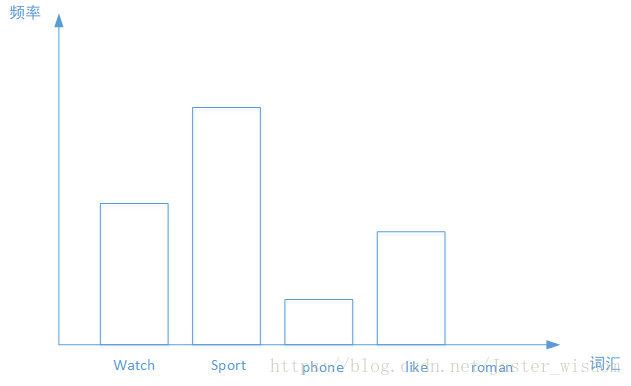
Bag-of-words词袋模型最初被用在信息检索领域,对于一篇文档来说,假定不考虑文档内的词的顺序关系和语法,只考虑该文档是否出现过这个单词。假设有5类主题,我们的任务是来了一篇文档,判断它属于哪个主题。在训练集中,我们有若干篇文档,它们的主题类型是已知的。我们从中选出一些文档,每篇文档内有一些词,我们利用这些词来构建词袋。我们的词袋可以是这种形式:{‘watch’,'sports','phone','like','roman',……},然后每篇文档都可以转化为以各个单词作为横坐标,以单词出现的次数为纵坐标的直方图,如下图所示,之后再进行归一化,将每个词出现的频数作为文档的特征。
近几年,在图像领域,使用Bag-of-words方法也是取得了较好的结果。如果说文档对应一幅图像的话,那么文档内的词就是一个图像块的特征向量。一篇文档有若干个词构成,同样的,一幅图像由若干个图像块构成,而特征向量是图像块的一种表达方式。我们求得N幅图像中的若干个图像块的特征向量,然后用k-means算法把它们聚成k类,这样我们的词袋里就有k个词,然后来了一幅图像,看它包含哪些词,包含单词A,就把单词A的频数加1。最后归一化,得到这幅图像的BoW表示,假如k=4,每幅图像有8个小块(patch),那么结果可能是这样的:[2,0,4,2],归一化之后为[0.25,0,0.5,0.25]。
同样,在语音识别领域,也有Bag-of-words方法也大施了拳脚。假设一段语音信号有2秒长,我们取每帧长40ms,帧移10ms,就可以得到一小段一小段的语音信号,然后提取每一小段上的音频特征,假设这里使用12维MFCC,那么有多少个小段语音信号,就有多少个MFCC特征向量。我们的目标是来一段语音信号,判断它的情感类别。我们的做法是:取一定数量的MFCC特征向量,将它们聚成k个类,那么这里的词袋里的词就是这k个类别。对于一段语音信号,我们对其进行分段之后,将各小段分配到这k个类别上,那么,每个类别上就对应了这一段语音信号里属于该类的段的个数。最后归一化,得到其特征表示。