一点资讯js解密
一、需求
目标网站:http://www.yidianzixun.com/
抓取范围:各频道页面下的数据
二、调试
1、确定加密参数
- channel_id:频道id
- cstart, cend:开始,结束位置,用于翻页
- _spt:加密参数
- _:时间戳
请求该链接时,未正常返回数据,所以将headers全部拷贝,再次请求,有数据,多次尝试后,确定headers中必须的参数:
- Referer:请求不同频道该参数可以不变
- Cookies中的JSESSIONID参数
2、调试过程
(1)_splt参数
全局搜索_spt参数,找到js文件:http://static.yidianzixun.com/modules/build/index_pc/channel-6502fbb6.js
生成_spt的js代码如下:
void 0 !== (t = function(n, e, i) {
e.encodeToken = function(n, e, i, t) {
for (var o = "sptoken", a = "", c = 1; c < arguments.length; c++)
o += arguments[c];
for (var c = 0; c < o.length; c++) {
var r = 10 ^ o.charCodeAt(c);
a += String.fromCharCode(r)
}
return n += (/\?/.test(n) ? "&_spt=" : "?_spt=") + encodeURIComponent(a)
}
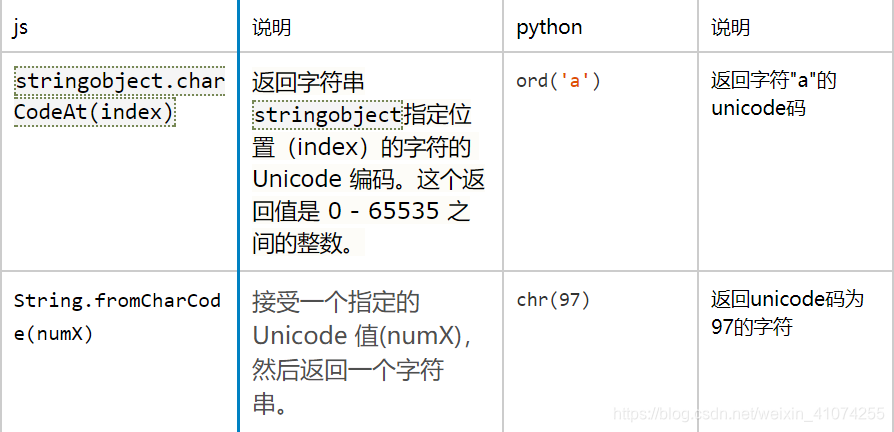
通过断点调试,确定arguments的参数构成:“sptoken” + channel_id + cstart + cend,通过字符和unicode码转换生成对应的_spt参数
def get_spt(id, start=0, end=10):
str_par = 'sptoken{}{}{}'.format(id,start, end)
spt = ''
for key in str_par:
spt += chr(10^ord(key))
return spt
(2)JSESSIONID参数
清空缓存后,全局搜索JSESSIONID对应的值,在请求频道对应的链接(如首页:http://www.yidianzixun.com/ )时,返回cookie中存在该值
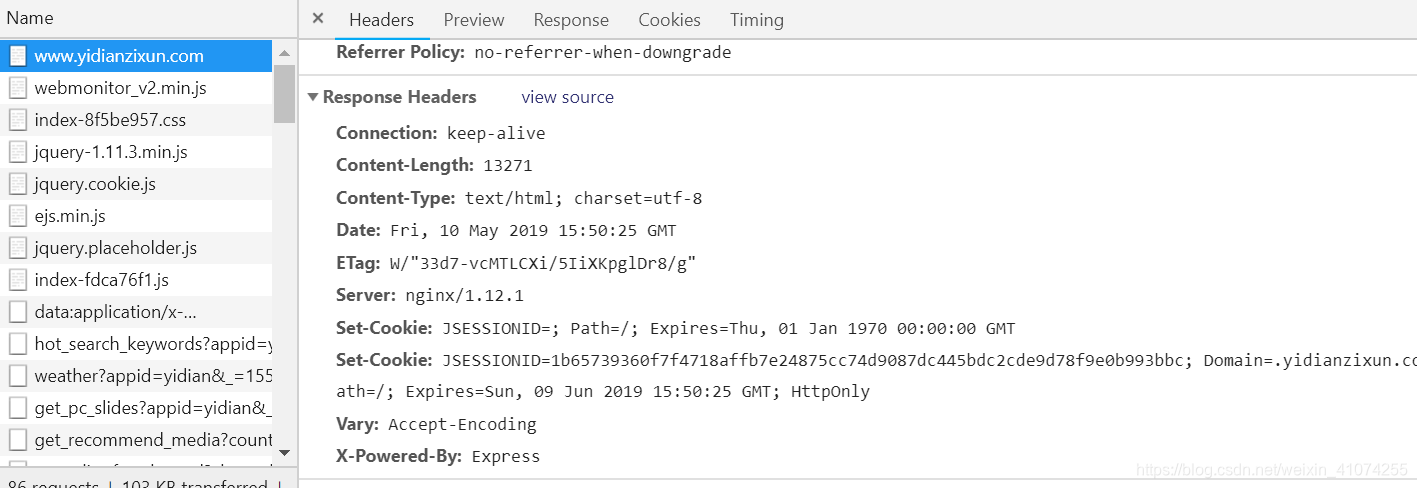
同时多次测试,发现每次清空缓存后,刷新页面,获取的JSESSIONID不同,同时同一频道对应的channel_id每次也都不同,因此判断JSESSIONID与channel_id存在对应关系,且一次请求可以获得一个JSESSIONID和对应的28个频道的channel_id
三、总结
1、注意点
- IP限制
请求次数过多会封ip,我在调试过程中就被封了,体现在清空缓存刷新页面时,它提示你 “暂无更新,休息一会儿”,同时请求频道对应的链接时,没有返回JSESSIONID值 - 获取JSESSIONID
请求链接获取JSESSIONID数据时,有一定几率失败,多加几次重试,且获取一次JSESSIONID可用时间很长,不必频繁
2、知识点
四、代码实现
import json
import re
import time
import requests
def get_spt(id, start=0, end=10):
str_par = 'sptoken{}{}{}'.format(id,start, end)
spt = ''
for key in str_par:
spt += chr(10^ord(key))
return spt
if __name__ == '__main__':
ids = set()
url = 'http://www.yidianzixun.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
}
while True:
response = requests.get(url, headers=headers, timeout=15)
