目录
- HDFS的工作机制
- 概述
- HDFS 写数据流程
- HDFS 读数据流程
- NameNode的工作机制
- NameNode的职责
- 元数据的管理
- 元数据的checkpoint
- DataNode的工作机制
- 观察验证DataNode功能
HDFS的工作机制
工作机制的学习主要是为加深对分布式系统的理解,以及增强遇到各种问题时的分析解决能力,形成一定的集群运维能力。
很多不是真正理解hadoop技术体系的人会常常觉得HDFS可用于网盘类应用,但实际并非如此。要想将技术准确用在恰当的地方,必须对技术有深刻的理解。
概述
- 1.HDFS集群分为两大角色:NameNode、DataNode
- 2.NameNode负责管理整个文件系统的元数据(元数据就是文件数据块放置在DataNode位置和数量等信息)
- 3.DataNode 负责管理用户的文件数据块
- 4.文件会按照固定的大小(Blocksize)切成若干块后分布式存储在若干台DataNode上
- 5.每一个文件块可以有多个副本,并存放在不同的DataNode上
- 6.DataNode会定期向NameNode汇报自身所保存的文件Block信息,NameNode则会负责保持文件的副本数量
- 7.HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向NameNode申请来进行
HDFS 写数据流程
- 概述
客户端要向HDFS写数据,首先要跟NameNode通信以确认可以写文件并获得接收文件Block的DataNode,然后,客户端按顺序将文件逐个block传递给相应DataNode,并由接收到block的DataNode负责向其他DataNode复制block的副本
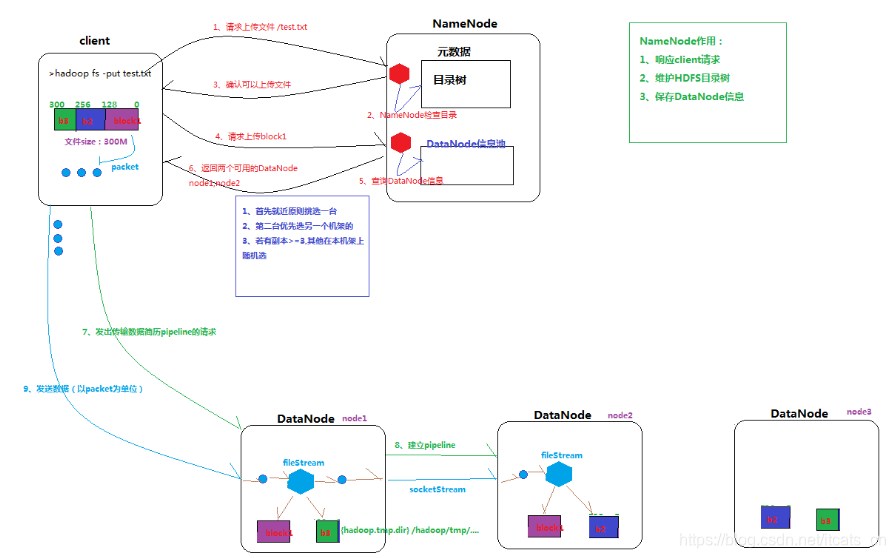
写数据步骤详解
1、Client向NameNode通信请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在
2、NameNode返回是否可以上传
3、Client请求第一个 block该传输到哪些DataNode服务器上
4、Namenode返回3个DataNode服务器ABC
5、Client请求3台DataNode中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,逐级返回客户端
6、Client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,Client再次请求Namenode上传第二个block的服务器。
HDFS 读数据流程
- 概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件

读数据步骤详解
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,先在本地缓存,然后写入目标文件
NameNode工作机制
namenode职责
负责客户端请求的响应
元数据的管理(查询,修改)
元数据管理
namenode对数据的管理采用了三种存储形式:
- 内存元数据(NameSystem)
- 磁盘元数据镜像文件
- 数据操作日志文件(可通过日志运算出元数据)
元数据存储机制
- A、内存中有一份完整的元数据(内存meta data)
- B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
- C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
- 注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
元数据手动查看
可以通过hdfs的一个工具来查看edits中的信息
bin/hdfs oev -i edits -o edits.xml
bin/hdfs oiv -i fsimage_0000000000000000087 -p XML -o fsimage.xml元数据的checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
checkpoint的详细过程

checkpoint操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} #以上两个参数做checkpoint操作时,secondary namenode的本地工作目录
dfs.namenode.checkpoint.max-retries=3 #最大重试次数
dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录
checkpoint的附带作用
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
DATANODE的工作机制
概述
Datanode工作职责:
1、存储管理用户的文件块数据
2、定期向namenode汇报自身所持有的block信息(通过心跳信息上报)(这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.
</description>
</property> Datanode掉线判断时限参数
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property> 观察验证DATANODE功能
上传一个文件,观察文件的block具体的物理存放情况:
在每一台datanode机器上的这个目录中能找到文件的切块:
/home/hadoop/app/hadoop-2.7.3/tmp/dfs/data/current/BP-193442119-192.168.88.3-1432458743457/current/finalized
参考文章:
