一,原理及流程介绍
1.基于内容的图像检索
在大型图像数据库上,CBIR技术用于检索在视觉上具有相似性的图像。这样返回的图像可以是颜色相似,纹理相似,图像中的物体或场景相似;总之,基本上可以是这些图像自身共有的任何信息。
对于高层查询,比如寻找相似物体,将查询图像与数据库中所有的图像进行完全比较(比如用特征匹配)往往是不可行的。在数据库很大的情况下,这样的查询方式,会耗费过多的时间。在过去的几年时间里,研究者成功地引入了文本挖掘技术到CBIR中处理问题,使在百万图像中搜索具有相似内容的图像成为可能。
2.视觉单词
为了将文本挖掘技术应用到图像中,我们首先需要建立视觉等效单词;这通常可以采用SIFT局部描述子可以做到。它的思想是将描述子空间量化成一些典型实例,并将图像中的每个描述子指派到其中的某个实例中。这些典型实例可以通过分析训练图像集确定,并被视为视觉单词。所有这些视觉单词构成的集合称为视觉词汇。从一个图像集中提取特征描述子,利用一些聚类算法可以构建出视觉单词。聚类算法中最常用的是K-means。视觉单词是在给定特征描述子空间中的一组向量集,在采用K-means进行聚类时得到的视觉单词是聚类质心。用视觉单词直方图来表示图像,则该模型便称为BOW模型。
3.特征提取
特征提取就是通过我们常用的sifi方法,提取图像的特征。
4. 针对输入特征集,根据视觉词典进行量化
对于输入特征,量化的过程是将该特征映射到距离其最接近的视觉单词,并实现计数。
5. 把输入图像,根据TF-IDF转化成视觉单词(visual words)的频率直方图
6.构造特征到图像的倒排表,通过倒排表快速索引相关图像
7.根据索引结果进行直方图匹配
二,代码及结果实现
实验代码如下图所示:
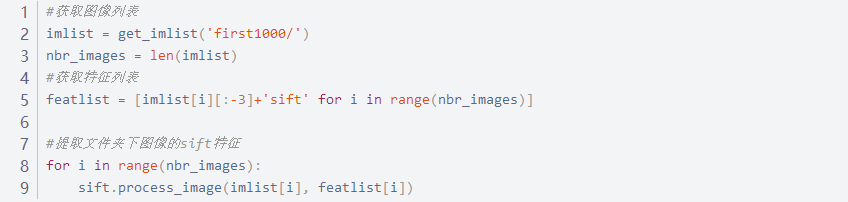

在文件中生成vocabulary.pkl文件,遍历所有的图像,将它们的特征投影到词汇并提交到数据库

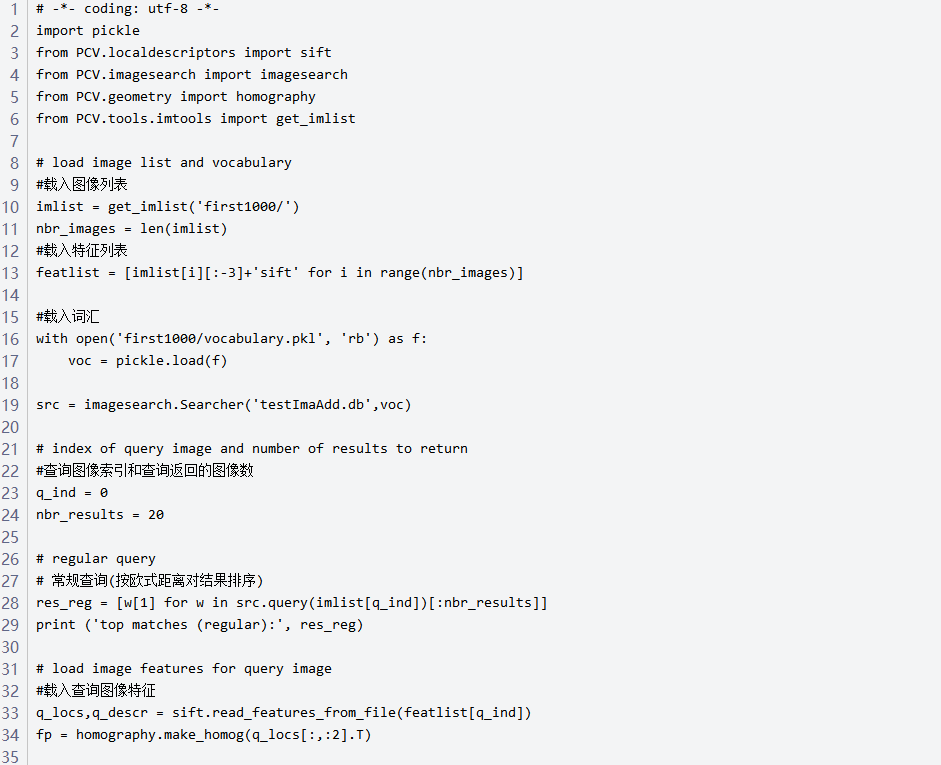

实验结果如图所示:

三,实验中出现的问题

解决方法:重新更换及安装pvc包