MySQL PT工具pt-online-schema-change
MySQL PT工具pt-online-schema-change
1、pt-osc 原理
1.1 工作过程
1.2 限制
1.3 pt-osc VS ONLINE DDL 如何选择
1.4 具体操作
1.5 . posc唯一键索引
1.6 ptosc 对从库做表修改
1.7 阿里云环境
2、例子
2.1 修改表
2.2 控制指定从库延迟
3、选项
1、pt-osc 原理
1.1 工作过程
1.2 限制
1.3 pt-osc VS ONLINE DDL 如何选择
1.4 具体操作
1.5 . posc唯一键索引
1.6 ptosc 对从库做表修改
1.7 阿里云环境
2、例子
2.1 修改表
2.2 控制指定从库延迟
3、选项
1、pt-osc 原理
1.1 工作过程
- 检查更改表是否有主键或唯一索引,是否有触发器
- 检查修改表的表结构,创建一个临时表,在新表上执行ALTER TABLE语句
- 在源表上创建三个after类型触发器分别对于INSERT UPDATE DELETE操作
- 从源表拷贝数据到临时表,在拷贝过程中,对源表的更新操作会写入到新建表中
- 将临时表和源表rename(需要元数据修改锁,需要短时间锁表)
- 删除源表和触发器,完成表结构的修改。
1.2 限制
- 源表必须有主键或唯一索引,如果没有工具将停止工作
- 如果线上的复制环境过滤器操作过于复杂,工具将无法工作
- 如果开启复制延迟检查,但主从延迟时,工具将暂停数据拷贝工作
- 如果开启主服务器负载检查,但主服务器负载较高时,工具将暂停操作
- 当表使用外键时,如果未使用--alter-foreign-keys-method参数,工具将无法执行
- 只支持Innodb存储引擎表,且要求服务器上有该表1倍以上的空闲空间。
1.3 pt-osc VS ONLINE DDL 如何选择
- online中no-rebuild table 优先选online ,仅修改元数据
- pt-osc在目标表上已经存在触发器时,不可用(5.7支持原表上有触发器)
- pt-osc 要操作的表没有主键唯一键,或者有复制过滤
- 需要对从库修改,online , pt-osc丢数据
- 添加唯一键索引,online
1.4 具体操作
6165 Query CREATE TRIGGER `pt_osc_confluence_sbtest3_del` AFTER DELETE ON `confluence`.`sbtest3` FOR EACH ROW DELETE IGNORE FROM `confluence`.`_sbtest3_new` WHERE `confluence`.`_sbtest3_new`.`id` <=> OLD.`id`
6165 Query CREATE TRIGGER `pt_osc_confluence_sbtest3_upd` AFTER UPDATE ON `confluence`.`sbtest3` FOR EACH ROW REPLACE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) VALUES (NEW.`id`, NEW.`k`, NEW.`c`, NEW.`pad`)
6165 Query CREATE TRIGGER `pt_osc_confluence_sbtest3_ins` AFTER INSERT ON `confluence`.`sbtest3` FOR EACH ROW REPLACE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) VALUES (NEW.`id`, NEW.`k`, NEW.`c`, NEW.`pad`)
#并且copy操作是:
6165 Query INSERT LOW_PRIORITY IGNORE INTO `confluence`.`_sbtest3_new` (`id`, `k`, `c`, `pad`) SELECT `id`, `k`, `c`, `pad` FROM `confluence`.`sbtest3` FORCE INDEX(`PRIMARY`) WHERE ((`id` >= '4692805')) AND ((`id` <= '4718680')) LOCK IN SHARE MODE /*pt-online-schema-change 46459 copy nibble*/在原表上update,新临时表上是replace into整行数据,所以达到有则更新,无则插入。同时配合后面的 insert ignore,保证这条数据不会因为重复而失败。
1.5 . posc唯一键索引
#在不对原表DML情况下, INSERT LOW_PRIORITY IGNORE INTO 会丢数据
mysql> create table t1(id int primary key , name varchar(10));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t1 values (1,'a'),(2,'b'),(3,'a');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t1
-> ;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | a |
+----+------+
3 rows in set (0.00 sec)
mysql> create table t1_tmp like t1;
Query OK, 0 rows affected (0.02 sec)
mysql> alter table t1_tmp add unique udx_name(name);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> INSERT LOW_PRIORITY IGNORE INTO t1_tmp select * from t1 lock in share mode;
Query OK, 2 rows affected (0.00 sec)
Records: 3 Duplicates: 1 Warnings: 0
mysql> select * from t1_tmp;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
+----+------+
2 rows in set (0.00 sec)
#原表DML情况下,tmp表操作是replace into 也会丢 所以,加唯一键索引,一定谨慎,1.6 ptosc 对从库做表修改