if response.headers.get('Set-Cookie'):
Cookies = response.headers.get('Set-Cookie').split(';')
for cookie in Cookies:
if re.findall(r'JSESSIONID=(.+)', cookie, re.S):
set_cookie = re.findall(r'JSESSIONID=(.+)', cookie, re.S)[0]
else:
print('----获取cookies失败')
time.sleep(1)
continue
data_json = re.findall(r'window.yidian.docinfo.*?(\{.*?)</script>', response.text, re.S)[0].replace('\\x2f', '')
data_dict = json.loads(data_json)
channel_list = data_dict['user_info']['user_channels']
for j in range(5):
for channel in channel_list:
id = channel.get('fromId')
if not id:
print('no id')
continue
offset = 30
start, end = 0, offset
for i in range(300):
list_url = 'http://www.yidianzixun.com/home/q/news_list_for_channel?channel_id={}&cstart={}&cend={}&infinite=true&refresh=1&__from__=pc&multi=5&_spt={}&appid=web_yidian&_={}'.format(id, start, end, get_spt(id, start, end), int(time.time()*1000))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Referer': 'http://www.yidianzixun.com/channel/c3',
'Cookie': 'JSESSIONID={}'.format(set_cookie)
}
response = requests.get(list_url, headers=headers, timeout=15)
res_dict = json.loads(response.text)
if isinstance(res_dict, str):
print('---返回结果为字符串, response:{}'.format(res_dict))
continue
if res_dict.get('reason'):
print('-----抓取完成, resonse:{}, channel:{},data_list:{}, ids:{}, pg:{}, start:{}, end:{}'.format(res_dict.get('reason'), channel.get('name'), len(data_list), len(ids), i, start, end))
break
try:
data_list = res_dict['result']
except:
print(res_dict)
continue
for data in data_list:
if data['itemid'] not in ids:
ids.add(data['itemid'])
time.sleep(0.5)
print('-----channel:{},data_list:{}, ids:{}, pg:{}, start:{}, end:{}'.format(channel.get('name'), len(data_list), len(ids), i, start, end))
start, end = start+len(data_list), start+len(data_list)+offset