讲一下大概的思路:
数据有训练集(已分词的),词表,测试集(未分词的),测试集(已分词的),总共四个文件夹,具体看下面的截图。
训练集:
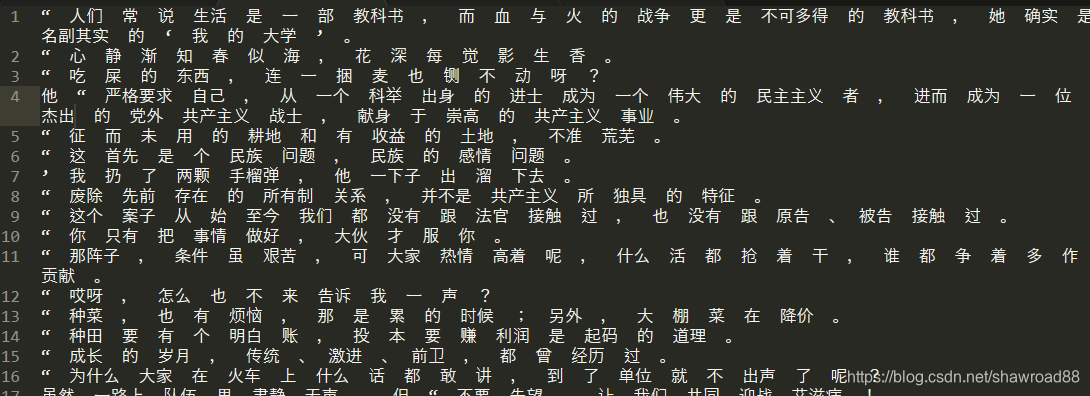
词表:

测试集(未分词的)

测试集(已分词的)

首先整理汉字到id的映射,就是将词表读入,然后将所有词连接起来,统计每个词出现的次数,进行排序,然后进行id的一一映射。
然后,我们定义五种标签,分别是s(单个字成词,用数字0代替),b(一个长词的第一个字,用数字1代替),m(一个长词中间的那些字,用数字2代替),e(一个长词的最后一个字,用数字3代替),x(填充的,用数字4代替)。举个例子:“街头霸王”这个词所对应的标签就是 bmme,对应的数字就是1223。 为什么要这么做? 你当前先把它理解为,你做分类问题时,最终分类的那些类别。。
接着,我们把训练集(已分词的)读进来,通过一些符号进行分类。最后就形成了一些短的句子。但是句子中的词还是用空个分开的。。我们现在给每个词中的汉字进行打标签。。因为这些词是已经分好的词,所以标签是非常好标的。。这里还需要把对应的汉字转换为数字
定义模型,利用双向的LSTM,最后经过一个softmax,让其输出五个概率值(即 属于s,b,m,e,x的概率)
这里必须知道一个知识就是HMM,并且知道解它的一个算法:维特比算法。。 然后才能继续往下看。。我就当大家都知道。
现在s,b,m,e,x可以看做HMM的五个隐状态它,每个状态它能已某种概率喷射出好多汉字。 这里的某种概率就是我们上面网络输出的概率。假设,我们现在有一句话“我喜欢西安,并且喜欢这里的没事”。 如果模型训练好,将这句话喂给模型,最后,输出的是:每一个词都输出5种概率,这里你可以理解为:五种隐状态喷射这个汉字的五种概率。在HMM中,还需要有状态之间的转移概率,我们这里认为的设置为:两种状态之间的转换概率都是0.5。。如下图所示:

通过双向的LSTM实现
数据来源:点我下载
数据介绍:

代码走起:
1:导入我们所需要的工具包
# 将数据整理并进行字嵌入(Character Embedding)之后,使用Keras实现双向LSTM进行序列标注
from keras.layers import Input, Dense, Embedding, LSTM, Dropout, TimeDistributed, Bidirectional
from keras.models import Model, load_model
from keras.utils import np_utils
import numpy as np
import re
2:我们先读取词表,然后整理词和id之间的映射。这是自然语言中常规套路。。具体词表的样子是:

