何的变化,没有任何的特点,物理分区会降低查询速度吗,不会啊,分区的目的就是为了提高
查询的速度,那现在咱们做完这个事了,然后查询出来也没有任何的特点,你再去查这三张表

第一个分区,你看我查P1的时候,他就一条数据,然后我查P2的时候,也就这么一条数据
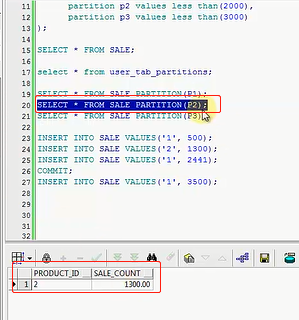
然后我再查P3的时候,2441

也就是说你按照什么分区字段走,然后你根据上面的分区规则,他就把数据塞到不同的分区里了,大体上就是这个意思,
咱们现在就做着事情
INSERT INTO SALE VALUES('1',3500);
现在我们的分区只是三个区,那我现在想插3500,你觉得能插进去吗,就是我现在想插一个3500的数据,我能不能插入到
这个表里,肯定是找不到位置,插入的关键字未映射到任何的分区,说你这个值已经超了我这个分区了,那咱们想一下,
既然插入不进去,一定要再给分区做一个扩展,肯定是支持扩展的,添加和删除分区其实都可以去做,添加就是alter table
tableName add partition p4 values less than(maxvalue),你可以去再指定4000什么的,然后你还可以去指定一个最终
的值,maxvalue,就是无限大,你如果指定这个值的话,那就相当于给这个表指定一个上限了,就是画了一个句号了,你这块如果
是maxvalue的话,就是max到3000都会放到这一个区间里,你可以正常再来一个4000,或者5000,这都是可以的,但是不要轻易去
加这个东西,你这样你这个分区就相当于固定了,这表叫SALE


你会发现现在就有第四个了,然后这里面的最大就是MAXVALUE了,那无论我是插入3500也好,插入一个8000也好,
还是插入1万也好,总会放到第四个分区里,咱们commit一下
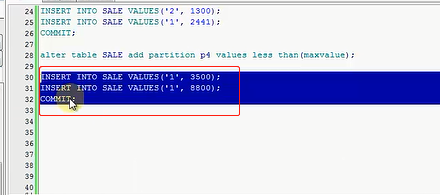
我现在继续去查一下P4
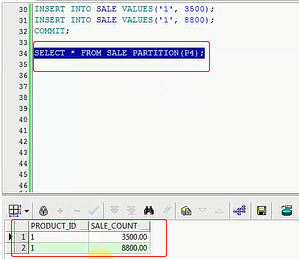
你会发现P4,,3500,8800,都会放到第四个区间里,这就是你对分区的一个扩展,然后咱们继续往下走,然后你也可以删除
分区,drop,alter table tableName drop partition p4,可以把它干掉,我们试一下吧,我把它干掉数据会不会丢失呢,
想一想,咱们直接先操作吧,然后看结果,删掉了之后,然后再来查一下我的partitions

还是三个区,我SELECT * FROM SALE

你就直接把他这个数据给他弄没了

相当于把文件给删除了,再往下看,然后有一个问题就是说,想做一个什么事呢,想想啊,我要做这个事情,我要做update操作,
我要做一个update操作,我这样去做update,你看我先做表里是这三条数据,我现在想把这条数据改一下,先改一下这个吧,
因为我插入的时候可能插错了,UPDATE SALE SET product_id = 3 WHERE sale_count = 500,因为我刚才不小心这个没改过来,
咱们再查一下这个表吧,我要1,2,3这个效果

把第一条记录,SALE我想改了,我做一个UPDATE操作,把这个sale_count改掉,我去UPDATE,
UPDATE SALE SET SALE_COUNT = 1500 WHERE PRODUCT_ID = 1;
我先去做这个操作,我更新完之后能更新成功吗,我现在要更新,更新这条记录,我想把ID这条记录,原先是500,
准备改成1500,然后问一下能不能更新成功,能不能UPDATE成功,就目前来讲,想一想,能不能进行UPDATE成功呢,
目前是不能的,我进行UPDATE的时候,更新分区关键字列将导致分区的更改,本身我的数据原先是在第一个区间的,
我现在想给他改成第二个区间,那这个肯定不行,当然其实也不是不行,也是可以的,只不过你得去做一个操作,
在UPDATE之前你得做这个alter table SALE enable row movement;做一个这个操作,就是使他能行移动,
我先做完这个事情

