目标网站:静听网
网站url:http://www.audio699.com/
目标文件:所有在线听的音频文件
附:我有个喜好就是晚上睡觉听有声书,然而很多软件都是付费才能听,免费在线网站虽然能听,但是禁ip很严重,就拿静听网来说,你听一个在线音频,不能一个没听完就点击下一集,甚至不能快进太快,否则直接禁你5分钟才能再听,真的是太太讨厌了...
于是我就想用爬虫给它爬下来存储本地就nice了.
我把我的大概分析步骤分享出来.
步骤1:
我查看静听网网页url有一个规律,基网址是http://www.audio699.com/book/,每本书对于一个唯一标识,比如 《借种》 这本书的url如下:(唯一标识1276)
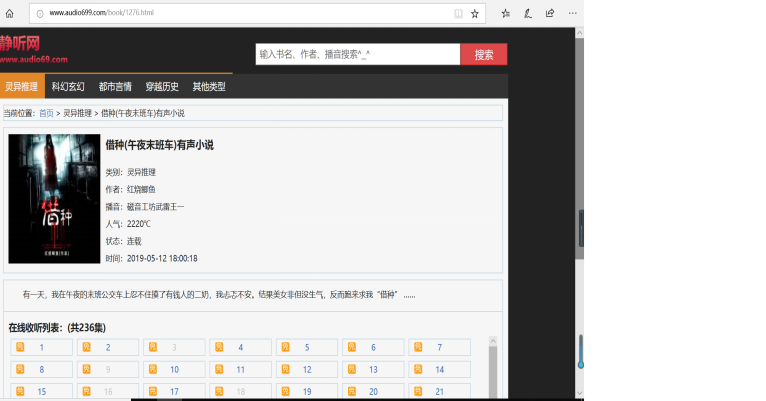
步骤2:
分析html源码:我发现这个网站的每本书的每一集的url就是再上述url后添加集数,并且网页html中包含了音频文件的src如下:
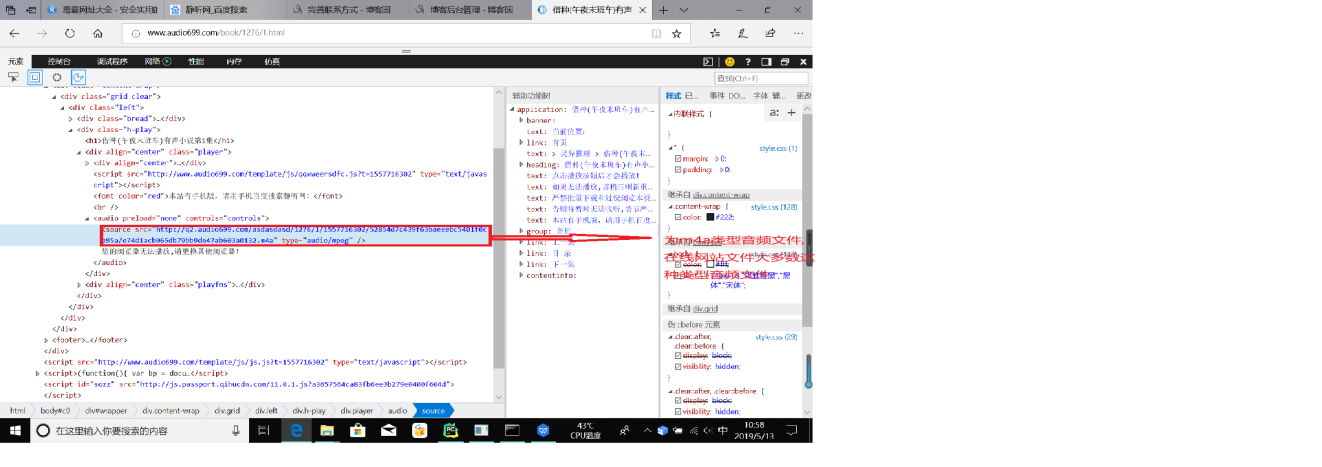
到这里我有点奇怪,这个网站封ip这么严,为什么src会直接放在静态网页中暴露如此明显,我尝试着随便复制一个src,使用python下载这个文件,嗯,瞬间就下载好了,我心想python还真不错,然而当我播放下载好的m4a文件时,发现只有5s,里面传来熟悉的声音"您访问过快,请5分钟后刷新网页重新访问",,,我心想果然没那么简单。。。
然后我重新打开网页获取刚才那个src发现src的值竟然变了,我经过测试发现这个src几乎时时刻刻都在变化,且毫无规律.
哼,想到这里我其实反倒松了口气,只要我用代码实时获取src并且开始下载应该就能解决这个问题吧,于是我测试了一下我的想法
果不其然,这样的确可以下载成功,但是这样一个一个下载速度太慢,一本有声书可是有好几百集音频文件,一集一集下不现实,于是我便用了多线程和多进程下载,
编写好python代码后,测试发现刚开始还行,但下了不到10个音频后出现错误,403 forbidden,503 service unaviable,意思是远程计算机拒绝我的计算机访问网页,文件传输服务不可用,就是这一系列的错误,就是禁了我的ip
我最开始本来想到要不要构建个ip代理池,我心想我的不同进程访问的网页url都不相同,应该没有什么大问题,哎,看来不能偷懒啊,于是我又到西刺高匿代理网站爬取了一些代理ip,我还专门写了一个筛选脚本,筛选能够成功获取目标网页html的ip,改写代码后,再次尝试,发现虽然没有再出现403等错误,但是下载成功率低的惊人,开30个线程,200个代理ip,等了半小时回来看,
tmd,才下好5,6个文件,很多文件只有十几k,看着贼烦,哎,看来这免费ip质量还是不行,存活时间太短,于是我只好到大象代理网站买了ip(一天9元好贵),然后经过
筛选再次爬取,这次一共爬200个音频,等了半个小时运行结束,发现大概下载成功了170个文件,其他文件要么直接0k,要么残缺不全,,,
为此我又写了一个脚本,专门用于下载文件夹中下载失败的文件,这次我采用多进程方式下载,写完后运行,等了一会,发现程序运行差不多了,但没运行结束,我直接结束运行,发现原来的30个残缺文件只有极少数几个还没下载成功,我筛选ip再运行脚本,这次很快就下好了,看来筛选出ip很重要,
接下来我又改进了脚本的一些地方,多线程,多进程个写了一个,配合着下载能够完全将几百集的音频文件全部下载下来.
由于脚本有点长,就不在这里贴了,我有时间会上传到CSDN,或者可以加群582562078@群主索要,加我qq2407327377也可,亦或给我留言我发你邮箱.
另外我为了晚上听书不用手动点击下一集,还专门瞎写了一个音视频播放器,可以实现自动播放,定时关闭,定集关闭,预约集数播放,预约时间播放等各种小功能.
需要的话可加群@群主索要
(附录:购买的ip你可以一次性存储多一点,我存储了4000来个ip,发现经过筛选,可以成功下载不同的书的音频)
后记:哎,一切都是为了免费,为了能够简化操作,为了能够更享受,而这也不就正是我们继续前进的动力嘛.