https://dev.mysql.com/doc/refman/5.7/en/replication-features-triggers.html
With row-based replication, triggers executed on the master do not execute on the slave. Instead。
从库触发器会忽略来自主库更新避免二次触发
验证:
对从库加索引,加索引期间,在主库DML,看插入的数据在新表中有没有
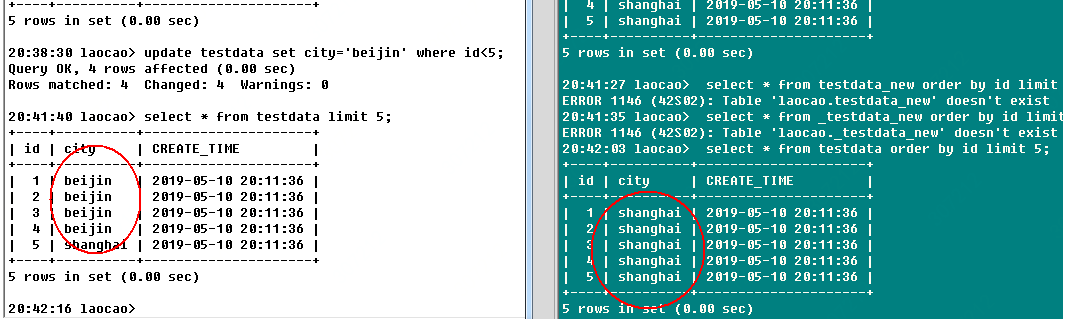
验证,从库触发器忽略SQL线程过来的DML,对从库pt-osc会丢数据
1.7 阿里云环境
这个错误在阿里云RDS上执行时出现的,我以为是我哪里语法写错了, 加上--no-version-check选项就好了,
见 http://www.linuxidc.com/Linux/2016-08/134764.htm ,
没深究,应该是pt去验证mysql server版本的时候从rds拿到的信息不对,导致格式出错。
2、例子
2.1 修改表
/bin/pt-online-schema-change --no-version-check --dry-run --print \
--alter "ALGORITHM=INPLACE,add index idx_userid_createtime(user_id,create_time)" --recursion-method=none --charset utf8 \
--user= --password='' --host=rm-bp13xy75phh7c60em.mysql.rds.aliyuncs.com --port=3306 D=bx_app_chatroom,t=t_chatroom_enter_log 2.2 控制指定从库延迟
/bin/pt-online-schema-change --no-version-check --dry-run --print \
--alter "ALGORITHM=INPLACE,add index idx_userid_createtime(user_id,create_time)" --recursion-method=none --charset utf8 \
--user= --password='' --host=rm-bp13xy75phh7c60em.mysql.rds.aliyuncs.com --port=3306 D=bx_app_chatroom,t=t_chatroom_enter_log \
--max-lag=10 --check-interval=2 --check-slave-lag u=,p='',h=rr-bp1g39097fn0syq06.mysql.rds.aliyuncs.com,P=3306/bin/pt-online-schema-change --no-version-check --alter-foreign-keys-method=none --force --recursion-method=none --charset utf8 \
--critical-load Threads_connected:1000,Threads_running:360 --alter "add index idx_userid_createtime(user_id,create_time)" \
--user= --password='' --host=rm-bp13xy75phh7c60em.mysql.rds.aliyuncs.com --port=3306 D=bx_app_chatroom,t=t_chatroom_enter_log \
--max-lag=10 --check-interval=1 --check-slave-lag u=,p='',h=rr-bp1g39097fn0syq06.mysql.rds.aliyuncs.com,P=3306 --execute --print 3、选项
--alter-foreign-keys-method
为什么外键需要特殊处理,因为rename 原始表 t1,外键跟随了重命名后的t1表了,而必须修改为新表
pt工具支持两种方法来完成这一点:
1. auto
自动选择,优先rebuild_constraints,否则drop_swap
2. rebuild_constraints
优先的方法,删除在子表上的外键约束并重新建立对新表B的外键参照约束.
这里有一个例外,当子表(或多个) 的alter时间大于–chunk-time,这时不会选用rebuild_constraints方式.这里还有一点要注意,新的外键名称会有所改变.
3. drop_swap
设置FOREIGN_KEY_CHECKS=0,之后DROP原表A,再重全名新表B为A的名称.
风险:
一是有段时间原表A是还存在的!应用程序如果查询到A,会报错;
二是如果由于错误发生,不能成功将新表B重全名为A的名称时,后果是灾难性的,A的数据永久的丢失了!
4. none:类似于drop_swap,但少了重全名这个阶段,可由DBA手动完成
--max-load
默认为Threads_running=25。 如果超过,则先暂停。 因为拷贝行有可能会给部分行上锁,Threads_running 是判断当前数据库负载的绝佳指标。“Threads_connected:110”
--critical-load
类型:数组; 默认值:Threads_running = 50 , 负载太高则中止。
--max-lag
类型:时间; 默认值:1s , 暂停直到小于max-lag, --check-interval seconds, --check-slave-lag,用于如果要精确控制工具监视的服务器
--recursion-method, 发现从库的方式 , none, processlist, hosts , dsn=DSN , 对于云数据库processlist 和hosts都不可行, DSN需要写入在库表中, 如果指定--check-slave-lag, 可以--recursion-method=none
--chunk-time
默认0.5s,即拷贝数据行的时候,为了尽量保证0.5s内拷完一个chunk,动态调整chunk-size的大小,以适应服务器性能的变化。
也可以通过另外一个选项--chunk-size禁止动态调整,即每次固定拷贝 1k 行,如果指定则默认1000行,且比 chunk-time 优先生效
--dry-run
创建和修改新表,但不会创建触发器、复制数据、和替换原表。并不真正执行,可以看到生成的执行语句,了解其执行步骤与细节,和--print配合最佳。。
--execute
确定修改表,则指定该参数。真正执行alter。–dry-run与–execute必须指定一个,二者相互排斥