这个时候我再回来UPDATE就成功了

应该使他能移动,咱们先看第一个区间,就没数据了

但是第二个区间里就有两条数据了

ID等于1的数据是1500,在这个里面,可以去做这个事情,没问题吧,是不是分区很简单,首先分区简单就这么几个操作,
这个能听懂吗,给我点反馈,很简单吧,这个东西是公共的,比如我把这个1又改成500,我现在又给他改回去

我们都是在创建完表以后,就是在创建完partition以后,就直接加这么一句话,一般都是这样的,刚才我已经又改了
一次了,所以P1里还是会有数据的

咱们继续往下看,分区这块目前已经说完了,然后咱们再看分区索引

分区完了以后还得有分区索引,这是啥意思呢,就是你这个表分成了几块,假如你这个表,按照什么字段去分区的,
相当于你把这个表分成了几块,分成1,2,3,4四块,现在我要做什么事呢,我要在每一块上,能不能建一个索引,
分了区了查询会很慢,首先你想一想,咱们这张表结构,我现在就模拟了两个字段,我可能有很多的字段,ID当然是主键了
这个没法说,我现在是按照SALE_COUNT进行分区的,可能SALE_COUNT这个列,这个字段,按照这个列进行分区的,那么划分
成这四个区间以后,那我在这四个区域里,怎么去建索引呢,这个就相当于分区索引,分区以后虽然可以提高查询效率,
分区以后为什么提高查询效率,其实它并不是提高了查询效率,仅仅是提高了数据的范围,那这个举个列子吧,加入我这个表
里面有8条数据,刚才我不是按照SALE_COUNT进行分区的吗,可能把我这个分成了4个区间,分成1,2,3,4这四个区间,
然后每个区间内分成两个数据,如果我WHERE条件接的是一个SALE_COUNT,按照咱们刚才的说法,就是1000,然后这边是1000
到2000的,然后这边是2000到3000的,然后这是maxvalue,那我现在想按照count去查询,去查等于2300的,那这个是会提高
查询效率的,为什么呢,原先加入我不走索引,不走索引的字段,正常来讲我是全表进行扫描,full-scan,都得从头扫到尾,
找到这儿,不是2300吗,我在第三个区间,这个区间是2000到3000的区间,2000到3000区间的时候,才找到了这个数据,
才知道2300,你得经历查完这两条,然后查完这两条,才能查到第三个区间的这个数据,现在你做这个事情,都屏蔽掉了,
P4也屏蔽掉了,直接到第三个区间,直接去找这个值,但是有一个问题是什么呢,你现在还是不是走索引,所以你要是分完区
以后,加完这个索引,你这个效率才会变得很好,分区仅仅是缩小了查询的范围,咱们建立分区索引,进一步提高查询效率,
分区索引大体上分为两类,一类叫做local,一类叫做global,一般我们都会使用本地的分区,在你建完分区的文件去建立索引,
global就是不考虑分区,咱们还是在整个表去建立索引,你分不分区跟咱没关系,我们一般采用本地模式,在每个分区上建立
索引,说白了就是这个图,我刚才使用SALE_COUNT进行分区的,我一定只能在SALE_COUNT这个分区字段上建立索引,只能在这个
分区字段上建立索引,这个就是分区索引,它会子啊每一个LOCAL上建立索引,这块是一块区间,他建立了一个索引,这块区间
他也会建立一个索引,这块区间,他也可会建立一个索引,相当于什么啊,相当于建立了4个索引,在一个字段上,但是是不同的
区间,就是你执行这个语句之后,刚才这种方式叫做LOCAL,LOCAL的方式,还有一种方式叫做GLOBAL,GLOBAL的方式什么意思呢,
就是不看这个分区了,反正我就建一把索引,在整体上去建索引的,要说的就是这个事,LOCAL是在每个分区上都建立索引,
然后GLOBAL是在全局上去建立索引,这种方式其实和分不分区都是相同的,一般不使用,还有一种方式就是自定义数据区间的
索引,这种索引可能叫做前缀索引,他不是按照区域去划分的,但是他非常有意义,自定义区域值的时候必须要定义maxvalue,
咱们先不考虑前缀索引了,咱们先说用得最多的LOCAL,在每个区间上加一个索引,然后你要注意的一点是什么啊,在分区字段
上建的索引必须是分区字段上的列才行,也就是说咱们拿SALE这张表来举列,加入现在PRODUCT_ID没有建索引,就好像我这张表
一样,我这张表压根就没有去建这个INDEX,他也不是主键,有没有去建INDEX,就是两个平凡的字段,现在我想去建立索引,
只能在分区字段上加索引,我只能在SALE_COUNT上加索引,这个就是开始就定死了的,你没办法,你没办法去做其他的事情,
这种语法咱们看一下,create index indexName on table(field) local;其实就是在传统的字段加一个local字段,建立
索引你会了,无非就是后面加一个local,然后就完事了,其实分区索引,你要注意一个问题,第一分区上建立的索引,一定是
分区字段,create index,这里面你随便起个名字吧,我叫idx_count吧,然后你的table是SALE,然后field当然是SALE_COUNT,
加了一个local就OK
create index idx_count on SALE(SALE_COUNT) LOCAL;