我们现在要将所有词连接起来,然后统计字的个数,并将字与id对应。。
# 读取字典 词表而已
vocab = open('data/msr/msr_training_words.utf8').read().rstrip('\n').split('\n') # 去除右边的换行,并按换行分割
vocab = list(''.join(vocab)) # 将所有词连接成一个大的字符串,然后转换为list 也就是说列表中每个元素为对应的字符
stat = {}
for v in vocab:
stat[v] = stat.get(v, 0) + 1
stat = sorted(stat.items(), key=lambda x:x[1], reverse=True)
vocab = [s[0] for s in stat] # 取出每一个字
# 5167 个字
print(len(vocab)) # 看一下总的字个数
# 映射
char2id = {c: i + 1 for i, c in enumerate(vocab)}
id2char = {i + 1: c for i, c in enumerate(vocab)}3:指定一系列标签:sbmex, 并定义一些我们模型所需要的参数
# 这个tags就是我们最后的标签。
tags = {'s': 0, 'b': 1, 'm': 2, 'e': 3, 'x': 4} # 进行的一些标注 x为填充的
# 定义模型所需要的一些参数
embedding_size = 128 # 字嵌入的长度
maxlen = 32 # 长于32则截断,短于32则填充0
hidden_size = 64
batch_size = 64
epochs = 504:开始整理输入数据和标签。就是给训练数据打标签。并将对应的汉字转化为数字。。这里的转化用的就是词表中整理的映射。
# 定义一个读取并整理数据的函数
def load_data(path):
data = open(path).read().rstrip('\n')
# 按标点符号和换行符分隔
data = re.split('[,。!?、\n]', data) # 按 ,。!?、 \n 对数据进行分割 就是将一些句子切分成很小的一句话
print('共有数据 %d 条' % len(data)) # 385152条数据
print('平均长度:', np.mean([len(d.replace(' ', '')) for d in data])) # 大概是9.74
# 准备数据
X_data = []
y_data = []
for sentence in data:
sentence = sentence.split(' ') # 按空格切分这些已经被切分的很小的句子
X = []
y = []
try:
for s in sentence:
s = s.strip()
# 跳过空字符
if len(s) == 0:
continue
# s
elif len(s) == 1:
# 一个字能够独立构成词的话 标记为s
X.append(char2id[s])
y.append(tags['s'])
elif len(s) > 1:
# 如果多个字构成一个词, 第一个字标记为b 最后一个字标记为e 中间所有的字标记为m
# b
X.append(char2id[s[0]])
y.append(tags['b'])
# m
for i in range(1, len(s) - 1):
X.append(char2id[s[i]])
y.append(tags['m'])
# e
X.append(char2id[s[-1]])
y.append(tags['e'])
# 统一长度 一个小句子的长度不能超过32,否则将其切断。只保留32个
if len(X) > maxlen:
X = X[:maxlen]
y = y[:maxlen]
else:
for i in range(maxlen - len(X)): # 如果长度不够的,我们进行填充,记得标记为x
X.append(0)
y.append(tags['x'])
except:
continue
else:
if len(X) > 0:
X_data.append(X) # [ [ [ 每个词语中字转换为对应的id构成的列表 ], [], [], [] ...], [], [], [], []...]
y_data.append(y) # [ [ [每个词语中对应字的标注,有四种标记,构成的列表], [], [], []...], [], [], []...]
X_data = np.array(X_data)
y_data = np_utils.to_categorical(y_data, 5) # 将y搞成one_hot编码
return X_data, y_data
X_train, y_train = load_data('data/msr/msr_training.utf8') # 读取的这个文档是一个已经分好词的文本
X_test, y_test = load_data('data/msr/msr_test_gold.utf8')
print('X_train size:', X_train.shape) # (385152, 32)
print('y_train size:', y_train.shape) # (385152, 32, 6)
print('X_test size:', X_test.shape) # (17917, 32)
