Springbean的作用域
bean的作用域
创建一个bean定义,其实质是用该bean定义对应的类来创建真正实例的“配方”。把bean定义看成一个配方很有意义,它与class很类似,只根据一张“处方”就可以创建多个实例。不仅可以控制注入到对象中的各种依赖和配置值,还可以控制该对象的作用域。这样可以灵活选择所建对象的作用域,而不必在Java Class级定义作用域。Spring Framework支持五种作用域,分别阐述如下表。
五种作用域中,request、session和global session三种作用域仅在基于web的应用中使用(不必关心你所采用的是什么web应用框架),只能用在基于web的Spring ApplicationContext环境。
(1)当一个bean的作用域为Singleton,那么Spring IoC容器中只会存在一个共享的bean实例,并且所有对bean的请求,只要id与该bean定义相匹配,则只会返回bean的同一实例。Singleton是单例类型,就是在创建起容器时就同时自动创建了一个bean的对象,不管你是否使用,他都存在了,每次获取到的对象都是同一个对象。注意,Singleton作用域是Spring中的缺省作用域。要在XML中将bean定义成singleton,可以这样配置:
<bean id="ServiceImpl" class="cn.csdn.service.ServiceImpl" scope="singleton">(2)当一个bean的作用域为Prototype,表示一个bean定义对应多个对象实例。Prototype作用域的bean会导致在每次对该bean请求(将其注入到另一个bean中,或者以程序的方式调用容器的getBean()方法)时都会创建一个新的bean实例。Prototype是原型类型,它在我们创建容器的时候并没有实例化,而是当我们获取bean的时候才会去创建一个对象,而且我们每次获取到的对象都不是同一个对象。根据经验,对有状态的bean应该使用prototype作用域,而对无状态的bean则应该使用singleton作用域。在XML中将bean定义成prototype,可以这样配置:
<bean id="account" class="com.foo.DefaultAccount" scope="prototype"/>
或者
<bean id="account" class="com.foo.DefaultAccount" singleton="false"/>(3)当一个bean的作用域为Request,表示在一次HTTP请求中,一个bean定义对应一个实例;即每个HTTP请求都会有各自的bean实例,它们依据某个bean定义创建而成。该作用域仅在基于web的Spring ApplicationContext情形下有效。考虑下面bean定义:
<bean id="loginAction" class=cn.csdn.LoginAction" scope="request"/>针对每次HTTP请求,Spring容器会根据loginAction bean的定义创建一个全新的LoginAction bean实例,且该loginAction bean实例仅在当前HTTP request内有效,因此可以根据需要放心的更改所建实例的内部状态,而其他请求中根据loginAction bean定义创建的实例,将不会看到这些特定于某个请求的状态变化。当处理请求结束,request作用域的bean实例将被销毁。
(4)当一个bean的作用域为Session,表示在一个HTTP Session中,一个bean定义对应一个实例。该作用域仅在基于web的Spring ApplicationContext情形下有效。考虑下面bean定义:
<bean id="userPreferences" class="com.foo.UserPreferences" scope="session"/>针对某个HTTP Session,Spring容器会根据userPreferences bean定义创建一个全新的userPreferences bean实例,且该userPreferences bean仅在当前HTTP Session内有效。与request作用域一样,可以根据需要放心的更改所创建实例的内部状态,而别的HTTP Session中根据userPreferences创建的实例,将不会看到这些特定于某个HTTP Session的状态变化。当HTTP Session最终被废弃的时候,在该HTTP Session作用域内的bean也会被废弃掉。
(5)当一个bean的作用域为Global Session,表示在一个全局的HTTP Session中,一个bean定义对应一个实例。典型情况下,仅在使用portlet context的时候有效。该作用域仅在基于web的Spring ApplicationContext情形下有效。考虑下面bean定义:
<bean id="user" class="com.foo.Preferences "scope="globalSession"/>global session作用域类似于标准的HTTP Session作用域,不过仅仅在基于portlet的web应用中才有意义。Portlet规范定义了全局Session的概念,它被所有构成某个portlet web应用的各种不同的portlet所共享。在global session作用域中定义的bean被限定于全局portlet Session的生命周期范围内。
SpringBean的生命周期
Spring中bean的实例化过程(不好意思,我盗图了):
与上图类似,bean的生命周期流程图:
Bean实例生命周期的执行过程如下:
Spring对bean进行实例化,默认bean是单例;
Spring对bean进行依赖注入;
如果bean实现了BeanNameAware接口,spring将bean的id传给setBeanName()方法;
如果bean实现了BeanFactoryAware接口,spring将调用setBeanFactory方法,将BeanFactory实例传进来;
如果bean实现了ApplicationContextAware接口,它的setApplicationContext()方法将被调用,将应用上下文的引用传入到bean中;
如果bean实现了BeanPostProcessor接口,它的postProcessBeforeInitialization方法将被调用;
如果bean实现了InitializingBean接口,spring将调用它的afterPropertiesSet接口方法,类似的如果bean使用了init-method属性声明了初始化方法,该方法也会被调用;
如果bean实现了BeanPostProcessor接口,它的postProcessAfterInitialization接口方法将被调用;
此时bean已经准备就绪,可以被应用程序使用了,他们将一直驻留在应用上下文中,直到该应用上下文被销毁;
若bean实现了DisposableBean接口,spring将调用它的distroy()接口方法。同样的,如果bean使用了destroy-method属性声明了销毁方法,则该方法被调用;
其实很多时候我们并不会真的去实现上面说描述的那些接口,那么下面我们就除去那些接口,针对bean的单例和非单例来描述下bean的生命周期:
2.1 单例管理的对象
当scope=”singleton”,即默认情况下,会在启动容器时(即实例化容器时)时实例化。但我们可以指定Bean节点的lazy-init=”true”来延迟初始化bean,这时候,只有在第一次获取bean时才会初始化bean,即第一次请求该bean时才初始化。如下配置:
<bean id="ServiceImpl" class="cn.csdn.service.ServiceImpl" lazy-init="true"/> 如果想对所有的默认单例bean都应用延迟初始化,可以在根节点beans设置default-lazy-init属性为true,如下所示:
<beans default-lazy-init="true" …>默认情况下,Spring在读取xml文件的时候,就会创建对象。在创建对象的时候先调用构造器,然后调用init-method属性值中所指定的方法。对象在被销毁的时候,会调用destroy-method属性值中所指定的方法(例如调用Container.destroy()方法的时候)。写一个测试类,代码如下:
public class LifeBean {
private String name;
public LifeBean(){
System.out.println("LifeBean()构造函数");
}
public String getName() {
return name;
}
public void setName(String name) {
System.out.println("setName()");
this.name = name;
}
public void init(){
System.out.println("this is init of lifeBean");
}
public void destory(){
System.out.println("this is destory of lifeBean " + this);
}
}life.xml配置如下:
<bean id="life_singleton" class="com.bean.LifeBean" scope="singleton"
init-method="init" destroy-method="destory" lazy-init="true"/>测试代码如下:
public class LifeTest {
@Test
public void test() {
AbstractApplicationContext container =
new ClassPathXmlApplicationContext("life.xml");
LifeBean life1 = (LifeBean)container.getBean("life");
System.out.println(life1);
container.close();
}
}运行结果如下:
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@573f2bb1
……
this is destory of lifeBean com.bean.LifeBean@573f2bb12.2 非单例管理的对象
当scope=”prototype”时,容器也会延迟初始化bean,Spring读取xml文件的时候,并不会立刻创建对象,而是在第一次请求该bean时才初始化(如调用getBean方法时)。在第一次请求每一个prototype的bean时,Spring容器都会调用其构造器创建这个对象,然后调用init-method属性值中所指定的方法。对象销毁的时候,Spring容器不会帮我们调用任何方法,因为是非单例,这个类型的对象有很多个,Spring容器一旦把这个对象交给你之后,就不再管理这个对象了。
为了测试prototype bean的生命周期life.xml配置如下:
<bean id="life_prototype" class="com.bean.LifeBean" scope="prototype" init-method="init" destroy-method="destory"/>测试程序如下:
public class LifeTest {
@Test
public void test() {
AbstractApplicationContext container = new ClassPathXmlApplicationContext("life.xml");
LifeBean life1 = (LifeBean)container.getBean("life_singleton");
System.out.println(life1);
LifeBean life3 = (LifeBean)container.getBean("life_prototype");
System.out.println(life3);
container.close();
}
}运行结果如下:
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@573f2bb1
LifeBean()构造函数
this is init of lifeBean
com.bean.LifeBean@5ae9a829
……
this is destory of lifeBean com.bean.LifeBean@573f2bb1可以发现,对于作用域为prototype的bean,其destroy方法并没有被调用。如果bean的scope设为prototype时,当容器关闭时,destroy方法不会被调用。对于prototype作用域的bean,有一点非常重要,那就是Spring不能对一个prototype bean的整个生命周期负责:容器在初始化、配置、装饰或者是装配完一个prototype实例后,将它交给客户端,随后就对该prototype实例不闻不问了。不管何种作用域,容器都会调用所有对象的初始化生命周期回调方法。但对prototype而言,任何配置好的析构生命周期回调方法都将不会被调用。清除prototype作用域的对象并释放任何prototype bean所持有的昂贵资源,都是客户端代码的职责(让Spring容器释放被prototype作用域bean占用资源的一种可行方式是,通过使用bean的后置处理器,该处理器持有要被清除的bean的引用)。谈及prototype作用域的bean时,在某些方面你可以将Spring容器的角色看作是Java new操作的替代者,任何迟于该时间点的生命周期事宜都得交由客户端来处理。
Spring容器可以管理singleton作用域下bean的生命周期,在此作用域下,Spring能够精确地知道bean何时被创建,何时初始化完成,以及何时被销毁。而对于prototype作用域的bean,Spring只负责创建,当容器创建了bean的实例后,bean的实例就交给了客户端的代码管理,Spring容器将不再跟踪其生命周期,并且不会管理那些被配置成prototype作用域的bean的生命周期。
2.3 引申
在学习Spring IoC过程中发现,每次产生ApplicationContext工厂的方式是:
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");这样产生ApplicationContext就有一个弊端,每次访问加载bean的时候都会产生这个工厂,所以这里需要解决这个问题。
ApplicationContext是一个接口,它继承自BeanFactory接口,除了包含BeanFactory的所有功能之外,在国际化支持、资源访问(如URL和文件)、事件传播等方面进行了良好的支持。
解决问题的方法很简单,在web容器启动的时候将ApplicationContext转移到ServletContext中,因为在web应用中所有的Servlet都共享一个ServletContext对象。那么我们就可以利用ServletContextListener去监听ServletContext事件,当web应用启动的是时候,我们就将ApplicationContext装载到ServletContext中。 Spring容器底层已经为我们想到了这一点,在spring-web-xxx-release.jar包中有一个已经实现了ServletContextListener接口的类ContextLoader,其源码如下:
public class ContextLoaderListener extends ContextLoader implements ServletContextListener {
private ContextLoader contextLoader;
public ContextLoaderListener() {
}
public ContextLoaderListener(WebApplicationContext context) {
super(context);
}
public void contextInitialized(ServletContextEvent event) {
this.contextLoader = createContextLoader();
if (this.contextLoader == null) {
this.contextLoader = this;
}
this.contextLoader.initWebApplicationContext(event.getServletContext());
}
@Deprecated
protected ContextLoader createContextLoader() {
return null;
}
@Deprecated
public ContextLoader getContextLoader() {
return this.contextLoader;
}
public void contextDestroyed(ServletContextEvent event) {
if (this.contextLoader != null) {
this.contextLoader.closeWebApplicationContext(event.getServletContext());
}
ContextCleanupListener.cleanupAttributes(event.getServletContext());
}
}这里就监听到了servletContext的创建过程, 那么 这个类又是如何将applicationContext装入到serveletContext容器中的呢?
this.contextLoader.initWebApplicationContext(event.getServletContext())方法的具体实现中:
public WebApplicationContext initWebApplicationContext(ServletContext servletContext) {
if (servletContext.getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE) != null) {
throw new IllegalStateException(
"Cannot initialize context because there is already a root application context present - " +
"check whether you have multiple ContextLoader* definitions in your web.xml!");
}
Log logger = LogFactory.getLog(ContextLoader.class);
servletContext.log("Initializing Spring root WebApplicationContext");
if (logger.isInfoEnabled()) {
logger.info("Root WebApplicationContext: initialization started");
}
long startTime = System.currentTimeMillis();
try {
// Store context in local instance variable, to guarantee that
// it is available on ServletContext shutdown.
if (this.context == null) {
this.context = createWebApplicationContext(servletContext);
}
if (this.context instanceof ConfigurableWebApplicationContext) {
ConfigurableWebApplicationContext cwac = (ConfigurableWebApplicationContext) this.context;
if (!cwac.isActive()) {
// The context has not yet been refreshed -> provide services such as
// setting the parent context, setting the application context id, etc
if (cwac.getParent() == null) {
// The context instance was injected without an explicit parent ->
// determine parent for root web application context, if any.
ApplicationContext parent = loadParentContext(servletContext);
cwac.setParent(parent);
}
configureAndRefreshWebApplicationContext(cwac, servletContext);
}
}
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context);
ClassLoader ccl = Thread.currentThread().getContextClassLoader();
if (ccl == ContextLoader.class.getClassLoader()) {
currentContext = this.context;
}
else if (ccl != null) {
currentContextPerThread.put(ccl, this.context);
}
if (logger.isDebugEnabled()) {
logger.debug("Published root WebApplicationContext as ServletContext attribute with name [" +
WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE + "]");
}
if (logger.isInfoEnabled()) {
long elapsedTime = System.currentTimeMillis() - startTime;
logger.info("Root WebApplicationContext: initialization completed in " + elapsedTime + " ms");
}
return this.context;
}
catch (RuntimeException ex) {
logger.error("Context initialization failed", ex);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, ex);
throw ex;
}
catch (Error err) {
logger.error("Context initialization failed", err);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, err);
throw err;
}
}这里的重点是servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context),用key:WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE value: this.context的形式将applicationContext装载到servletContext中了。另外从上面的一些注释我们可以看出: WEB-INF/applicationContext.xml, 如果我们项目中的配置文件不是这么一个路径的话 那么我们使用ContextLoaderListener 就会出问题, 所以我们还需要在web.xml中配置我们的applicationContext.xml配置文件的路径。
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</context-param>剩下的就是在项目中开始使用 servletContext中装载的applicationContext对象了: 那么这里又有一个问题,装载时的key是 WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE,我们在代码中真的要使用这个吗? 其实Spring为我们提供了一个工具类WebApplicationContextUtils,接着我们先看下如何使用,然后再去看下这个工具类的源码:
WebApplicationContext applicationContext = WebApplicationContextUtils.getWebApplicationContext(request.getServletContext());接着来看下这个工具类的源码:
public static WebApplicationContext getWebApplicationContext(ServletContext sc) {
return getWebApplicationContext(sc, WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE);
}这里就能很直观清晰地看到 通过key值直接获取到装载到servletContext中的 applicationContext对象了。
ContextLoaderListener监听器的作用就是启动Web容器时,自动装配ApplicationContext的配置信息,因为它实现了ServletContextListener这个接口,在web.xml配置这个监听器,启动容器时,就会默认执行它实现的方法。在ContextLoaderListener中关联了ContextLoader这个类,整个加载配置过程由ContextLoader来完成。
Spring创建bean和手工创建bean的区别
Spring创建Bean的三种方式:默认无参构造;静态工厂;实例工厂。
三种方式都是创建一个新的实例对象。实例对象都是独立的,没有联系。
从初始化方法可以看出,Spring这三种创建实例的方式都是一样的,在加载配置文件的时候就创建了实例,这三种方式实例加载的时机是一样的。
最根本的区别还是创建方式的不同。
第一种,通过默认的无参构造方式创建,其本质就是把类交给Spring自带的工厂(BeanFactory)管理、由Spring自带的工厂模式帮我们维护和创建这个类。如果是有参的构造方法,也可以通过XML配置传入相应的初始化参数,这种也是开发中用的最多的。
第二种,通过静态工厂创建,其本质就是把类交给我们自己的静态工厂管理,Spring只是帮我们调用了静态工厂创建实例的方法,而创建实例的这个过程是由我们自己的静态工厂实现的,在实际开发的过程中,很多时候我们需要使用到第三方jar包提供给我们的类,而这个类没有构造方法,而是通过第三方包提供的静态工厂创建的,这是时候,如果我们想把第三方jar里面的这个类交由spring来管理的话,就可以使用Spring提供的静态工厂创建实例的配置。
第三种,通过实例工厂创建,其本质就是把创建实例的工厂类交由Spring管理,同时把调用工厂类的方法创建实例的这个过程也交由Spring管理,看创建实例的这个过程也是有我们自己配置的实例工厂内部实现的。在实际开发的过程中,如Spring整合Hibernate就是通过这种方式实现的。但对于没有与Spring整合过的工厂类,我们一般都是自己用代码来管理的。
Spring框架中需要引用哪些jar包,以及这些jar包的用途;
spring.jar是包含完整发布的单个jar包。除了spring.jar文件外还包含13个独立的jar包,各自对应spring不同的组件,在使用时可以根据实际情况选择需要的jar包,不必引入整个spring.jar包中所有的文件
1)spring-core.jar:包含spring框架基本的核心工具类,其他组件都要使用这个包里面的类,是其他组件的核心;
2)spring-bean.jar:是所有的应用都要用到的,包含访问配置文件、创建和管理bean以及进行IoC和DI操作所需的相关类;
3)spring-aop.jar:包含使用AOP特性时所需的类;
4)spring-context.jar:为spring核心提供了大量扩展;
5)spring-dao.jar:包含spring DAO、spring Transaction进行数据访问的所有类;
6)spring-hibernate.jar:包含spring对hibernate 2以及hibernate 3进行封装的所有类;
7)spring-jdbc.jar:包含spring对JDBC数据库访问进行封装的所有类;
8)spring-orm.jar:包含多DAO特性集进行了扩展;
9)spring-remoting.jar:包含支持EJB、JMS、远程调用Remoting方面的类;
10)spring-support.jar:包含支持缓存Cache、JAC、JMX、邮件服务、任务计划Scheduling方面的类;
11)spring-web.jar:包含web开发时,用到spring框架时所需的核心类;
12)spring-webmvc.jar:baohan Spring MVC框架相关的所有类;
13)spring-mock.jar:包含spring一整套mock类来辅助应用的测试。
Spring中循环注入是什么意思,可不可以解决,如何解决;
https://blog.csdn.net/chejinqiang/article/details/80003868
Spring 的单例实现原理
单例模式有饿汉模式、懒汉模式、静态内部类、枚举等方式实现,但由于以上模式的构造方法是私有的,不可继承,Spring为实现单例类可继承,使用的是单例注册表的方式(登记式单例)。
什么是单例注册表呢,
登记式单例实际上维护的是一组单例类的实例,将这些实例存储到一个Map(登记簿)中,对于已经登记过的单例,则从工厂直接返回,对于没有登记的,则先登记,而后返回
1. 使用map实现注册表;
2. 使用protect修饰构造方法;
有的时候,我们不希望在一开始的时候就把一个类写成单例模式,但是在运用的时候,我们却可以像单例一样使用他
最典型的例子就是spring,他的默认类型就是单例,spring是如何做到把不是单例的类变成单例呢?
这就用到了登记式单例
其实登记式单例并没有去改变类,他所做的就是起到一个登记的作用,如果没有登记,他就给你登记,并把生成的实例保存起来,下次你要用的时候直接给你。
IOC容器就是做的这个事,你需要就找他去拿,他就可以很方便的实现Bean的管理。
懒汉式饿汉式这种通过私有化构造函数,静态方法提供实例的单例类而言,是不支持继承的。这种模式的单例实现要求每个具体的单例类自身来维护单例实例和限制多个实例的生成。可以采用另外一种实现单例的思路:登记式单例,来使得单例对继承开放。
懒汉式饿汉式的getInstance()方法都是无参的,返回本类的单例实例。而登记式单例是有参的,根据参数创建不同类的实例加入Map中,根据参数返回不同类的单例实例
我们看一个例子:
Import java.util.HashMap;
Public class RegSingleton{
//使用一个map来当注册表
Static private HashMap registry=new HashMap();
//静态块,在类被加载时自动执行,把RegistSingleton自己也纳入容器管理
Static{
RegSingleton rs=new RegSingleton();
Registry.put(rs.getClass().getName(),rs);
}
//受保护的默认构造函数,如果为继承关系,则可以调用,克服了单例类不能为继承的缺点
Protected RegSingleton(){}
//静态工厂方法,返回此类的唯一实例
public static RegSingleton getInstance(String name){
if(name==null){
name=” RegSingleton”;
}if(registry.get(name)==null){
try{
registry.put(name,Class.forName(name).newInstance());
}Catch(Exception ex){ex.printStackTrace();}
}
Return (RegSingleton)registry.get(name);
}
}受保护的构造函数,不能是私有的,但是这样子类可以直接访问构造方法了
解决方式是把你的单例类放到一个外在的包中,以便在其它包中的类(包括缺省的包)无法实例化一个单例类。
看下spring的源码:
public abstract class AbstractBeanFactory implements ConfigurableBeanFactory{
/**
* 充当了Bean实例的缓存,实现方式和单例注册表相同
*/
private final Map singletonCache=new HashMap();
public Object getBean(String name)throws BeansException{
return getBean(name,null,null);
}
...
public Object getBean(String name,Class requiredType,Object[] args)throws BeansException{
//对传入的Bean name稍做处理,防止传入的Bean name名有非法字符(或则做转码)
String beanName=transformedBeanName(name);
Object bean=null;
//手工检测单例注册表
Object sharedInstance=null;
//使用了代码锁定同步块,原理和同步方法相似,但是这种写法效率更高
synchronized(this.singletonCache){
sharedInstance=this.singletonCache.get(beanName);
}
if(sharedInstance!=null){
...
//返回合适的缓存Bean实例
bean=getObjectForSharedInstance(name,sharedInstance);
}else{
...
//取得Bean的定义
RootBeanDefinition mergedBeanDefinition=getMergedBeanDefinition(beanName,false);
...
//根据Bean定义判断,此判断依据通常来自于组件配置文件的单例属性开关
//<bean id="date" class="java.util.Date" scope="singleton"/>
//如果是单例,做如下处理
if(mergedBeanDefinition.isSingleton()){
synchronized(this.singletonCache){
//再次检测单例注册表
sharedInstance=this.singletonCache.get(beanName);
if(sharedInstance==null){
...
try {
//真正创建Bean实例
sharedInstance=createBean(beanName,mergedBeanDefinition,args);
//向单例注册表注册Bean实例
addSingleton(beanName,sharedInstance);
}catch (Exception ex) {
...
}finally{
...
}
}
}
bean=getObjectForSharedInstance(name,sharedInstance);
}
//如果是非单例,即prototpye,每次都要新创建一个Bean实例
//<bean id="date" class="java.util.Date" scope="prototype"/>
else{
bean=createBean(beanName,mergedBeanDefinition,args);
}
}
...
return bean;
}
}Servlet如何保证单例模式,可不可以编程多例的哪?
是否在分布式环境中部署
是否实现SingleThreadModel,如果实现则最多会创建20个实例
在web.xml中声明了几次,即使同一个Servlet,如果声明多次,也会生成多个实例。
聊下Spring源码?
撤一下DispatcherServlet,IOC,AOP
Spring 的原理?
Spring内部最核心的就是IOC了,动态注入,让一个对象的创建不用new了,可以自动的生产,这其实就是利用java里的反射,反射其实就是在运行时动态的去创建、调用对象,Spring就是在运行时,跟xml Spring的配置文件来动态的创建对象和调用对象里的方法的 。
Spring还有一个核心就是AOP面向切面编程,可以为某一类对象进行监督和控制(也就是在调用这类对象的具体方法的前后去调用你指定的模块)从而达到对一个模块扩充的功能。这些都是通过配置类达到的。
Spring目地就是让对象与对象(模块与模块)之间的关系没有通过代码来关联,都是通过配置类说明管理的
Spring的优点?
优点:
1.方便解耦,简化开发
通过Spring提供的IoC容器,我们可以将对象之间的依赖关系交由Spring进行控制,避免硬编码所造成的过度程序耦合。有了Spring,用户不必再为单实例模式类、属性文件解析等这些很底层的需求编写代码,可以更专注于上层的应用。
2.AOP编程的支持
通过Spring提供的AOP功能,方便进行面向切面的编程,许多不容易用传统OOP实现的功能可以通过AOP轻松应付。
3.声明事物的支持
在Spring中,我们可以从单调烦闷的事务管理代码中解脱出来,通过声明式方式灵活地进行事务的管理,提高开发效率和质量。
4.方便程序的测试
可以用非容器依赖的编程方式进行几乎所有的测试工作,在Spring里,测试不再是昂贵的操作,而是随手可做的事情。例如:Spring对Junit4支持,可以通过注解方便的测试Spring程序。
5.方便集成各种优秀框架
Spring不排斥各种优秀的开源框架,相反,Spring可以降低各种框架的使用难度,Spring提供了对各种优秀框架(如Struts,Hibernate、Hessian、Quartz)等的直接支持。
6.降低Java EE API的使用难度
Spring对很多难用的Java EE API(如JDBC,JavaMail,远程调用等)提供了一个薄薄的封装层,通过Spring的简易封装,这些Java EE API的使用难度大为降低。
7.Java 源码是经典学习范例
Spring的源码设计精妙、结构清晰、匠心独用,处处体现着大师对Java设计模式灵活运用以及对Java技术的高深造诣。Spring框架源码无疑是Java技术的最佳实践范例。如果想在短时间内迅速提高自己的Java技术水平和应用开发水平,学习和研究Spring源码将会使你收到意想不到的效果。
低侵入式设计,代码污染极低,Spring并不强制应用完全依赖于Spring,开发者可自由选用Spring框架的部分或全部
缺点:
对比新出的springboot,肯定没人家好用
spring像一个胶水,将框架黏在一起,后面拆分的话就不容易拆分了
Spring如何实现解耦合?
Spring IOC 容器 通过反射拿到对象的实例,使类的功能更加单一化,减少了类与类的依赖关系
IOC核心?
由 Spring IOC 容器来负责对象的生命周期和对象之间的关系
Spring 的IOC是什么?为了解决什么问题?优点是什么?
控制反转,依赖倒置原则
DI和IOC其实是一个思想,她们的的好处是:如果依赖的类修改了,比如修改了构造函数,如果没有依赖注入,则需要修改依赖对象调用着,如果依赖注入则不需要。
spring IOC的好处是,对象的构建如果依赖非常多的对象,且层次很深,外层在构造对象时很麻烦且不一定知道如何构建这么多层次的对象。 IOC 帮我们管理对象的创建,只需要在配置文件里指定如何构建,每一个对象的配置文件都在类编写的时候指定了,所以最外层对象不需要关心深层次对象如何创建的,前人都写好了。
IOC三种注入方式?
构造器,setter(灵活),接口(侵略性,实现不必要的接口),基于注解
autowire主要有三个属性值:constructor,byName,byType。
constructor:通过构造方法进行自动注入,spring会匹配与构造方法参数类型一致的bean进行注入,如果有一个多参数的构造方法,一个只有一个参数的构造方法,在容器中查找到多个匹配多参数构造方法的bean,那么spring会优先将bean注入到多参数的构造方法中。
byName:被注入bean的id名必须与set方法后半截匹配,并且id名称的第一个单词首字母必须小写,这一点与手动set注入有点不同。
byType:查找所有的set方法,将符合符合参数类型的bean注入。
下面进入正题:注解方式注册bean,注入依赖
主要有四种注解可以注册bean,每种注解可以任意使用,只是语义上有所差异:
@Component:可以用于注册所有bean
@Repository:主要用于注册dao层的bean
@Controller:主要用于注册控制层的bean
@Service:主要用于注册服务层的bean
描述依赖关系主要有两种:
@Resource:java的注解,默认以byName的方式去匹配与属性名相同的bean的id,如果没有找到就会以byType的方式查找,如果byType查找到多个的话,使用@Qualifier注解(spring注解)指定某个具体名称的bean。
@Resource
@Qualifier("userDaoMyBatis")
private IUserDao userDao;
public UserService(){
}@Autowired:spring注解,默认是以byType的方式去匹配类型相同的bean,如果只匹配到一个,那么就直接注入该bean,无论要注入的 bean 的 name 是什么;如果匹配到多个,就会调用 DefaultListableBeanFactory 的 determineAutowireCandidate 方法来决定具体注入哪个bean。determineAutowireCandidate 方法的内容如下:
determineAutowireCandidate 方法的逻辑是:
先找 Bean 上有@Primary 注解的,有则直接返回 bean 的 name。
再找 Bean 上有 @Order,@PriorityOrder 注解的,有则返回 bean 的 name。
最后再以名称匹配(ByName)的方式去查找相匹配的 bean。
可以简单的理解为先以 ByType 的方式去匹配,如果匹配到了多个再以 ByName 的方式去匹配,找到了对应的 bean 就去注入,没找到就抛出异常。
还有一点要注意:如果使用了 @Qualifier 注解,那么当自动装配匹配到多个 bean 的时候就不会进入 determineAutowireCandidate 方法(亲测),而是直接查找与 @Qualifer 指定的 bean name 相同的 bean 去注入,找到了就直接注入,没有找到则抛出异常。
tips:大家如果认真思考可能会发现 ByName 的注入方式和 @Qualifier 有点类似,都是在自动装配匹配到多个 bean 的时候,指定一个具体的 bean,那它们有什么不同呢?
ByName 的方式需要遍历,@Qualifier 直接一次定位。在匹配到多个 bean 的情况下,使用 @Qualifier 来指明具体装配的 bean 效率会更高一下。
个人觉得:@Qualifer 注解出现的意义或许就是 Spring 为了解决 JDK 自带的 ByName 遍历匹配效率低下的问题。要不然也不会出现两个容易混淆的匹配方式。
byName就是通过Bean的id或者name,byType就是按Bean的Class的类型
Spring IOC的具体优势,和直接New一个对象有什么区别;
spring实现了对象池,一些对象创建和使用完毕之后不会被销毁,放进对象池(某种集合)以备下次使用,下次再需要这个对象,不new,直接从池里出去来用。节省时间,节省cpu。
Spring IOC 如何实现,原理
spring就是通过反射来实现注入
IOC初始化流程(Resource 定位、BeanDefinition 的载入和解析,BeanDefinition 注册)》IOC的Bean加载流程
Resource体系
Resource,对资源的抽象,它的每一个实现类都代表了一种资源的访问策略,如ClasspathResource 、 URLResource ,FileSystemResource 等。Spring 利用 ResourceLoader 来进行统一资源加载
BeanFactory?
BeanFactory 是一个非常纯粹的 bean 容器,它是 IOC 必备的数据结构,其中 BeanDefinition 是她的基本结构,它内部维护着一个 BeanDefinition map ,并可根据 BeanDefinition 的描述进行 bean 的创建和管理。
BeanFacoty (接口)有三个直接子类 (接口)ListableBeanFactory、HierarchicalBeanFactory 和 AutowireCapableBeanFactory,DefaultListableBeanFactory类 为最终默认实现,它实现了所有接口。
BeanFactory提供的方法及其简单,仅提供了六种方法供客户调用:
boolean containsBean(String beanName) 判断工厂中是否包含给定名称的bean定义,若有则返回true
Object getBean(String) 返回给定名称注册的bean实例。根据bean的配置情况,如果是singleton模式将返回一个共享实例,否则将返回一个新建的实例,如果没有找到指定bean,该方法可能会抛出异常
Object getBean(String, Class) 返回以给定名称注册的bean实例,并转换为给定class类型
Class getType(String name) 返回给定名称的bean的Class,如果没有找到指定的bean实例,则排除NoSuchBeanDefinitionException异常
boolean isSingleton(String) 判断给定名称的bean定义是否为单例模式
String[] getAliases(String name) 返回给定bean名称的所有别名
ApplicationContext体系?
这个就是大名鼎鼎的 Spring 容器,它叫做应用上下文,与我们应用息息相关,她继承 BeanFactory,所以它是 BeanFactory 的扩展升级版,如果BeanFactory 是屌丝的话,那么 ApplicationContext 则是名副其实的高富帅。由于 ApplicationContext 的结构就决定了它与 BeanFactory 的不同,其主要区别有:
继承 MessageSource,提供国际化的标准访问策略。
继承 ApplicationEventPublisher ,提供强大的事件机制。
扩展 ResourceLoader,可以用来加载多个 Resource,可以灵活访问不同的资源。
对 Web 应用的支持。
BeanFactory 和 ApplicationContext 有什么区别
FactoryBean?
https://www.cnblogs.com/aspirant/p/9082858.html
IOC初始化流程
IOC 容器的初始化过程分为三步骤:Resource 定位、BeanDefinition 的载入和解析,BeanDefinition 注册

IOC资源定义,加载过程?
- Spring 提供了 Resource 和 ResourceLoader 来统一抽象整个资源及其定位。使得资源与资源的定位有了一个更加清晰的界限,并且提供了合适的 Default 类,使得自定义实现更加方便和清晰。
- DefaultResource 为 Resource 的默认实现,它对 Resource 接口做了一个统一的实现,子类继承该类后只需要覆盖相应的方法即可,同时对于自定义的 Resource 我们也是继承该类。
- DefaultResourceLoader 同样也是 ResourceLoader 的默认实现,在自定 ResourceLoader 的时候我们除了可以继承该类外还可以实现 ProtocolResolver 接口来实现自定资源加载协议。
- DefaultResourceLoader 每次只能返回单一的资源,所以 Spring 针对这个提供了另外一个接口 ResourcePatternResolver ,该接口提供了根据指定的 locationPattern 返回多个资源的策略。其子类 PathMatchingResourcePatternResolver 是一个集大成者的 ResourceLoader ,因为它即实现了 Resource getResource(String location) 也实现了 Resource[] getResources(String locationPattern)。
IOC装载核心逻辑?
核心逻辑方法 doLoadBeanDefinitions()中主要是做三件事情。
调用 getValidationModeForResource() 获取 xml 文件的验证模式(DTD或者XSD)
调用 loadDocument() 根据 xml 文件获取相应的 Document 实例。
调用 registerBeanDefinitions() 注册 Bean 实例。
获得Document实例后进行import,bean等标签及标签的属性进行解析,构造BeanDefinition对象
扩展 Spring 自定义标签配置一般需要以下几个步骤:
创建一个需要扩展的组件
定义一个 XSD 文件,用于描述组件内容
创建一个实现 AbstractSingleBeanDefinitionParser 接口的类,用来解析 XSD 文件中的定义和组件定义
创建一个 Handler,继承 NamespaceHandlerSupport ,用于将组件注册到 Spring 容器
编写 Spring.handlers 和 Spring.schemas 文件
自定义标签的解析过程。
其实整个过程还是较为简单:首先会加载 handlers 文件,将其中内容进行一个解析,形成 <namespaceUri,类路径> 这样的一个映射,然后根据获取的 namespaceUri 就可以得到相应的类路径,对其进行初始化等到相应的 Handler 对象,调用 parse() 方法,在该方法中根据标签的 localName 得到相应的 BeanDefinitionParser 实例对象,调用 parse() ,该方法定义在 AbstractBeanDefinitionParser 抽象类中,核心逻辑封装在其 parseInternal() 中,该方法返回一个 AbstractBeanDefinition 实例对象,其主要是在 AbstractSingleBeanDefinitionParser 中实现,对于自定义的 Parser 类,其需要实现 getBeanClass() 或者 getBeanClassName() 和 doParse()。
解析工作分为三步:1、解析默认标签;2、解析默认标签后下得自定义标签;3、注册解析后的 BeanDefinition。经过前面两个步骤的解析,这时的 BeanDefinition 已经可以满足后续的使用要求了,那么接下来的工作就是将这些 BeanDefinition 进行注册,也就是完成第三步。
BeanDefinition 解析过程?
首先通过 beanName 注册 BeanDefinition ,然后再注册别名 alias。BeanDefinition 的注册由接口 BeanDefinitionRegistry 定义。
处理过程如下:
首先 BeanDefinition 进行校验,该校验也是注册过程中的最后一次校验了,主要是对 AbstractBeanDefinition 的 methodOverrides 属性进行校验
根据 beanName 从缓存中获取 BeanDefinition,如果缓存中存在,则根据 allowBeanDefinitionOverriding 标志来判断是否允许覆盖,如果允许则直接覆盖,否则抛出 BeanDefinitionStoreException 异常
若缓存中没有指定 beanName 的 BeanDefinition,则判断当前阶段是否已经开始了 Bean 的创建阶段(),如果是,则需要对 beanDefinitionMap 进行加锁控制并发问题,否则直接设置即可。对于 hasBeanCreationStarted() 方法后续做详细介绍,这里不过多阐述。
若缓存中存在该 beanName 或者 单利 bean 集合中存在该 beanName,则调用 resetBeanDefinition() 重置 BeanDefinition 缓存。
其实整段代码的核心就在于 this.beanDefinitionMap.put(beanName, beanDefinition); 。BeanDefinition 的缓存也不是神奇的东西,就是定义 map ,key 为 beanName,value 为 BeanDefinition。注册 alias 和注册 BeanDefinition 的过程差不多
IOC的Bean加载流程
Spring加载Bean总结:http://cmsblogs.com/?p=2905
加载 bean 阶段:经过容器初始化阶段后,应用程序中定义的 bean 信息已经全部加载到系统中了,当我们显示或者隐式地调用 getBean() 时,则会触发加载 bean 阶段。在这阶段,容器会首先检查所请求的对象是否已经初始化完成了,如果没有,则会根据注册的 bean 信息实例化请求的对象,并为其注册依赖,然后将其返回给请求方。至此第二个阶段也已经完成。
内部调用 doGetBean() 方法,其接受四个参数:
name:要获取 bean 的名字
requiredType:要获取 bean 的类型
args:创建 bean 时传递的参数。这个参数仅限于创建 bean 时使用
typeCheckOnly:是否为类型检查
代码超级长:
1.获取 beanName
final String beanName = transformedBeanName(name);
这里传递的是 name,不一定就是 beanName,可能是 aliasName,也有可能是 FactoryBean,所以这里需要调用 transformedBeanName() 方法对 name 进行一番转换。
主要处理过程包括两步:
去除 FactoryBean 的修饰符。如果 name 以 “&” 为前缀,那么会去掉该 “&”,例如,name = "&studentService",则会是 name = "studentService"。
取指定的 alias 所表示的最终 beanName。主要是一个循环获取 beanName 的过程,例如别名 A 指向名称为 B 的 bean 则返回 B,若 别名 A 指向别名 B,别名 B 指向名称为 C 的 bean,则返回 C。
2.从单例 bean 缓存中获取 bean
单例模式的 bean 在整个过程中只会被创建一次,第一次创建后会将该 bean 加载到缓存中,后面在获取 bean 就会直接从单例缓存中获取。如果从缓存中得到了 bean,则需要调用 getObjectForBeanInstance() 对 bean 进行实例化处理,因为缓存中记录的是最原始的 bean 状态,我们得到的不一定是我们最终想要的 bean。
从单例缓存中获取Bean:
首先从 singletonObjects 中获取,若为空且当前 bean 正在创建中,则从 earlySingletonObjects 中获取,若为空且允许提前创建则从 singletonFactories 中获取相应的 ObjectFactory ,若不为空,则调用其 getObject() 创建 bean,然后将其加入到 earlySingletonObjects,然后从 singletonFactories 删除。总体逻辑就是根据 beanName 依次检测这三个 Map,若为空,从下一个,否则返回。这三个 Map 存放的都有各自的功能,如下:
singletonObjects :存放的是单例 bean,对应关系为 bean name --> bean instance
earlySingletonObjects:存放的是早期的 bean,对应关系也是 bean name --> bean instance。它与 singletonObjects 区别在于 earlySingletonObjects 中存放的 bean 不一定是完整的,从上面过程中我们可以了解,bean 在创建过程中就已经加入到 earlySingletonObjects 中了,所以当在 bean 的创建过程中就可以通过 getBean() 方法获取。这个 Map 也是解决循环依赖的关键所在。
singletonFactories:存放的是 ObjectFactory,可以理解为创建单例 bean 的 factory,对应关系是 bean name --> ObjectFactory
从缓存中获取的 bean 是最原始的 bean 并不一定使我们最终想要的 bean,调用 getObjectForBeanInstance() 进行处理,该方法的定义为获取给定 bean 实例的对象,该对象要么是 bean 实例本身,要么就是 FactoryBean 创建的对象。
getObjectForBeanInstance() 主要是返回给定的 bean 实例对象,当然该实例对象为非 FactoryBean 类型,对于 FactoryBean 类型的 bean,则是委托 getObjectFromFactoryBean() 从 FactoryBean 获取 bean 实例对象。
主要流程如下:
若为单例且单例 bean 缓存中存在 beanName,则进行后续处理(跳转到下一步),否则则从 FactoryBean 中获取 bean 实例对象,如果接受后置处理,则调用 postProcessObjectFromFactoryBean() 进行后置处理。
首先获取锁(其实我们在前面篇幅中发现了大量的同步锁,锁住的对象都是 this.singletonObjects, 主要是因为在单例模式中必须要保证全局唯一),然后从 factoryBeanObjectCache 缓存中获取实例对象 object,若 object 为空,则调用 doGetObjectFromFactoryBean() 方法从 FactoryBean 获取对象,其实内部就是调用 FactoryBean.getObject()。
如果需要后续处理,则进行进一步处理,步骤如下:
若该 bean 处于创建中(isSingletonCurrentlyInCreation),则返回非处理对象,而不是存储它
调用 beforeSingletonCreation() 进行创建之前的处理。默认实现将该 bean 标志为当前创建的。
调用 postProcessObjectFromFactoryBean() 对从 FactoryBean 获取的 bean 实例对象进行后置处理,默认实现是按照原样直接返回,具体实现是在 AbstractAutowireCapableBeanFactory 中实现的,当然子类也可以重写它,比如应用后置处理
调用 afterSingletonCreation() 进行创建 bean 之后的处理,默认实现是将该 bean 标记为不再在创建中。
最后加入到 FactoryBeans 缓存中。
3.原型模式依赖检查与 parentBeanFactory
Spring 只处理单例模式下得循环依赖,对于原型模式的循环依赖直接抛出异常。主要原因还是在于 Spring 解决循环依赖的策略有关。对于单例模式 Spring 在创建 bean 的时候并不是等 bean 完全创建完成后才会将 bean 添加至缓存中,而是不等 bean 创建完成就会将创建 bean 的 ObjectFactory 提早加入到缓存中,这样一旦下一个 bean 创建的时候需要依赖 bean 时则直接使用 ObjectFactroy。但是原型模式我们知道是没法使用缓存的,所以 Spring 对原型模式的循环依赖处理策略则是不处理。
如果容器缓存中没有相对应的 BeanDefinition 则会尝试从父类工厂(parentBeanFactory)中加载,然后再去递归调用 getBean()。
检测逻辑和单例模式一样,一个“集合”存放着正在创建的 bean,从该集合中进行判断即可,只不过单例模式的“集合”为 Set ,而原型模式的则是 ThreadLocal
委托 parentBeanFactory 的 getBean() 进行处理,只不过在获取之前对 name 进行简单的处理,主要是想获取原始的 beanName ,因为最开始对name处理了,这块再还原。
有依赖 bean 的话,那么在初始化该 bean 时是需要先初始化它所依赖的 bean。
检测。若当前 bean 在创建,则抛出 BeanCurrentlyInCreationException 异常。
如果 beanDefinitionMap 中不存在 beanName 的 BeanDefinition(即在 Spring bean 初始化过程中没有加载),则尝试从 parentBeanFactory 中加载。
判断是否为类型检查。
从 mergedBeanDefinitions 中获取 beanName 对应的 RootBeanDefinition,如果这个 BeanDefinition 是子 Bean 的话,则会合并父类的相关属性。
依赖处理。
3. 依赖处理
整体主要是分为三个部分:
各scope的bean创建:
singleton:Spring默认
getSingleton()方法做了一部分准备和预处理步骤,真正获取单例 bean 的方法其实是由 singletonFactory.getObject() 这部分实现,而 singletonFactory 由回调方法产生。那么这个方法做了哪些准备呢?
再次检查缓存是否已经加载过,如果已经加载了则直接返回,否则开始加载过程。
调用 beforeSingletonCreation() 记录加载单例 bean 之前的加载状态,即前置处理。
调用参数传递的 ObjectFactory 的 getObject() 实例化 bean。
调用 afterSingletonCreation() 进行加载单例后的后置处理。
将结果记录并加入值缓存中,同时删除加载 bean 过程中所记录的一些辅助状态。
加载了单例 bean 后,调用 getObjectForBeanInstance() 从 bean 实例中获取对象。
原型模式prototype:
分析从缓存中获取单例 bean,以及对 bean 的实例中获取对象
如果从单例缓存中获取 bean,Spring 是怎么加载的呢?所以第二部分是分析 bean 加载,以及 bean 的依赖处理
bean 已经加载了,依赖也处理完毕了,第三部分则分析各个作用域的 bean 初始化过程。
直接创建一个新的实例就可以了。过程如下:
其他作用域:
核心流程和原型模式一样,只不过获取 bean 实例是由 scope.get() 实现.
调用 beforeSingletonCreation() 记录加载原型模式 bean 之前的加载状态,即前置处理。
调用 createBean() 创建一个 bean 实例对象。
调用 afterSingletonCreation() 进行加载原型模式 bean 后的后置处理。
调用 getObjectForBeanInstance() 从 bean 实例中获取对象。
说说 Spring AOP、Spring AOP 实现原理,使用场景?
https://blog.csdn.net/w372426096/article/details/84824718
https://javadoop.com/post/spring-aop-intro
https://javadoop.com/post/spring-aop-source
AOP应用场景?
Authentication 权限
Caching 缓存
Context passing 内容传递
Error handling 错误处理
Lazy loading 懒加载
Debugging 调试
logging, tracing, profiling and monitoring 记录跟踪 优化 校准
Performance optimization 性能优化
Persistence 持久化
Resource pooling 资源池
Synchronization 同步
Transactions 事务
过滤器和拦截器本质区别
https://www.cnblogs.com/junzi2099/p/8022058.html
https://www.cnblogs.com/somelog/p/9293283.html
转发与重定向的区别
https://blog.csdn.net/liubin5620/article/details/79922692
如何自定义注解实现功能
Spring中@Autowired和@Resource注解的区别?以及他们的解析过程;
https://blog.csdn.net/w372426096/article/details/78315153
如果一个接⼝有2个不同的实现, 那么怎么来Autowire一个指定的实现?
可以使用Qualifier注解限定要注入的Bean,也可以使用Qualifier和Autowire注解指定要获取的bean,也可以使用Resource注解的name属性指定要获取的Bean
Spring 框架中用到了哪些设计模式
第一种:简单工厂
简单工厂模式的实质是由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean对象,但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。
第二种:工厂方法(Factory Method)
通常由应用程序直接使用new创建新的对象,为了将对象的创建和使用相分离,采用工厂模式,即应用程序将对象的创建及初始化职责交给工厂对象。
一般情况下,应用程序有自己的工厂对象来创建bean.如果将应用程序自己的工厂对象交给Spring管理,那么Spring管理的就不是普通的bean,而是工厂Bean。
第三种:单例模式(Singleton)
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
spring中的单例模式完成了后半句话,即提供了全局的访问点BeanFactory。但没有从构造器级别去控制单例,这是因为spring管理的是是任意的java对象。
核心提示点:Spring下默认的bean均为singleton,可以通过singleton=“true|false” 或者 scope=“?”来指定
第四种:适配器(Adapter)
在Spring的Aop中,使用的Advice(通知)来增强被代理类的功能。Spring实现这一AOP功能的原理就使用代理模式(1、JDK动态代理。2、CGLib字节码生成技术代理。)对类进行方法级别的切面增强,即,生成被代理类的代理类, 并在代理类的方法前,设置拦截器,通过执行拦截器重的内容增强了代理方法的功能,实现的面向切面编程。
第五种:包装器(Decorator)
首先想到在spring的applicationContext中配置所有的dataSource。这些dataSource可能是各种不同类型的,比如不同的数据库:Oracle、SQL Server、MySQL等,也可能是不同的数据源:比如apache 提供的org.apache.commons.dbcp.BasicDataSource、spring提供的org.springframework.jndi.JndiObjectFactoryBean等。然后sessionFactory根据客户的每次请求,将dataSource属性设置成不同的数据源,以到达切换数据源的目的。
spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有Decorator。基本上都是动态地给一个对象添加一些额外的职责。
第六种:代理(Proxy)
为其他对象提供一种代理以控制对这个对象的访问。 从结构上来看和Decorator模式类似,但Proxy是控制,更像是一种对功能的限制,而Decorator是增加职责。
spring的Proxy模式在aop中有体现,比如JdkDynamicAopProxy和Cglib2AopProxy。
第七种:观察者(Observer)
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
spring中Observer模式常用的地方是listener的实现。如ApplicationListener。
动态代理(CGLib 与 JDK)、优缺点、性能对比、如何选择
https://blog.csdn.net/w372426096/article/details/82659354
从 jdk6 到 jdk7、jdk8 ,动态代理的性能得到了显著的提升,而 cglib 的表现并未跟上,甚至可能会略微下降。传言的 cglib 比 jdk动态代理高出 10 倍的情况也许是出现在更低版本的 jdk 上吧。
Spring框架如何实现事务的;
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。对于纯JDBC操作数据库,想要用到事务,可以按照以下步骤进行:
- 获取连接 Connection con = DriverManager.getConnection()
- 开启事务con.setAutoCommit(true/false);
- 执行CRUD
- 提交事务/回滚事务 con.commit() / con.rollback();
- 关闭连接 conn.close();
使用Spring的事务管理功能后,我们可以不再写步骤 2 和 4 的代码,而是由Spirng 自动完成。 那么Spring是如何在我们书写的 CRUD 之前和之后开启事务和关闭事务的呢?解决这个问题,也就可以从整体上理解Spring的事务管理实现原理了。下面简单地介绍下,注解方式为例子
- 配置文件开启注解驱动,在相关的类和方法上通过注解@Transactional标识。
- spring 在启动的时候会去解析生成相关的bean,这时候会查看拥有相关注解的类和方法,并且为这些类和方法生成代理,并根据@Transaction的相关参数进行相关配置注入,这样就在代理中为我们把相关的事务处理掉了(开启正常提交事务,异常回滚事务)。
- 真正的数据库层的事务提交和回滚是通过binlog或者redo log实现的。
Spring和事务的关系
关系型数据库、某些消息队列等产品或中间件称为事务性资源,因为它们本身支持事务,也能够处理事务。
Spring很显然不是事务性资源,但是它可以管理事务性资源,所以Spring和事务之间是管理关系。
Spring 事务实现方式、
http://www.cnblogs.com/WJ-163/p/6035462.html
事务的传播机制
https://blog.csdn.net/springlovejava/article/details/79722679
事务传播行为种类,类别?
事务的传播及其属性的意义:
//事务传播属性
@Transactional(propagation=Propagation.REQUIRED)//如果有事务,那么加入事务,没有的话新创建一个
@Transactional(propagation=Propagation.NOT_SUPPORTED)//这个方法不开启事务
@Transactional(propagation=Propagation.REQUIREDS_NEW)//不管是否存在事务,都创建一个新的事务,原来的挂起,新的执行完毕,继续执行老的事务
@Transactional(propagation=Propagation.MANDATORY)//必须在一个已有的事务中执行,否则抛出异常
@Transactional(propagation=Propagation.NEVER)//不能在一个事务中执行,就是当前必须没有事务,否则抛出异常
@Transactional(propagation=Propagation.SUPPORTS)//其他bean调用这个方法,如果在其他bean中声明了事务,就是用事务。没有声明,就不用事务。
@Transactional(propagation=Propagation.NESTED)//如果一个活动的事务存在,则运行在一个嵌套的事务中,如果没有活动的事务,则按照REQUIRED属性执行,它使用一个单独的事务。这个书屋拥有多个回滚的保存点,内部事务的回滚不会对外部事务造成影响,它只对DataSource TransactionManager事务管理器起效。
@Transactional(propagation=Propagation.REQUIRED,readOnly=true)//只读,不能更新,删除
@Transactional(propagation=Propagation.REQUIRED,timeout=30)//超时30秒
@Transactional(propagation=Propagation.REQUIRED,isolation=Isolation.DEFAULT)//数据库隔离级别
Spring在TransactionDefinition接口中规定了7种类型的事务传播行为,
它们规定了事务方法和事务方法发生嵌套调用时事务如何进行传播:
说明
PROPAGATION_REQUIRED
如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。
PROPAGATION_SUPPORTS
支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY
使用当前的事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW
新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED
以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER
以非事务方式执行,如果当前存在事务,则抛出异常。
PROPAGATION_NESTED
如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
事务隔离级别;
1. TransactionDefinition.ISOLATION_DEFAULT:这是默认值,表示使用底层数据库的默认隔离级别。对大部分数据库而言,通常这值就是
2. TransactionDefinition.ISOLATION_READ_COMMITTED。
TransactionDefinition.ISOLATION_READ_UNCOMMITTED:该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读,不可重复读和幻读,因此很少使用该隔离级别。比如PostgreSQL实际上并没有此级别。
3.TransactionDefinition.ISOLATION_READ_COMMITTED:该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。
TransactionDefinition.ISOLATION_REPEATABLE_READ:该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。该级别可以防止脏读和不可重复读。
4.TransactionDefinition.ISOLATION_SERIALIZABLE:所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
Spring 事务底层原理
1、Spring中事务处理的作用:
Spring事务处理,是将事务处理的工作统一起来,并为事务处理提供通用的支持。
2、工作原理及实现
a、划分处理单元——IOC
由于spring解决的问题是对单个数据库进行局部事务处理的,具体的实现首相用spring中的IOC划分了事务处理单元。并且将对事务的各种配置放到了ioc容器中(设置事务管理器,设置事务的传播特性及隔离机制)。
b、AOP拦截需要进行事务处理的类
Spring事务处理模块是通过AOP功能来实现声明式事务处理的,具体操作(比如事务实行的配置和读取,事务对象的抽象),用TransactionProxyFactoryBean接口来使用AOP功能,生成proxy代理对象,通过TransactionInterceptor完成对代理方法的拦截,将事务处理的功能编织到拦截的方法中。
读取ioc容器事务配置属性,转化为spring事务处理需要的内部数据结构(TransactionAttributeSourceAdvisor),转化为TransactionAttribute表示的数据对象。
c、对事物处理实现(事务的生成、提交、回滚、挂起)
spring委托给具体的事务处理器实现。实现了一个抽象和适配。适配的具体事务处理器:DataSource数据源支持、hibernate数据源事务处理支持、JDO数据源事务处理支持,JPA、JTA数据源事务处理支持。这些支持都是通过设计PlatformTransactionManager、AbstractPlatforTransaction一系列事务处理的支持。
为常用数据源支持提供了一系列的TransactionManager。
d、结合
PlatformTransactionManager实现了TransactionInterception接口,让其与TransactionProxyFactoryBean结合起来,形成一个Spring声明式事务处理的设计体系。
3、应用场景
支持不同数据源,在底层进行封装,可以做到事务即开即用,这样的好处是:即使有其他的数据源事务处理需要,Spring也提供了一种一致的方式。
Spring事务失效(事务嵌套),JDK动态代理给Spring事务埋下的坑
Spring的声明式事务 @Transaction注解⼀般写在什么位置? 抛出了异常会⾃动回滚吗?有没有办法控制不触发回滚?
一般情况下我们在处理具体的业务都是在Service层来进行处理操作,此时如果在Service类上添加@Transactional注解的话,那么Service曾的每一个业务方法调用的时候都会打开一个事务。
注意点: Spring默认情况下会对(RuntimeException)及其子类来进行回滚,在遇见Exception及其子类的时候则不会进行回滚操作。
@Transactional既可以作用于接口,接口方法上以及类已经类的方法上。但是Spring官方不建议接口或者接口方法上使用该注解,因为这只有在使用基于接口的代理时它才会生效。另外, @Transactional 注解应该只被应用到 public 方法上,这是由 Spring AOP 的本质决定的。如果你在 protected、private 或者默认可见性的方法上使用 @Transactional 注解,这将被忽略,也不会抛出任何异常。 Spring默认使用的是jdk自带的基于接口的代理,而没有使用基于类的代理CGLIB。
@Transactional注解底层使用的是动态代理来进行实现的,如果在调用本类中的方法,此时不添加@Transactional注解,而是在调用类中使用thisi调用本类中的另外一个添加了@Transactional注解,此时this调用的方法上的@Transactional注解是不起作用的。
详细解释及解决方案:https://jinnianshilongnian.iteye.com/blog/1487235


1. 让Exception异常也进行回滚操作,在调用该方法前加上: @Transactional(rollbackFor = Exception.class)
2. 让RuntimeException不进行回滚操作,在调用该方法前加上: @Transactional(rollbackFor = RuntimeException.class)
1. 在整个方法运行前就不会开启事务: @Transactional(propagation=Propagation.NOT_SUPPORTED,readOnly=true),这样就做成一个只读事务,可以提高效率
属性 类型 描述
value String 可选的限定描述符,指定使用的事务管理器
propagation enum: Propagation 可选的事务传播行为设置
isolation enum: Isolation 可选的事务隔离级别设置
readOnly boolean 读写或只读事务,默认读写
timeout int (in seconds granularity) 事务超时时间设置
rollbackFor Class对象数组,必须继承自Throwable 导致事务回滚的异常类数组
rollbackForClassName 类名数组,必须继承自Throwable 导致事务回滚的异常类名字数组
oRollbackFor Class对象数组,必须继承自Throwable 不会导致事务回滚的异常类数组
noRollbackForClassName 类名数组,必须继承自Throwable 不会导致事务回滚的异常类名字数组
查看方法的是否事务已经被执行
TransactionSynchronizationManager.isActualTransactionActive() 返回true: 该方法中存在事务,false则不存在
Spring事务三要素
数据源:表示具体的事务性资源,是事务的真正处理者,如MySQL等。
事务管理器:像一个大管家,从整体上管理事务的处理过程,如打开、提交、回滚等。
事务应用和属性配置:像一个标识符,表明哪些方法要参与事务,如何参与事务,以及一些相关属性如隔离级别、超时时间等。
Spring事务的注解配置
把一个DataSource(如DruidDataSource)作为一个@Bean注册到Spring容器中,配置好事务性资源。
把一个@EnableTransactionManagement注解放到一个@Configuration类上,配置好事务管理器,并启用事务管理。
把一个@Transactional注解放到类上或方法上,可以设置注解的属性,表明该方法按配置好的属性参与到事务中。
事务注解的本质
@Transactional这个注解仅仅是一些(和事务相关的)元数据,在运行时被事务基础设施读取消费,并使用这些元数据来配置bean的事务行为。
大致来说具有两方面功能,一是表明该方法要参与事务,二是配置相关属性来定制事务的参与方式和运行行为。
Spring声明式事务实现原理
声明式事务成为可能,主要得益于Spring AOP。使用一个事务拦截器,在方法调用的前后/周围进行事务性增强(advice),来驱动事务完成。
如何回滚一个事务
就是在一个事务上下文中当前正在执行的代码里抛出一个异常,事务基础设施代码会捕获任何未处理的异常,并且做出决定是否标记这个事务为回滚。
默认回滚规则
默认只把runtime, unchecked exceptions标记为回滚,即RuntimeException及其子类,Error默认也导致回滚。Checked exceptions默认不导致回滚。这些规则和EJB是一样的。
如何配置回滚异常
使用@Transactional注解的rollbackFor/rollbackForClassName属性,可以精确配置导致回滚的异常类型,包括checked exceptions。
noRollbackFor/noRollbackForClassName属性,可以配置不导致回滚的异常类型,当遇到这样的未处理异常时,照样提交相关事务。
事务注解在类/方法上
@Transactional注解既可以标注在类上,也可以标注在方法上。当在类上时,默认应用到类里的所有方法。如果此时方法上也标注了,则方法上的优先级高。
事务注解在类上的继承性
@Transactional注解的作用可以传播到子类,即如果父类标了子类就不用标了。但倒过来就不行了。
子类标了,并不会传到父类,所以父类方法不会有事务。父类方法需要在子类中重新声明而参与到子类上的注解,这样才会有事务。
事务注解在接口/类上
@Transactional注解可以用在接口上,也可以在类上。在接口上时,必须使用基于接口的代理才行,即JDK动态代理。
事实是Java的注解不能从接口继承,如果你使用基于类的代理,即CGLIB,或基于织入方面,即AspectJ,事务设置不会被代理和织入基础设施认出来,目标对象不会被包装到一个事务代理中。
Spring团队建议注解标注在类上而非接口上。
只在public方法上生效?
当采用代理来实现事务时,(注意是代理),@Transactional注解只能应用在public方法上。当标记在protected、private、package-visible方法上时,不会产生错误,但也不会表现出为它指定的事务配置。可以认为它作为一个普通的方法参与到一个public方法的事务中。
如果想在非public方法上生效,考虑使用AspectJ(织入方式)。
目标类里的自我调用没有事务?
在代理模式中(这是默认的),只有从外部的方法调用进入通过代理会被拦截,这意味着自我调用(实际就是,目标对象中的一个方法调用目标对象的另一个方法)在运行时不会导致一个实际的事务,即使被调用的方法标有注解。
如果你希望自我调用也使用事务来包装,考虑使用AspectJ的方式。在这种情况下,首先是没有代理。相反,目标类被织入(即它的字节码被修改)来把@Transactional加入到运行时行为,在任何种类的方法上都可以。
事务与线程
和JavaEE事务上下文一样,Spring事务和一个线程的执行相关联,底层是一个ThreadLocal<Map<Object, Object>>,就是每个线程一个map,key是DataSource,value是Connection。
逻辑事务与物理事务
事务性资源实际打开的事务就是物理事务,如数据库的Connection打开的事务。Spring会为每个@Transactional方法创建一个事务范围,可以理解为是逻辑事务。
在逻辑事务中,大范围的事务称为外围事务,小范围的事务称为内部事务,外围事务可以包含内部事务,但在逻辑上是互相独立的。每一个这样的逻辑事务范围,都能够单独地决定rollback-only状态。
那么如何处理逻辑事务和物理事务之间的关联关系呢,这就是传播特性解决的问题。
事务的隔离级别
DEFAULT,READ_UNCOMMITTED,READ_COMMITTED,REPEATABLE_READ,SERIALIZABLE
脏读
一个事务修改了一行数据但没有提交,第二个事务可以读取到这行被修改的数据,如果第一个事务回滚,第二个事务获取到的数据将是无效的。
不可重复读
一个事务读取了一行数据,第二个事务修改了这行数据,第一个事务重新读取这行数据,将获得到不同的值。
幻读
一个事务按照一个where条件读取所有符合的数据行,第二个事务插入了一行数据且恰好也满足这个where条件,第一个事务再以这个where条件重新读取,将会获取额外多出来的这一行。
帮助记忆:
写读是脏读,读写读是不可重复读,where insert where是幻读。
DEFAULT
使用底层数据存储的默认隔离级别。MySQL的默认隔离级别是REPEATABLE-READ。
READ_UNCOMMITTED
读未提交。脏读、不可重复读、幻读都会发生。
READ_COMMITTED
读已提交。脏读不会发生,不可重复读、幻读都会发生。
REPEATABLE_READ
可重复读。脏读、不可重复读都不会发生,幻读会发生。
SERIALIZABLE
可串行化。脏读、不可重复读、幻读都不会发生。
Servlet的生命周期
Servlet运行原理

Servlet生命周期定义了一个Servlet如何被加载、初始化,以及它怎样接收请求、响应请求,提供服务。在讨论Servlet生命周期之前,先让我们来看一下这几个方法:
1. init()方法
在Servlet的生命周期中,仅执行一次init()方法,它是在服务器装入Servlet时执行的,可以配置服务器,以在启动服务器或客户机首次访问Servlet时装入Servlet。无论有多少客户机访问Servlet,都不会重复执行init();
2. service()方法
它是Servlet的核心,每当一个客户请求一个HttpServlet对象,该对象的Service()方法就要调用,而且传递给这个方法一个“请求”(ServletRequest)对象和一个“响应”(ServletResponse)对象作为参数。在HttpServlet中已存在Service()方法。默认的服务功能是调用与HTTP请求的方法相应的do功能。
3. destroy()方法
仅执行一次,在服务器端停止且卸载Servlet时执行该方法,有点类似于C++的delete方法。一个Servlet在运行service()方法时可能会产生其他的线程,因此需要确认在调用destroy()方法时,这些线程已经终止或完成。
下面来谈谈Servlet的生命周期,Servlet的生命周期是由Servlet容器来控制的,它始于装入Web服务器的内存时,并在终止或重新装入Servlet时结束。这项操作一般是动态执行的。然而,Server通常会提供一个管理的选项,用于在Server启动时强制装载和初始化特定的Servlet。
在代码中,Servlet生命周期由接口javax.servlet.Servlet定义。所有的Java Servlet 必须直接或间接地实现javax.servlet.Servlet接口,这样才能在Servlet Engine上运行。javax.servlet.Servlet接口定义了一些方法,在Servlet 的生命周期中,这些方法会在特定时间按照一定的顺序被调用。
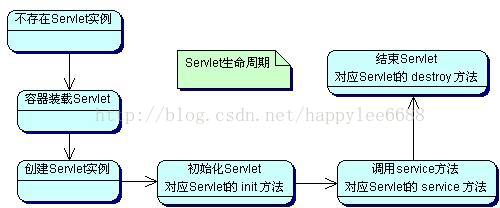
Servlet生命周期
加载和实例化Servlet
我们来看一下Tomcat是如何加载的:
1. 如果已配置自动装入选项,则在启动时自动载入。
2. 在服务器启动时,客户机首次向Servlet发出请求。
3. 重新装入Servlet时。
当启动Servlet容器时,容器首先查找一个配置文件web.xml,这个文件中记录了可以提供服务的Servlet。每个Servlet被指定一个Servlet名,也就是这个Servlet实际对应的Java的完整class文件名。Servlet容器会为每个自动装入选项的Servlet创建一个实例。所以,每个Servlet类必须有一个公共的无参数的构造器。
初始化
当Servlet被实例化后,Servlet容器将调用每个Servlet的init方法来实例化每个实例,执行完init方法之后,Servlet处于“已初始化”状态。所以说,一旦Servlet被实例化,那么必将调用init方法。通过Servlet在启动后不立即初始化,而是收到请求后进行。在web.xml文件中用<load-on-statup> ...... </load-on-statup>对Servlet进行预先初始化。
初始化失败后,执行init()方法抛出ServletException异常,Servlet对象将会被垃圾回收器回收,当客户端第一次访问服务器时加载Servlet实现类,创建对象并执行初始化方法。
请求处理
Servlet 被初始化以后,就处于能响应请求的就绪状态。每个对Servlet 的请求由一个Servlet Request 对象代表。Servlet 给客户端的响应由一个Servlet Response对象代表。对于到达客户机的请求,服务器创建特定于请求的一个“请求”对象和一个“响应”对象。调用service方法,这个方法可以调用其他方法来处理请求。
Service方法会在服务器被访问时调用,Servlet对象的生命周期中service方法可能被多次调用,由于web-server启动后,服务器中公开的部分资源将处于网络中,当网络中的不同主机(客户端)并发访问服务器中的同一资源,服务器将开设多个线程处理不同的请求,多线程同时处理同一对象时,有可能出现数据并发访问的错误。
另外注意,多线程难免同时处理同一变量时(如:对同一文件进行写操作),且有读写操作时,必须考虑是否加上同步,同步添加时,不要添加范围过大,有可能使程序变为纯粹的单线程,大大削弱了系统性能;只需要做到多个线程安全的访问相同的对象就可以了。
卸载Servlet
当服务器不再需要Servlet实例或重新装入时,会调用destroy方法,使用这个方法,Servlet可以释放掉所有在init方法申请的资源。一个Servlet实例一旦终止,就不允许再次被调用,只能等待被卸载。
Servlet一旦终止,Servlet实例即可被垃圾回收,处于“卸载”状态,如果Servlet容器被关闭,Servlet也会被卸载,一个Servlet实例只能初始化一次,但可以创建多个相同的Servlet实例。如相同的Servlet可以在根据不同的配置参数连接不同的数据库时创建多个实例。
Servlet是否单例,为什么是单例;
- Servlet名称相同,映射的URI不同,则Web容器只创建一个Servlet实例。
- Servlet名称和映射的URI都不同,则Web容器分别为这个两个不同的URI创建一个Servlet实例。
是否在分布式环境中部署
是否实现SingleThreadModel,如果实现则最多会创建20个实例
在web.xml中声明了几次,即使同一个Servlet,如果声明多次,也会生成多个实例。
Spring Mvc初始化过程;Spring MVC 启动流程
https://www.cnblogs.com/xiaoxi/p/6164383.html
dispatcherServlet 源码
xml 中配置的 init、destroy 方法怎么可以做到调用具体的方法?
怎么理解Spring MVC Controller线程安全性问题?
spring生成对象默认是单例(也就是一个对象)的。通过scope属性可以更改为多例。
SpringMVC是基于方法的拦截,而Struts2是基于类的拦截。
对于Struts2来说,因为每次处理一个请求,struts就会实例化一个对象;这样就不会有线程安全的问题了;
而Spring的controller默认是Singleton的,这意味着每一个request过来,系统都会用原有的instance去处理,这样导致两个结果:
一是我们不用每次创建Controller,二是减少了对象创建和垃圾收集的时间;由于只有一个Controller的instance,当多个线程调用它的时候,它里面的instance变量就不是线程安全的了,会发生窜数据的问题。
当然大多数情况下,我们根本不需要考虑线程安全的问题,比如dao,service等,除非在bean中声明了实例变量。因此,我们在使用spring mvc 的contrller时,应避免在controller中定义实例变量。
有几种解决方法:
1、在Controller中使用ThreadLocal变量
2、在spring配置文件Controller中声明 scope="prototype",每次都创建新的controller
所以在使用spring开发web 时要注意,默认Controller、Dao、Service都是单例的。
Tomcat本身的参数你⼀般会怎么调整?
JVM相关的
了解哪几种序列化协议?如何选择合适的序列化协议;
https://blog.csdn.net/w372426096/article/details/83503619
SpringBoot:
聊一下架构,接入层架构,服务层架构。聊下技术栈,Spring Boot,Spring Cloud、Docker;
Spring 其他产品(Srping Boot、Spring Cloud、Spring Secuirity、Spring Data、Spring AMQP 等)
有没有用到Spring Boot,Spring Boot的认识、原理
spring boot的启动过程,一个bean xml文件,如何读取,读取以后,是如何创建这个对象的。
Spring Boot比Spring做了哪些改进? Spring 5比Spring4做了哪些改进;
如何自定义一个Spring Boot Starter?
Spring RestTemplate 的具体实现
项目用的是 SpringBoot ,你能说下 Spring Boot 与 Spring 的区别吗?
SpringBoot 的自动配置是怎么做的?
Spring Boot除了自动配置,相比传统的 Spring 有什么其他的区别?
Spring Boot没有放到web容器⾥为什么能跑HTTP服务?
SpringBoot比Spring做了哪些改进?Spring5比Spring4做了哪些改进?(考察技术好奇心,还可以问java9比java8改进了什么?)
如何自定义一个Spring Boot Starter?(考察技术热情,需要描述实现细节)
Spring Cloud 有了解多少?
Mybatis
MyBatis有什么优势;
优点:
1、简单易学
mybatis本身就很小且简单。没有任何第三方依赖,最简单安装只要两个jar文件+配置几个sql映射文件易于学习,易于使用,通过文档和源代码,可以比较完全的掌握它的设计思路和实现。
2、灵活
mybatis不会对应用程序或者数据库的现有设计强加任何影响。 sql写在xml里,便于统一管理和优化。通过sql基本上可以实现我们不使用数据访问框架可以实现的所有功能,或许更多。
3、解除sql与程序代码的耦合
通过提供DAL层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。sql和代码的分离,提高了可维护性。
4、提供映射标签,支持对象与数据库的orm字段关系映射
5、提供对象关系映射标签,支持对象关系组建维护
6、提供xml标签,支持编写动态sql。
缺点:
1、编写SQL语句时工作量很大,尤其是字段多、关联表多时,更是如此。
2、SQL语句依赖于数据库,导致数据库移植性差,不能更换数据库。
3、框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
4、二级缓存机制不佳
MyBatis如何做事务管理;
https://blog.csdn.net/qq924862077/article/details/52599785
MyBatis怎么防止SQL注入;
MyBatis框架作为一款半自动化的持久层框架,其SQL语句都要我们自己手动编写,这个时候当然需要防止SQL注入。其实,MyBatis的SQL是一个具有“输入+输出”的功能,类似于函数的结构,参考上面的两个例子。其中,parameterType表示了输入的参数类型,resultType表示了输出的参数类型。回应上文,如果我们想防止SQL注入,理所当然地要在输入参数上下功夫。上面代码中使用#的即输入参数在SQL中拼接的部分,传入参数后,打印出执行的SQL语句,会看到SQL是这样的:
select id, username, password, role from user where username=? and password=?不管输入什么参数,打印出的SQL都是这样的。这是因为MyBatis启用了预编译功能,在SQL执行前,会先将上面的SQL发送给数据库进行编译;执行时,直接使用编译好的SQL,替换占位符“?”就可以了。因为SQL注入只能对编译过程起作用,所以这样的方式就很好地避免了SQL注入的问题。
【底层实现原理】MyBatis是如何做到SQL预编译的呢?其实在框架底层,是JDBC中的PreparedStatement类在起作用,PreparedStatement是我们很熟悉的Statement的子类,它的对象包含了编译好的SQL语句。这种“准备好”的方式不仅能提高安全性,而且在多次执行同一个SQL时,能够提高效率。原因是SQL已编译好,再次执行时无需再编译。
//安全的,预编译了的
Connection conn = getConn();//获得连接
String sql = "select id, username, password, role from user where id=?"; //执行sql前会预编译号该条语句
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, id);
ResultSet rs=pstmt.executeUpdate();
......//不安全的,没进行预编译
private String getNameByUserId(String userId) {
Connection conn = getConn();//获得连接
String sql = "select id,username,password,role from user where id=" + id;
//当id参数为"3;drop table user;"时,执行的sql语句如下:
//select id,username,password,role from user where id=3; drop table user;
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs=pstmt.executeUpdate();
......
}| #{}:相当于JDBC中的PreparedStatement |
| ${}:是输出变量的值 |
简单说,#{}是经过预编译的,是安全的;${}是未经过预编译的,仅仅是取变量的值,是非安全的,存在SQL注入。
如果我们order by语句后用了${},那么不做任何处理的时候是存在SQL注入危险的。你说怎么防止,那我只能悲惨的告诉你,你得手动处理过滤一下输入的内容。如判断一下输入的参数的长度是否正常(注入语句一般很长),更精确的过滤则可以查询一下输入的参数是否在预期的参数集合中。
MyBatis的原理
https://blog.csdn.net/w372426096/article/details/79932476
我将其工作原理分为六个部分:
-
读取核心配置文件并返回
InputStream流对象。 -
根据
InputStream流对象解析出Configuration对象,然后创建SqlSessionFactory工厂对象 -
根据一系列属性从
SqlSessionFactory工厂中创建SqlSession -
从
SqlSession中调用Executor执行数据库操作&&生成具体SQL指令 -
对执行结果进行二次封装
-
提交与事务
先给大家看看我的实体类:
/**
* 图书实体
*/
public class Book {
private long bookId;// 图书ID
private String name;// 图书名称
private int number;// 馆藏数量
getter and setter ...
}
1. 读取核心配置文件
1.1 配置文件mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://xxx.xxx:3306/ssm" />
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="BookMapper.xml"/>
</mappers>
</configuration>
当然,还有很多可以在XML 文件中进行配置,上面的示例指出的则是最关键的部分。要注意 XML 头部的声明,用来验证 XML 文档正确性。environment 元素体中包含了事务管理和连接池的配置。mappers 元素则是包含一组 mapper 映射器(这些 mapper 的 XML 文件包含了 SQL 代码和映射定义信息)。
1.2 BookMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="Book">
<!-- 目的:为dao接口方法提供sql语句配置 -->
<insert id="insert" >
insert into book (name,number) values (#{name},#{number})
</insert>
</mapper>
就是一个普通的mapper.xml文件。
1.3 Main方法
从 XML 文件中构建 SqlSessionFactory 的实例非常简单,建议使用类路径下的资源文件进行配置。但是也可以使用任意的输入流(InputStream)实例,包括字符串形式的文件路径或者 file:// 的 URL 形式的文件路径来配置。
MyBatis 包含一个名叫 Resources 的工具类,它包含一些实用方法,可使从 classpath 或其他位置加载资源文件更加容易。
public class Main {
public static void main(String[] args) throws IOException {
// 创建一个book对象
Book book = new Book();
book.setBookId(1006);
book.setName("Easy Coding");
book.setNumber(110);
// 加载配置文件 并构建SqlSessionFactory对象
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream);
// 从SqlSessionFactory对象中获取 SqlSession对象
SqlSession sqlSession = factory.openSession();
// 执行操作
sqlSession.insert("insert", book);
// 提交操作
sqlSession.commit();
// 关闭SqlSession
sqlSession.close();
}
}
这个代码是根据Mybatis官方提供的一个不使用 XML 构建 SqlSessionFactory的一个Demo改编的。
注意:是官方给的一个
不使用 XML 构建 SqlSessionFactory的例子,那么我们就从这个例子中查找入口来分析。
2. 根据配置文件生成SqlSessionFactory工厂对象
2.1 Resources.getResourceAsStream(resource);源码分析
Resources是mybatis提供的一个加载资源文件的工具类。

我们只看getResourceAsStream方法:
public static InputStream getResourceAsStream(String resource) throws IOException {
return getResourceAsStream((ClassLoader)null, resource);
}
getResourceAsStream调用下面的方法:
public static InputStream getResourceAsStream(ClassLoader loader, String resource) throws IOException {
InputStream in = classLoaderWrapper.getResourceAsStream(resource, loader);
if (in == null) {
throw new IOException("Could not find resource " + resource);
} else {
return in;
}
}
获取到自身的ClassLoader对象,然后交给ClassLoader(lang包下的)来加载:
InputStream getResourceAsStream(String resource, ClassLoader[] classLoader) {
ClassLoader[] arr$ = classLoader;
int len$ = classLoader.length;
for(int i$ = 0; i$ < len$; ++i$) {
ClassLoader cl = arr$[i$];
if (null != cl) {
InputStream returnValue = cl.getResourceAsStream(resource);
if (null == returnValue) {
returnValue = cl.getResourceAsStream("/" + resource);
}
if (null != returnValue) {
return returnValue;
}
}
}
值的注意的是,它返回了一个InputStream对象。
2.2 new SqlSessionFactoryBuilder().build(inputStream);源码分析
public SqlSessionFactoryBuilder() {
}
所以new SqlSessionFactoryBuilder()只是创建一个对象实例,而没有对象返回(建造者模式),对象的返回交给build()方法。
public SqlSessionFactory build(InputStream inputStream) {
return this.build((InputStream)inputStream, (String)null, (Properties)null);
}
这里要传入一个inputStream对象,就是将我们上一步获取到的InputStream对象传入。
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
SqlSessionFactory var5;
try {
// 进行XML配置文件的解析
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
var5 = this.build(parser.parse());
} catch (Exception var14) {
throw ExceptionFactory.wrapException("Error building SqlSession.", var14);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException var13) {
;
}
}
return var5;
}
如何解析的就大概说下,通过Document对象来解析,然后返回InputStream对象,然后交给XMLConfigBuilder构造成org.apache.ibatis.session.Configuration对象,然后交给build()方法构造程SqlSessionFactory:
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
public DefaultSqlSessionFactory(Configuration configuration) {
this.configuration = configuration;
}
3. 创建SqlSession
SqlSession 完全包含了面向数据库执行 SQL 命令所需的所有方法。你可以通过 SqlSession 实例来直接执行已映射的 SQL 语句。
public SqlSession openSession() {
return this.openSessionFromDataSource(this.configuration.getDefaultExecutorType(), (TransactionIsolationLevel)null, false);
}
调用自身的openSessionFromDataSource方法:
-
getDefaultExecutorType()默认是SIMPLE。
-
注意TX等级是 Null, autoCommit是false。
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
DefaultSqlSession var8;
try {
Environment environment = this.configuration.getEnvironment();
// 根据Configuration的Environment属性来创建事务工厂
TransactionFactory transactionFactory = this.getTransactionFactoryFromEnvironment(environment);
// 从事务工厂中创建事务,默认等级为null,autoCommit=false
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 创建执行器
Executor executor = this.configuration.newExecutor(tx, execType);
// 根据执行器创建返回对象 SqlSession
var8 = new DefaultSqlSession(this.configuration, executor, autoCommit);
} catch (Exception var12) {
this.closeTransaction(tx);
throw ExceptionFactory.wrapException("Error opening session. Cause: " + var12, var12);
} finally {
ErrorContext.instance().reset();
}
return var8;
}
构建步骤:Environment>>TransactionFactory+autoCommit+tx-level>>Transaction+ExecType>>Executor+Configuration+autoCommit>>SqlSession
其中,Environment是Configuration中的属性。
4. 调用Executor执行数据库操作&&生成具体SQL指令
在拿到SqlSession对象后,我们调用它的insert方法。
public int insert(String statement, Object parameter) {
return this.update(statement, parameter);
}
它调用了自身的update(statement, parameter)方法:
public int update(String statement, Object parameter) {
int var4;
try {
this.dirty = true;
MappedStatement ms = this.configuration.getMappedStatement(statement);
// wrapCollection(parameter)判断 param对象是否是集合
var4 = this.executor.update(ms, this.wrapCollection(parameter));
} catch (Exception var8) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + var8, var8);
} finally {
ErrorContext.instance().reset();
}
return var4;
}
mappedStatements就是我们平时说的sql映射对象.
源码如下:protected final Map<String, MappedStatement> mappedStatements;
可见它是一个Map集合,在我们加载xml配置的时候,mapping.xml的namespace和id信息就会存放为mappedStatements的key,对应的,sql语句就是对应的value.
然后调用BaseExecutor中的update方法:
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (this.closed) {
throw new ExecutorException("Executor was closed.");
} else {
this.clearLocalCache();
// 真正做执行操作的方法
return this.doUpdate(ms, parameter);
}
}
doUpdate才是真正做执行操作的方法:
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
int var6;
try {
Configuration configuration = ms.getConfiguration();
// 创建StatementHandler对象,从而创建Statement对象
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, (ResultHandler)null, (BoundSql)null);
// 将sql语句和参数绑定并生成SQL指令
stmt = this.prepareStatement(handler, ms.getStatementLog());
var6 = handler.update(stmt);
} finally {
this.closeStatement(stmt);
}
return var6;
}
先来看看prepareStatement方法,看看mybatis是如何将sql拼接合成的:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Connection connection = this.getConnection(statementLog);
// 准备Statement
Statement stmt = handler.prepare(connection);
// 设置SQL查询中的参数值
handler.parameterize(stmt);
return stmt;
}
来看看parameterize方法:
public void parameterize(Statement statement) throws SQLException {
this.parameterHandler.setParameters((PreparedStatement)statement);
}
这里把statement转换程PreparedStatement对象,它比Statement更快更安全。
这都是我们在JDBC中熟用的对象,就不做介绍了,所以也能看出来Mybatis是对JDBC的封装。
从ParameterMapping中读取参数值和类型,然后设置到SQL语句中:
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(this.mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = this.boundSql.getParameterMappings();
if (parameterMappings != null) {
for(int i = 0; i < parameterMappings.size(); ++i) {
ParameterMapping parameterMapping = (ParameterMapping)parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
String propertyName = parameterMapping.getProperty();
Object value;
if (this.boundSql.hasAdditionalParameter(propertyName)) {
value = this.boundSql.getAdditionalParameter(propertyName);
} else if (this.parameterObject == null) {
value = null;
} else if (this.typeHandlerRegistry.hasTypeHandler(this.parameterObject.getClass())) {
value = this.parameterObject;
} else {
MetaObject metaObject = this.configuration.newMetaObject(this.parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = this.configuration.getJdbcTypeForNull();
}
try {
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException var10) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + var10, var10);
} catch (SQLException var11) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + var11, var11);
}
}
}
}
}
5. 对查询结果二次封装
在doUpdate方法中,解析生成完新的SQL后,然后执行var6 = handler.update(stmt);我们来看看它的源码。
public int update(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement)statement;
// 执行sql
ps.execute();
// 获取返回值
int rows = ps.getUpdateCount();
Object parameterObject = this.boundSql.getParameterObject();
KeyGenerator keyGenerator = this.mappedStatement.getKeyGenerator();
keyGenerator.processAfter(this.executor, this.mappedStatement, ps, parameterObject);
return rows;
}
因为我们是插入操作,返回的是一个int类型的值,所以这里mybatis给我们直接返回int。
如果是query操作,返回的是一个ResultSet,mybatis将查询结果包装程ResultSetWrapper类型,然后一步步对应java类型赋值等…有兴趣的可以自己去看看。
6. 提交与事务
最后,来看看commit()方法的源码。
public void commit() {
this.commit(false);
}
调用其对象本身的commit()方法:
public void commit(boolean force) {
try {
// 是否提交(判断是提交还是回滚)
this.executor.commit(this.isCommitOrRollbackRequired(force));
this.dirty = false;
} catch (Exception var6) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + var6, var6);
} finally {
ErrorContext.instance().reset();
}
}
如果dirty是false,则进行回滚;如果是true,则正常提交。
private boolean isCommitOrRollbackRequired(boolean force) {
return !this.autoCommit && this.dirty || force;
}
调用CachingExecutor的commit方法:
public void commit(boolean required) throws SQLException {
this.delegate.commit(required);
this.tcm.commit();
}
调用BaseExecutor的commit方法:
public void commit(boolean required) throws SQLException {
if (this.closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
} else {
this.clearLocalCache();
this.flushStatements();
if (required) {
this.transaction.commit();
}
}
}
最后调用JDBCTransaction的commit方法:
public void commit() throws SQLException {
if (this.connection != null && !this.connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Committing JDBC Connection [" + this.connection + "]");
}
// 提交连接
this.connection.commit();
}
}
Demo参考文档
http://www.mybatis.org/mybatis-3/zh/getting-started.html
Mybatis 使用了哪些设计模式?
Mybatis源码中使用了大量的设计模式,阅读源码并观察设计模式在其中的应用,能够更深入的理解设计模式。
Mybatis至少遇到了以下的设计模式的使用:
-
Builder模式,例如SqlSessionFactoryBuilder、XMLConfigBuilder、XMLMapperBuilder、XMLStatementBuilder、CacheBuilder;
-
工厂模式,例如SqlSessionFactory、ObjectFactory、MapperProxyFactory;
-
单例模式,例如ErrorContext和LogFactory;
-
代理模式,Mybatis实现的核心,比如MapperProxy、ConnectionLogger,用的jdk的动态代理;还有executor.loader包使用了cglib或者javassist达到延迟加载的效果;
-
组合模式,例如SqlNode和各个子类ChooseSqlNode等;
-
模板方法模式,例如BaseExecutor和SimpleExecutor,还有BaseTypeHandler和所有的子类例如IntegerTypeHandler;
-
适配器模式,例如Log的Mybatis接口和它对jdbc、log4j等各种日志框架的适配实现;
-
装饰者模式,例如Cache包中的cache.decorators子包中等各个装饰者的实现;
-
迭代器模式,例如迭代器模式PropertyTokenizer;
接下来挨个模式进行解读,先介绍模式自身的知识,然后解读在Mybatis中怎样应用了该模式。
Builder模式的定义是“将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。”,它属于创建类模式,一般来说,如果一个对象的构建比较复杂,超出了构造函数所能包含的范围,就可以使用工厂模式和Builder模式,相对于工厂模式会产出一个完整的产品,Builder应用于更加复杂的对象的构建,甚至只会构建产品的一个部分。

在Mybatis环境的初始化过程中,SqlSessionFactoryBuilder会调用XMLConfigBuilder读取所有的MybatisMapConfig.xml和所有的*Mapper.xml文件,构建Mybatis运行的核心对象Configuration对象,然后将该Configuration对象作为参数构建一个SqlSessionFactory对象。
其中XMLConfigBuilder在构建Configuration对象时,也会调用XMLMapperBuilder用于读取*Mapper文件,而XMLMapperBuilder会使用XMLStatementBuilder来读取和build所有的SQL语句。
在这个过程中,有一个相似的特点,就是这些Builder会读取文件或者配置,然后做大量的XpathParser解析、配置或语法的解析、反射生成对象、存入结果缓存等步骤,这么多的工作都不是一个构造函数所能包括的,因此大量采用了Builder模式来解决。
对于builder的具体类,方法都大都用build*开头,比如SqlSessionFactoryBuilder为例,它包含以下方法:

即根据不同的输入参数来构建SqlSessionFactory这个工厂对象。
在Mybatis中比如SqlSessionFactory使用的是工厂模式,该工厂没有那么复杂的逻辑,是一个简单工厂模式。
简单工厂模式(Simple Factory Pattern):又称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。在简单工厂模式中,可以根据参数的不同返回不同类的实例。简单工厂模式专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。

SqlSession可以认为是一个Mybatis工作的核心的接口,通过这个接口可以执行执行SQL语句、获取Mappers、管理事务。类似于连接MySQL的Connection对象。

可以看到,该Factory的openSession方法重载了很多个,分别支持autoCommit、Executor、Transaction等参数的输入,来构建核心的SqlSession对象。
在DefaultSqlSessionFactory的默认工厂实现里,有一个方法可以看出工厂怎么产出一个产品:
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level,
boolean autoCommit){
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call
// close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
这是一个openSession调用的底层方法,该方法先从configuration读取对应的环境配置,然后初始化TransactionFactory获得一个Transaction对象,然后通过Transaction获取一个Executor对象,最后通过configuration、Executor、是否autoCommit三个参数构建了SqlSession。
在这里其实也可以看到端倪,SqlSession的执行,其实是委托给对应的Executor来进行的。
而对于LogFactory,它的实现代码:
public final class LogFactory {
private static Constructor<? extends Log> logConstructor;
private LogFactory() {
// disable construction
}
public static Log getLog(Class<?> aClass) {
return getLog(aClass.getName());
}
这里有个特别的地方,是Log变量的的类型是Constructor<? extends Log>,也就是说该工厂生产的不只是一个产品,而是具有Log公共接口的一系列产品,比如Log4jImpl、Slf4jImpl等很多具体的Log。
单例模式(Singleton Pattern):单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,它提供全局访问的方法。
单例模式的要点有三个:一是某个类只能有一个实例;二是它必须自行创建这个实例;三是它必须自行向整个系统提供这个实例。单例模式是一种对象创建型模式。单例模式又名单件模式或单态模式。

在Mybatis中有两个地方用到单例模式,ErrorContext和LogFactory,其中ErrorContext是用在每个线程范围内的单例,用于记录该线程的执行环境错误信息,而LogFactory则是提供给整个Mybatis使用的日志工厂,用于获得针对项目配置好的日志对象。设计模式之单例模式实践,这篇文章推荐你看下。
ErrorContext的单例实现代码:
public class ErrorContext {
private static final ThreadLocal<ErrorContext> LOCAL = new ThreadLocal<ErrorContext>();
private ErrorContext() {
}
public static ErrorContext instance() {
ErrorContext context = LOCAL.get();
if (context == null) {
context = new ErrorContext();
LOCAL.set(context);
}
return context;
}
构造函数是private修饰,具有一个static的局部instance变量和一个获取instance变量的方法,在获取实例的方法中,先判断是否为空如果是的话就先创建,然后返回构造好的对象。
只是这里有个有趣的地方是,LOCAL的静态实例变量使用了ThreadLocal修饰,也就是说它属于每个线程各自的数据,而在instance()方法中,先获取本线程的该实例,如果没有就创建该线程独有的ErrorContext。
代理模式可以认为是Mybatis的核心使用的模式,正是由于这个模式,我们只需要编写Mapper.java接口,不需要实现,由Mybatis后台帮我们完成具体SQL的执行。
代理模式(Proxy Pattern) :给某一个对象提供一个代 理,并由代理对象控制对原对象的引用。代理模式的英 文叫做Proxy或Surrogate,它是一种对象结构型模式。
代理模式包含如下角色:
-
Subject: 抽象主题角色
-
Proxy: 代理主题角色
-
RealSubject: 真实主题角色


这里有两个步骤,第一个是提前创建一个Proxy,第二个是使用的时候会自动请求Proxy,然后由Proxy来执行具体事务;
当我们使用Configuration的getMapper方法时,会调用mapperRegistry.getMapper方法,而该方法又会调用mapperProxyFactory.newInstance(sqlSession)来生成一个具体的代理:
/**
* @author Lasse Voss
*/
public class MapperProxyFactory<T> {
private final Class<T> mapperInterface;
private final Map<Method, MapperMethod> methodCache = new ConcurrentHashMap<Method, MapperMethod>();
public MapperProxyFactory(Class<T> mapperInterface) {
this.mapperInterface = mapperInterface;
}
public Class<T> getMapperInterface() {
return mapperInterface;
}
public Map<Method, MapperMethod> getMethodCache() {
return methodCache;
}
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface },
mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
}
在这里,先通过T newInstance(SqlSession sqlSession)方法会得到一个MapperProxy对象,然后调用T newInstance(MapperProxy<T> mapperProxy)生成代理对象然后返回。
而查看MapperProxy的代码,可以看到如下内容:
public class MapperProxy<T> implements InvocationHandler, Serializable {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}
非常典型的,该MapperProxy类实现了InvocationHandler接口,并且实现了该接口的invoke方法。
通过这种方式,我们只需要编写Mapper.java接口类,当真正执行一个Mapper接口的时候,就会转发给MapperProxy.invoke方法,而该方法则会调用后续的sqlSession.cud>executor.execute>prepareStatement等一系列方法,完成SQL的执行和返回。
5、组合模式
组合模式组合多个对象形成树形结构以表示“整体-部分”的结构层次。
组合模式对单个对象(叶子对象)和组合对象(组合对象)具有一致性,它将对象组织到树结构中,可以用来描述整体与部分的关系。同时它也模糊了简单元素(叶子对象)和复杂元素(容器对象)的概念,使得客户能够像处理简单元素一样来处理复杂元素,从而使客户程序能够与复杂元素的内部结构解耦。
在使用组合模式中需要注意一点也是组合模式最关键的地方:叶子对象和组合对象实现相同的接口。这就是组合模式能够将叶子节点和对象节点进行一致处理的原因。