你现在已经建立了分区索引了,就是这样的,这个分区索引你现在也可以看到的,你也可以去查索引这张表,你也可以看到,
SELECT * FROM USER_IND_PARTITION;

我现在这个名字叫做ind_count,它会产生三个,因为我现在只有三个分区,P1,P2,P3,我现在写这一条SQL,相当于我写
这一条SQL语句,给我建立三个索引,在每个分区上建立一个索引,就是这个意思,全局的这种自定义索引,也是很有帮助的
这是非常有意义的一种方式,这是啥意思呢,咱们之前都是很固化的,一个划分,你比如说,1,2,3,4,这四块,咱们刚才是按照
COUNT,这个字段进行分区索引,在这里有个index,在这里有个index,假如有4个INDEX,但是这种只是LOCAL模式的分区索引,
其实还有一种是前缀索引,前缀索引的意义就比较大了,他可以不考虑分区去建立索引,可以跨分区的去建立索引,比如说
我可以去做什么事啊,原先是在在一个区间上去建立索引的,如果你有什么特殊的业务逻辑要求,咱们举刚才那个例子,
这个COUNT等于0到1000的范围的数据,咱们会在第一个区间0到1000,第二个区间你是1000到2000的范围,第三个区间是
2000到3000,咱们就是举个例子,比如3000到4000,就是只要你的COUNT是在这个区间范围内,给你塞到指定的区间上,就是这个意思
意思,但是现在有一个前缀索引,他可以不按照1,2,3,4区间去建索引,你比如说我现在就有个需求,我查询比较频繁的就是
0到2300,0到2300的区间我查询很频繁,其他的我查询不频繁,那我建的这个索引就可以是这样的,从这开始建,然后囊括了
第二个,然后也囊括了第三个,但是囊括了第三个就是这样的,然后这边就给他排除,用紫色的排除,这里的数据肯定是0到1000,
然后这里的数据是1000到2000,然后这块的数据是2000到2300,然后这块我刨除的是2300到3000,也就是2300到3000这块我就
不建索引了,那么我建的索引就是这块,就是这个区域,我把这个刨除,抠出去了,那这种方式叫前缀索引,是根据你自己业务
去做的,后期如果说你有这种业务,你需要跨分区的去建索引的话,其实还是非常有意义的,能理解我说的意思吗,给我点反馈,
如果是普通的表,那你没办法,那你建不了,就是这块吗,如果是一个普通的表,以后如果想去建分区怎么办,那没有任何的办法,
你只有一种办法,什么办法啊,你原先这个表里没有建分区,这里边有好多数据,你再克隆一张相同的表,先把这个分区划分好,
然后把这个数据导到这个分区里,你只有这一种办法,能理解我说的意思吧,如果你表已经建好了,你就没办法再分区了,
你只能再重新建立一张相同的表,然后咱们提前把分区建好,把之前的数据导入到新表,这才行,然后前缀索引怎么去建呢,
create index 名字on table(field) global,global下面写这个,partition by range(field),比较类似于咱们的分区了,
在这里面又写一个partition,
写你的值,你注意你必须得加上maxvalule才行,必须要指定maxvalue才行,就是无论你写多少个,你得有一个maxvalue,就是你
这里面可以有P1,P2,P3,P4,....,但是最终里面一定要有maxvalue,比如我是从0到1800,它是建立一个索引,然后从1800到2400,
建立一个索引,然后从2400到1万建立一个索引,但是最终总得有一个maxvalue才行,这是前缀索引建立的原则,必须得有他,
要不然你这个东西是建立不成功的,还有这种全局索引的方式,create index idxname on table(field) global;
这种方式不推荐,无非就是在普通的索引上,加了一个global,他和你平常在全表上建一个索引是一致的,是一样的,其他字段
不可以建索引,其实能建也是能建,可以去建这个索引,但是他效率一点也不高,所以我不推荐你去做这种事情,比如你现在硬要
去写,你现在想要去create index,然后在id上建一个索引,可以啊,但是他这个效率一点也都不会高,那你想想这不就是属于
全局索引吗,就是一个global