print('y_test size:', y_test.shape) # (17917, 32, 5)5:定义模型,并进行训练。这里使用的双向的LSTM。。 注意看注释。最后我们将模型保存起来
# 定义模型
X = Input(shape=(maxlen,), dtype='int32')
# mask_zero的含义:我们在有些长度不够的字符串后面进行了零填充,这样在字嵌入的过程中,就会忽略这些零的存在
embedding = Embedding(input_dim=len(vocab) + 1, output_dim=embedding_size, input_length=maxlen, mask_zero=True)(X)
# 一般情况下,LSTM只会输出最后一层的输出,但是将return_sequences置为True 则会显示所有步的输出,所以他的输出和输入的长短就是一致的
# Bidirectional实现双向的LSTM 将正向的输出和反向的输出拼接到一起
blstm = Bidirectional(LSTM(hidden_size, return_sequences=True), merge_mode='concat')(embedding)
blstm = Dropout(0.6)(blstm)
blstm = Bidirectional(LSTM(hidden_size, return_sequences=True), merge_mode='concat')(blstm)
blstm = Dropout(0.6)(blstm)
# TimeDistributed作用: 上面的LSTM的return_sequences还是True 说明还是返回的一个长序列。
# 我们需要将长序列中的每一项都要进行softmax,这就是TimeDistributed的作用
output = TimeDistributed(Dense(5, activation='softmax'))(blstm) # 此时的output形状 (batch_size, 32, 5)
model = Model(X, output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs)
model.save('msr_bilstm.h5')
# 查看模型在训练集和测试集上的分词正确率
print(model.evaluate(X_train, y_train, batch_size=batch_size))
print(model.evaluate(X_test, y_test, batch_size=batch_size))6:实现维特比算法,找最好的一组隐态,让其能更好的生成咱们的输入数据(这里专业术语叫做观测值)
# 定义维特比函数,使用动态规划算法获得最大概率路径
def viterbi(nodes):
trans = {'be': 0.5, 'bm': 0.5, 'eb': 0.5, 'es': 0.5, 'me': 0.5, 'mm': 0.5, 'sb': 0.5, 'ss': 0.5}
paths = {'b': nodes[0]['b'], 's': nodes[0]['s']}
for l in range(1, len(nodes)):
paths_ = paths.copy()
paths = {}
for i in nodes[l].keys():
nows = {}
for j in paths_.keys():
if j[-1] + i in trans.keys():
nows[j + i] = paths_[j] + nodes[l][i] + trans[j[-1] + i]
nows = sorted(nows.items(), key=lambda x: x[1], reverse=True)
paths[nows[0][0]] = nows[0][1]
paths = sorted(paths.items(), key=lambda x: x[1], reverse=True)
return paths[0][0]7:使用训练好的模型进行分词
# 使用训练好的模型定义分词函数
def cut_words(data):
data = re.split('[,。!?、\n]', data) # 来一句话,我们先进行切分,因为我们的输入限制在32
sens = []
Xs = []
for sentence in data:
sen = []
X = []
sentence = list(sentence)
for s in sentence:
s = s.strip()
if not s == '' and s in char2id:
sen.append(s)
X.append(char2id[s])
if len(X) > maxlen:
sen = sen[:maxlen]
X = X[:maxlen]
else:
for i in range(maxlen - len(X)):
X.append(0)
if len(sen) > 0:
Xs.append(X)
sens.append(sen)
Xs = np.array(Xs)
ys = model.predict(Xs) # 对每个字预测出五种概率,其中前四个概率是我们需要的,最后一个概率是对空的预测
results = ''
for i in range(ys.shape[0]):
# 将每个概率与sbme对应构成字典 [{s:*, b:*, m:*, e:*}, {}, {}...]
nodes = [dict(zip(['s', 'b', 'm', 'e'], d[:4])) for d in ys[i]]
ts = viterbi(nodes)
for x in range(len(sens[i])):
if ts[x] in ['s', 'e']:
results += sens[i][x] + '/'
else:
results += sens[i][x]
return results[:-1]
# 调用分词函数
print(cut_words('中国共产党第十九次全国代表大会,是在全面建成小康社会决胜阶段、中国特色社会主义进入新时代的关键时期召开的一次十分重要的大会。'))
print(cut_words('把这本书推荐给,具有一定编程基础,希望了解数据分析、人工智能等知识领域,进一步提升个人技术能力的社会各界人士。'))
print(cut_words('结婚的和尚未结婚的。'))8:也可以重新写一个程序,专门用来调用模型进行分词
from keras.models import Model, load_model
import numpy as np
import re
# 读取字典
vocab = open('data/msr/msr_training_words.utf8').read().rstrip('\n').split('\n')
vocab = list(''.join(vocab))
stat = {}
for v in vocab:
stat[v] = stat.get(v, 0) + 1
stat = sorted(stat.items(), key=lambda x: x[1], reverse=True)
vocab = [s[0] for s in stat]
# 5167 个字
print(len(vocab))
# 映射
char2id = {c: i + 1 for i, c in enumerate(vocab)}
id2char = {i + 1: c for i, c in enumerate(vocab)}
tags = {'s': 0, 'b': 1, 'm': 2, 'e': 3, 'x': 4}
maxlen = 32 # 长于32则截断,短于32则填充0
model = load_model('msr_bilstm.h5')
def viterbi(nodes):
trans = {'be': 0.5, 'bm': 0.5, 'eb': 0.5, 'es': 0.5, 'me': 0.5, 'mm': 0.5, 'sb': 0.5, 'ss': 0.5}
paths = {'b': nodes[0]['b'], 's': nodes[0]['s']}
for l in range(1, len(nodes)):
paths_ = paths.copy()
paths = {}
for i in nodes[l].keys():
nows = {}
for j in paths_.keys():
if j[-1] + i in trans.keys():
nows[j + i] = paths_[j] + nodes[l][i] + trans[j[-1] + i]
nows = sorted(nows.items(), key=lambda x: x[1], reverse=True)
paths[nows[0][0]] = nows[0][1]
paths = sorted(paths.items(), key=lambda x: x[1], reverse=True)
return paths[0][0]
def cut_words(data):
data = re.split('[,。!?、\n]', data)
sens = []
Xs = []
for sentence in data:
sen = []
X = []
sentence = list(sentence)
for s in sentence:
s = s.strip()
if not s == '' and s in char2id:
sen.append(s)
X.append(char2id[s])
if len(X) > maxlen:
sen = sen[:maxlen]
X = X[:maxlen]
else:
for i in range(maxlen - len(X)):
X.append(0)
if len(sen) > 0:
Xs.append(X)
sens.append(sen)
Xs = np.array(Xs)
ys = model.predict(Xs)
results = ''
for i in range(ys.shape[0]):
nodes = [dict(zip(['s', 'b', 'm', 'e'], d[:4])) for d in ys[i]]
ts = viterbi(nodes)
for x in range(len(sens[i])):
if ts[x] in ['s', 'e']:
results += sens[i][x] + '/'
else:
results += sens[i][x]
return results[:-1]
print(cut_words('中国共产党第十九次全国代表大会,是在全面建成小康社会决胜阶段、中国特色社会主义进入新时代的关键时期召开的一次十分重要的大会。'))
print(cut_words('把这本书推荐给,具有一定编程基础,希望了解数据分析、人工智能等知识领域,进一步提升个人技术能力的社会各界人士。'))
print(cut_words('结婚的和尚未结婚的。'))最后的输出结果:

分词效果还是不错的。。