Mybatis支持动态SQL的强大功能,比如下面的这个SQL:
<update id="update" parameterType="org.format.dynamicproxy.mybatis.bean.User">
UPDATE users
<trim prefix="SET" prefixOverrides=",">
<if test="name != null and name != ''">
name = #{name}
</if>
<if test="age != null and age != ''">
, age = #{age}
</if>
<if test="birthday != null and birthday != ''">
, birthday = #{birthday}
</if>
</trim>
where id = ${id}
</update>
在这里面使用到了trim、if等动态元素,可以根据条件来生成不同情况下的SQL;
在DynamicSqlSource.getBoundSql方法里,调用了rootSqlNode.apply(context)方法,apply方法是所有的动态节点都实现的接口:
public interface SqlNode {
boolean apply(DynamicContext context);
}
对于实现该SqlSource接口的所有节点,就是整个组合模式树的各个节点:

组合模式的简单之处在于,所有的子节点都是同一类节点,可以递归的向下执行,比如对于TextSqlNode,因为它是最底层的叶子节点,所以直接将对应的内容append到SQL语句中:
@Override
public boolean apply(DynamicContext context) {
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
context.appendSql(parser.parse(text));
return true;
}
但是对于IfSqlNode,就需要先做判断,如果判断通过,仍然会调用子元素的SqlNode,即contents.apply方法,实现递归的解析。
@Override
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
6、模板方法模式
模板方法模式是所有模式中最为常见的几个模式之一,是基于继承的代码复用的基本技术。关注Java技术栈微信公众号,在后台回复关键字:架构,可以获取更多栈长整理的架构和设计模式干货。
模板方法模式需要开发抽象类和具体子类的设计师之间的协作。一个设计师负责给出一个算法的轮廓和骨架,另一些设计师则负责给出这个算法的各个逻辑步骤。代表这些具体逻辑步骤的方法称做基本方法(primitive method);而将这些基本方法汇总起来的方法叫做模板方法(template method),这个设计模式的名字就是从此而来。
模板类定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。

在Mybatis中,sqlSession的SQL执行,都是委托给Executor实现的,Executor包含以下结构:

其中的BaseExecutor就采用了模板方法模式,它实现了大部分的SQL执行逻辑,然后把以下几个方法交给子类定制化完成:
protected abstract int doUpdate(MappedStatement ms, Object parameter) throws SQLException;
protected abstract List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException;
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) throws SQLException;
该模板方法类有几个子类的具体实现,使用了不同的策略:
-
简单SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。(可以是Statement或PrepareStatement对象)
-
重用ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。(可以是Statement或PrepareStatement对象)
-
批量BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理的;BatchExecutor相当于维护了多个桶,每个桶里都装了很多属于自己的SQL,就像苹果蓝里装了很多苹果,番茄蓝里装了很多番茄,最后,再统一倒进仓库。(可以是Statement或PrepareStatement对象)
比如在SimpleExecutor中这样实现update方法:
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null,
null);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}
7、适配器模式
适配器模式(Adapter Pattern) :将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。

在Mybatsi的logging包中,有一个Log接口:
/**
* @author Clinton Begin
*/
public interface Log {
boolean isDebugEnabled();
boolean isTraceEnabled();
void error(String s, Throwable e);
void error(String s);
void debug(String s);
void trace(String s);
void warn(String s);
}
该接口定义了Mybatis直接使用的日志方法,而Log接口具体由谁来实现呢?Mybatis提供了多种日志框架的实现,这些实现都匹配这个Log接口所定义的接口方法,最终实现了所有外部日志框架到Mybatis日志包的适配:

比如对于Log4jImpl的实现来说,该实现持有了org.apache.log4j.Logger的实例,然后所有的日志方法,均委托该实例来实现。
public class Log4jImpl implements Log {
private static final String FQCN = Log4jImpl.class.getName();
private Logger log;
public Log4jImpl(String clazz) {
log = Logger.getLogger(clazz);
}
@Override
public boolean isDebugEnabled() {
return log.isDebugEnabled();
}
@Override
public boolean isTraceEnabled() {
return log.isTraceEnabled();
}
@Override
public void error(String s, Throwable e) {
log.log(FQCN, Level.ERROR, s, e);
}
@Override
public void error(String s) {
log.log(FQCN, Level.ERROR, s, null);
}
@Override
public void debug(String s) {
log.log(FQCN, Level.DEBUG, s, null);
}
@Override
public void trace(String s) {
log.log(FQCN, Level.TRACE, s, null);
}
@Override
public void warn(String s) {
log.log(FQCN, Level.WARN, s, null);
}
}
8、装饰者模式
装饰模式(Decorator Pattern) :动态地给一个对象增加一些额外的职责(Responsibility),就增加对象功能来说,装饰模式比生成子类实现更为灵活。其别名也可以称为包装器(Wrapper),与适配器模式的别名相同,但它们适用于不同的场合。根据翻译的不同,装饰模式也有人称之为“油漆工模式”,它是一种对象结构型模式。

在mybatis中,缓存的功能由根接口Cache(org.apache.ibatis.cache.Cache)定义。关注Java技术栈微信公众号,在后台回复关键字:架构,可以获取更多栈长整理的架构和设计模式干货。
整个体系采用装饰器设计模式,数据存储和缓存的基本功能由PerpetualCache(org.apache.ibatis.cache.impl.PerpetualCache)永久缓存实现,然后通过一系列的装饰器来对PerpetualCache永久缓存进行缓存策略等方便的控制。如下图:

用于装饰PerpetualCache的标准装饰器共有8个(全部在org.apache.ibatis.cache.decorators包中):
-
FifoCache:先进先出算法,缓存回收策略
-
LoggingCache:输出缓存命中的日志信息
-
LruCache:最近最少使用算法,缓存回收策略
-
ScheduledCache:调度缓存,负责定时清空缓存
-
SerializedCache:缓存序列化和反序列化存储
-
SoftCache:基于软引用实现的缓存管理策略
-
SynchronizedCache:同步的缓存装饰器,用于防止多线程并发访问
-
WeakCache:基于弱引用实现的缓存管理策略
另外,还有一个特殊的装饰器TransactionalCache:事务性的缓存
正如大多数持久层框架一样,mybatis缓存同样分为一级缓存和二级缓存
-
一级缓存,又叫本地缓存,是PerpetualCache类型的永久缓存,保存在执行器中(BaseExecutor),而执行器又在SqlSession(DefaultSqlSession)中,所以一级缓存的生命周期与SqlSession是相同的。
-
二级缓存,又叫自定义缓存,实现了Cache接口的类都可以作为二级缓存,所以可配置如encache等的第三方缓存。二级缓存以namespace名称空间为其唯一标识,被保存在Configuration核心配置对象中。
二级缓存对象的默认类型为PerpetualCache,如果配置的缓存是默认类型,则mybatis会根据配置自动追加一系列装饰器。
Cache对象之间的引用顺序为:
SynchronizedCache–>LoggingCache–>SerializedCache–>ScheduledCache–>LruCache–>PerpetualCache
9、迭代器模式
迭代器(Iterator)模式,又叫做游标(Cursor)模式。GOF给出的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。

Java的Iterator就是迭代器模式的接口,只要实现了该接口,就相当于应用了迭代器模式:

比如Mybatis的PropertyTokenizer是property包中的重量级类,该类会被reflection包中其他的类频繁的引用到。这个类实现了Iterator接口,在使用时经常被用到的是Iterator接口中的hasNext这个函数。
public class PropertyTokenizer implements Iterator<PropertyTokenizer> {
private String name;
private String indexedName;
private String index;
private String children;
public PropertyTokenizer(String fullname) {
int delim = fullname.indexOf('.');
if (delim > -1) {
name = fullname.substring(0, delim);
children = fullname.substring(delim + 1);
} else {
name = fullname;
children = null;
}
indexedName = name;
delim = name.indexOf('[');
if (delim > -1) {
index = name.substring(delim + 1, name.length() - 1);
name = name.substring(0, delim);
}
}
public String getName() {
return name;
}
public String getIndex() {
return index;
}
public String getIndexedName() {
return indexedName;
}
public String getChildren() {
return children;
}
@Override
public boolean hasNext() {
return children != null;
}
@Override
public PropertyTokenizer next() {
return new PropertyTokenizer(children);
}
@Override
public void remove() {
throw new UnsupportedOperationException(
"Remove is not supported, as it has no meaning in the context of properties.");
}
}
可以看到,这个类传入一个字符串到构造函数,然后提供了iterator方法对解析后的子串进行遍历,是一个很常用的方法类。
1、#{}和${}的区别是什么?
答:${}是Properties文件中的变量占位符,它可以用于标签属性值和sql内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc.Driver。#{}是sql的参数占位符,Mybatis会将sql中的#{}替换为?号,在sql执行前会使用PreparedStatement的参数设置方法,按序给sql的?号占位符设置参数值,比如ps.setInt(0, parameterValue),#{item.name}的取值方式为使用反射从参数对象中获取item对象的name属性值,相当于param.getItem().getName()。
2、Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?
答:还有很多其他的标签,<resultMap>、<parameterMap>、<sql>、<include>、<selectKey>,加上动态sql的9个标签,trim|where|set|foreach|if|choose|when|otherwise|bind等,其中<sql>为sql片段标签,通过<include>标签引入sql片段,<selectKey>为不支持自增的主键生成策略标签。
3、最佳实践中,通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
答:Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
4、Mybatis是如何进行分页的?分页插件的原理是什么?
答:Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10
5、简述Mybatis的插件运行原理,以及如何编写一个插件。
答:Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这4种接口的插件,Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler的invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
实现Mybatis的Interceptor接口并复写intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
6、Mybatis执行批量插入,能返回数据库主键列表吗?
答:能,JDBC都能,Mybatis当然也能。
7、Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?
答:Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能,Mybatis提供了9种动态sql标签trim|where|set|foreach|if|choose|when|otherwise|bind。
其执行原理为,使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能。
8、Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
答:第一种是使用<resultMap>标签,逐一定义列名和对象属性名之间的映射关系。第二种是使用sql列的别名功能,将列别名书写为对象属性名,比如T_NAME AS NAME,对象属性名一般是name,小写,但是列名不区分大小写,Mybatis会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成T_NAME AS NaMe,Mybatis一样可以正常工作。
有了列名与属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
9、Mybatis能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别。
答:能,Mybatis不仅可以执行一对一、一对多的关联查询,还可以执行多对一,多对多的关联查询,多对一查询,其实就是一对一查询,只需要把selectOne()修改为selectList()即可;多对多查询,其实就是一对多查询,只需要把selectOne()修改为selectList()即可。
关联对象查询,有两种实现方式,一种是单独发送一个sql去查询关联对象,赋给主对象,然后返回主对象。另一种是使用嵌套查询,嵌套查询的含义为使用join查询,一部分列是A对象的属性值,另外一部分列是关联对象B的属性值,好处是只发一个sql查询,就可以把主对象和其关联对象查出来。
那么问题来了,join查询出来100条记录,如何确定主对象是5个,而不是100个?其去重复的原理是<resultMap>标签内的<id>子标签,指定了唯一确定一条记录的id列,Mybatis根据<id>列值来完成100条记录的去重复功能,<id>可以有多个,代表了联合主键的语意。
同样主对象的关联对象,也是根据这个原理去重复的,尽管一般情况下,只有主对象会有重复记录,关联对象一般不会重复。
举例:下面join查询出来6条记录,一、二列是Teacher对象列,第三列为Student对象列,Mybatis去重复处理后,结果为1个老师6个学生,而不是6个老师6个学生。
t_id t_name s_id
| 1 | teacher | 38 |
| 1 | teacher | 39 |
| 1 | teacher | 40 |
| 1 | teacher | 41 |
| 1 | teacher | 42 |
| 1 | teacher | 43 |
10、Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
答:Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
11、Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
答:不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;毕竟namespace不是必须的,只是最佳实践而已。
原因就是namespace+id是作为Map<String, MappedStatement>的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。
12、Mybatis中如何执行批处理?
答:使用BatchExecutor完成批处理。
13、Mybatis都有哪些Executor执行器?它们之间的区别是什么?
答:Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。简言之,就是重复使用Statement对象。
BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。
14、Mybatis中如何指定使用哪一种Executor执行器?
答:在Mybatis配置文件中,可以指定默认的ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数。
15、Mybatis是否可以映射Enum枚举类?
答:Mybatis可以映射枚举类,不单可以映射枚举类,Mybatis可以映射任何对象到表的一列上。映射方式为自定义一个TypeHandler,实现TypeHandler的setParameter()和getResult()接口方法。TypeHandler有两个作用,一是完成从javaType至jdbcType的转换,二是完成jdbcType至javaType的转换,体现为setParameter()和getResult()两个方法,分别代表设置sql问号占位符参数和获取列查询结果。
16、Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
答:虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。
原理是,Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。
17、简述Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?
答:Mybatis将所有Xml配置信息都封装到All-In-One重量级对象Configuration内部。在Xml映射文件中,<parameterMap>标签会被解析为ParameterMap对象,其每个子元素会被解析为ParameterMapping对象。<resultMap>标签会被解析为ResultMap对象,其每个子元素会被解析为ResultMapping对象。每一个<select>、<insert>、<update>、<delete>标签均会被解析为MappedStatement对象,标签内的sql会被解析为BoundSql对象。
18、为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
答:Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。