NameNode和Secondary NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息(目录)。
下面来看看它们的工作机制:
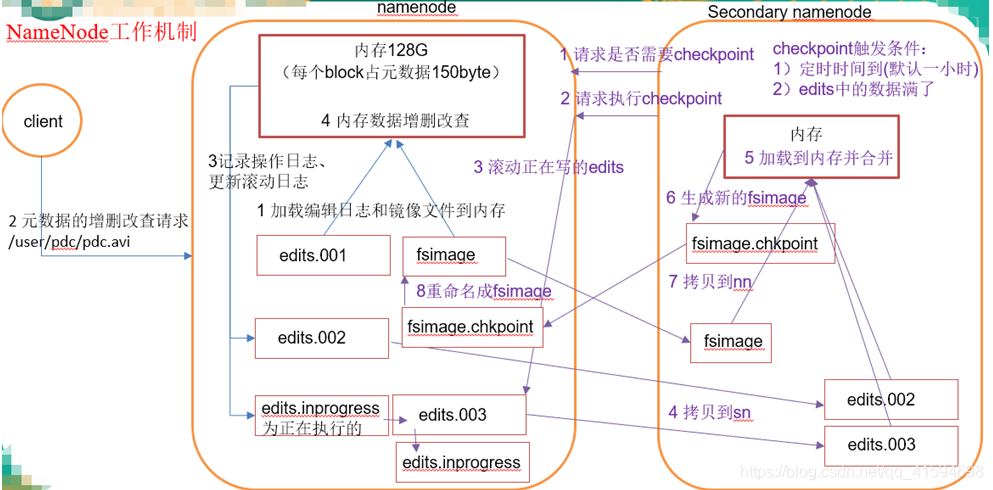
流程详解:
-
1.第一阶段:namenode启动
(1)第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求
(3)namenode记录操作日志,更新滚动日志。
(4)namenode在内存中对数据进行增删改查(基于内存,增快速度)。 -
2.第二阶段:Secondary NameNode工作(进行合并工作,减少nn压力,解耦)
(1)Secondary NameNode询问namenode是否需要checkpoint(即是否需要合并edits和fsimage)。直接带回namenode是否检查结果。
(2)Secondary NameNode请求执行checkpoint。
(3)namenode滚动正在写的edits日志, inprogress变为003,并生成新的inprogress
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode,即edit2、edit3、fsimage
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint
(7)拷贝fsimage.chkpoint到namenode
(8)namenode将fsimage.chkpoint重新命名成fsimage,此时,fsimage和inprogress都是最新的,又回到了最初的状态
注:可以看到,这两个任务都很耗费内存,所以拆分开来,用两个内存去跑,加快速度,所以两个节点不要放同一个机器,不然好处就体现不出来了
-
3.web端访问SecondaryNameNode
(1)启动集群
(2)浏览器中输入:http://pdc:50090/tatus.html
(3)查看SecondaryNameNode信息 -
4.chkpoint检查时间参数设置
配置文件:hdfs-default.xml
1)通常情况下,SecondaryNameNode每隔一小时执行一次。
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description>1分钟检查一次操作次数</description>
</property>