环境
spark-1.6
python3.5
1、python开发spark原理
使用python api编写pyspark代码提交运行时,为了不破坏spark原有的运行架构,会将写好的代码首先在python解析器中运行(cpython),Spark代码归根结底是运行在JVM中的,这里python借助Py4j实现Python和Java的交互,即通过Py4j将pyspark代码“解析”到JVM中去运行。例如,在pyspark代码中实例化一个SparkContext对象,那么通过py4j最终在JVM中会创建scala的SparkContext对象及后期对象的调用、在JVM中数据处理消息的日志会返回到python进程中、如果在代码中会回收大量结果数据到Driver端中,也会通过socket通信返回到python进程中。这样在python进程和JVM进程之间就有大量通信。
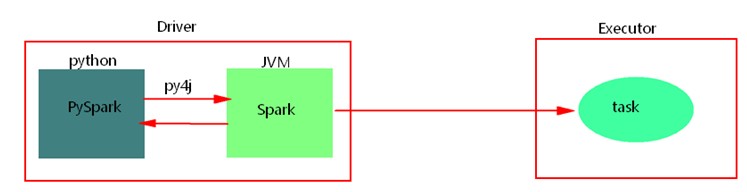
python开发spark,需要进行大量的进程间的通信,如果通信量过大,会出现“socket write error”错误,应尽量少使用回收数据类算子,也可以调节回收日志的级别,降低进程之间的通信。
2、版本选择
这里使用Spark1.6版本,由于Spark2.1以下版本不支持python3.6版本,所以我们使用兼容性比较好的Python3.5版本。
3、搭建
步骤一:搭建python3.5环境
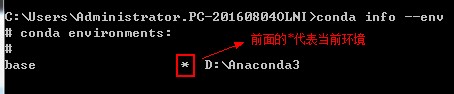
(1)conda info --env可以看到所有python环境,前面有个‘*’的代表当前环境
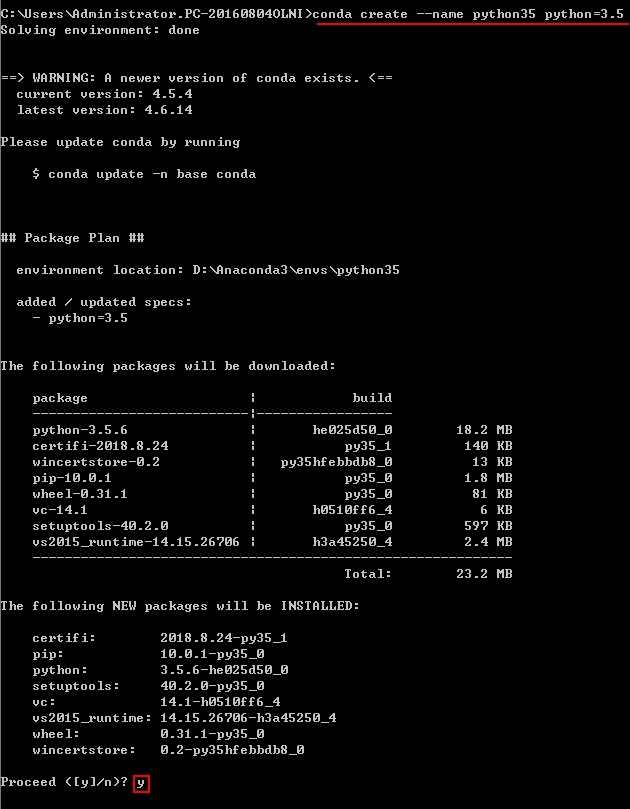
(2)创建Python3.5环境
conda create --name python35 python=3.5
扫描二维码关注公众号,回复:
6221800 查看本文章

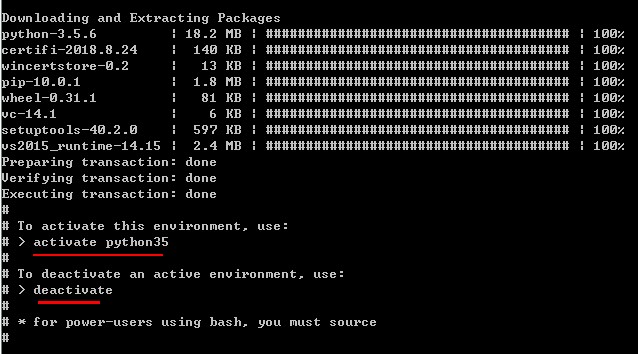
创建成功之后:

(3)激活python35:
