目录:
1.1什么是数据结构
1.2 基本概念和术语
1.3 抽象数据类型的表示与实现
1.4 算法和算法分析
1.4.1 算法
1.4.2 算法设计的要求
1.4.3 算法效率的度量
1.4.4 算法的存储空间的需求
概述
1,背景 :
《数据结构》是计算机相关专业的一门重要的专业基础课。它主要研究计算机加工对象的逻辑结构、在计算机中的表示形式以及实现各种基本操作的算法。它是学习操作系统、编译原理、数据库原理等计算机专业核心课程的基础,掌握好这门课程的内容,是学习计算机其他相关课程的必备条件。
2,意义
(1)算法和数据结构是计算机科学的两大支柱。
™计算机科学早期定义为: 研究算法的科学
™近期定义为: 研究数据的科学
(2)数据结构是程序设计的基础
™Niklaus Wirth教授提出:程序=算法+数据结构
算 法: 处理问题的策略
数据结构: 问题的数学模型
程 序:为计算机处理问题而编制一组指令集
(3)数据结构是一门介于数学、硬件、软件之间的核心专业基础课。
3,地位

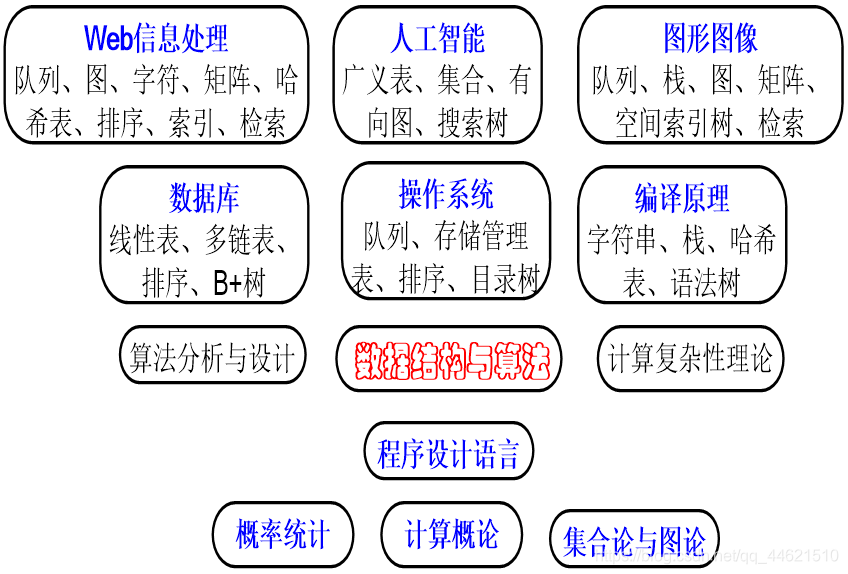
内容
本课程将分别讲述数据结构的基本概念、线性表、栈和队列、串和数组、树形结构、图形结构、查找和排序等内容。
要求:
1.理解各名词、术语的含义,掌握基本概念,特别是数据的逻辑结构和存储结构之间的关系。分清哪些是逻辑结构的性质,哪些是存储结构的性质。
2.了解抽象数据类型的定义、表示和实现方法。
3.理解类C语言的书写规范,特别要注意值调用和引用调用的区别,输入、输出的方式以及错误处理方式。
4.理解算法五个要素的确切含义
5.掌握计算语句频度和估算算法时间复杂度的方法。
重点:算法和算法分析。
难点:从时间和空间角度分析算法的方法。
1.1什么是数据结构
例1:08061182519610100042
080611:班号
3372699:院系号
617000:学校邮编
511902199505207298:身份证号
结论1:杂乱的数据不能表达和交流信息
例2 电话号码查询系统
设有一个电话号码薄,它记录了n个人的名字和其相应的电话号码,假定按如下形式安排:
(a1,b1)(a2,b2)…(an,bn)
其中ai,bi(i=1,2…n) 分别表示某人的名字和对应电话号码
问题:设计一个算法,当给定任何一个人的名字时,该算法能够打印出此人的电话号码,如果该电话簿中根本就没有这个人,则该算法也能够报告没有这个人的标志。
要做的事情:
–设计恰当的数学模型表示电话号码簿的所有信息
–采用相应查找算法,实现快速查询与打印.
结论2:数据之间是有联系的
例3 酒店管理系统中的客房分配问题.
房间分配方法
采用“先退的房间先被起用”的算法.
房间信息组织方法:
所有“空”的同类房间的数据模型应该是一个“队列”
从“队头”分配客房;退掉的空客房排在“队尾”。
例4: 铺设煤气管道问题
n个居民区之间铺设煤气管道,
只要铺设n-1条管道即可。
假设:
任意两个居民区之间都可以架设管道,
每条管道的费用成本不同,
要解决的问题:
用一定的数据模型表示该问题,在此基础上计算投资最少(或尽可能少的)的管道铺设方案。
例5 表1-1 教务处人事简表
| 职工号 | 姓名 | 性别 | 出生年月 | 职务 | 单位 |
|---|---|---|---|---|---|
| 01 | 徐凤年 | 男 | 1972.8 | 处长 | |
| 02 | 陈芝豹 | 男 | 1968.2 | 科长 | 教材科 |
| 03 | 洛阳 | 女 | 1956.3 | 科长 | 考务科 |
| 04 | 红麝 | 女 | 1964.2 | 主任 | 办公室 |
| 05 | 曹长卿 | 男 | 1970.1 | 科员 | 教材科 |
| 06 | 徐脂虎 | 女 | 1972.3 | 科员 | 教材科 |
| 07 | 李当心 | 男 | 1956.4 | 科员 | 考务科 |
| 08 | 王仙芝 | 男 | 1950.1 | 科员 | 考务科 |
| 09 | 李淳罡 | 男 | 1958.2 | 科员 | 考务科 |
| 10 | 邓太阿 | 男 | 1962.9 | 科员 | 办公室 |
PS:人名出自武侠玄幻小说《雪中悍刀行》
按职工年龄从大到小排序(线性结构):
08->03->07->09->10->04->02->05->06->01
领导和被领导的关系(树型结构):
01
| | |
02 03 04
| | | | | |
05 06 07 08 09 10
朋友关系(网状结构):


例六:制定教学计划
在制定教学计划时,需要考虑各门课程的开设顺序。有些课程需要先导课程,有些课程则不需要,而有些课程又是其他课程的先导课程。比如,计算机专业课程的开设情况如下表1-2所示:

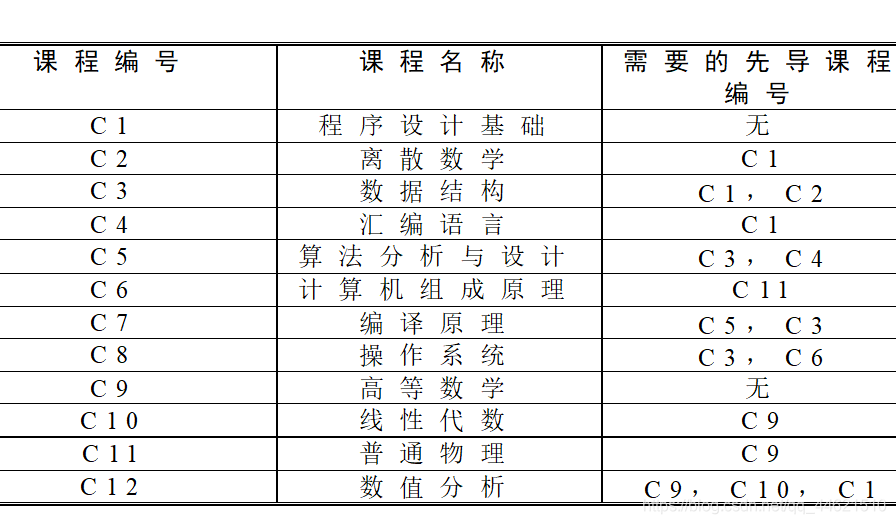

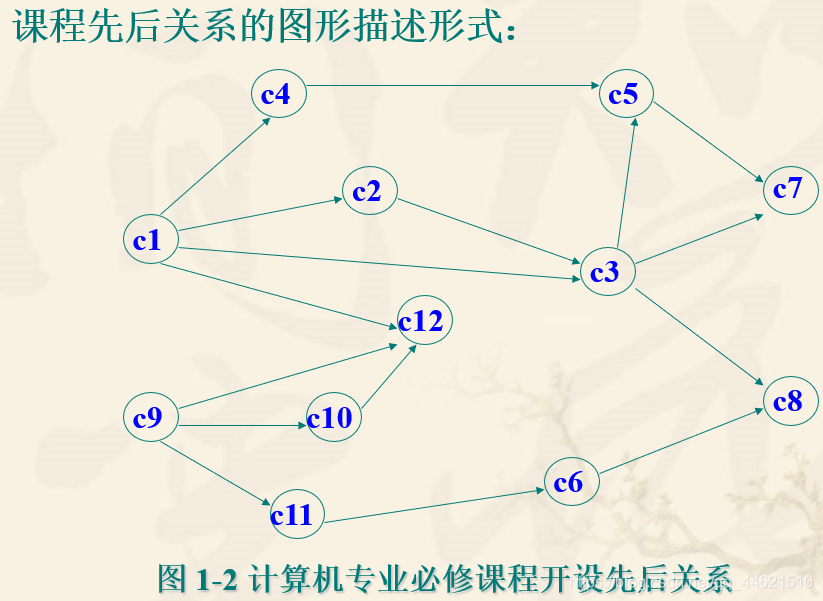
结论3:数据之间是有结构的
1.2 基本概念和术语
数据:描述客观事物的数字、字符以及一切能够输入到计算机中,并且能够被计算机程序处理的符号的集合
结构:数据元素之间具有的关系。
数据结构 :具有结构的数据元素的集合。 DS=(D,R)
数据元素:数据整体中相对独立的基本单位,数据这个集合中的一个一个的个体。 数据元素也称为数据结点。
数据对象:具有相同特性的数据元素的集合。是数据集合的子集。
一,基本概念
1,数据(Data)
所有能被输入到计算机中,且能被计算机处理的符号的集合,计算机能够操作的对象的总称。是计算机处理的信息的某种特定符号表示形式。
2,数据元素(Data Element)
是数据集合中的一个“个体”,是计算机程序中加工处理的基本单位。
数据元素按其组成可分为简单型数据元素和复杂型数据元素。简单型数据元素由一个数据项组成,所谓数据项(Data item)就是数据中不可再分割的最小单位;复杂型数据元素由多个数据项组成,它通常携带着一个概念的多方面信息。
3,数据元素(Data Element)
是数据集合中的一个“个体”,是计算机程序中加工处理的基本单位。
数据元素按其组成可分为简单型数据元素和复杂型数据元素。简单型数据元素由一个数据项组成,所谓数据项(Data item)就是数据中不可再分割的最小单位;复杂型数据元素由多个数据项组成,它通常携带着一个概念的多方面信息。
4,数据对象(Data Object)
是性质相同的一类数据元素的集合,是数据的一个子集。
5,数据结构(Data Structure)
就是相互之间存在一种或多种特定关系的数据元素的集合。
(1)数据元素之间的联系称之为结构,数据结构就是具有结构的数据元素的集合。
(2)是一个二元组
Data-Structure=( D, S)
其中,D(某一数据对象)是数据元素的有限集合,S是D上的关系的集合。
二,术语
1,逻辑结构:
数据元素之间具有的逻辑关系(结构)
(1)分四类
线性结构:
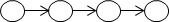
树形结构:
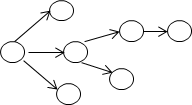
图状结构:
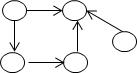
集合结构:
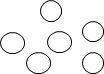
(2)分两类
线性结构和非线性结构
**线性结构的逻辑特征是:有且仅有一个始端结点和一个终端结点,并且除两个端点结点外的所有结点都有且仅有一个前趋结点和一个后继结点。线性表、堆栈、队列、数组、串等都是线性结构。
**非线性结构的逻辑特征是:一个结点可以有多个前趋结点和后继结点。如树形结构、图等。
2,物理结构:
具有某种逻辑结构的数据在计算机存储器中的存储方式(存储映象)。
数据的物理结构是逻辑结构在计算机存储器里的映像,也称为存储结构。
常见的存储结构:
顺序存储结构:特点是借助于数据元素的相对存储位置来表示数据元素之间的逻辑结构
链式存储结构:特点是借助于指示数据元素地址的指针表示数据元素之间的逻辑结构
索引存储方法:除建立存储结点信息外,还建立附加的索引表来标识结点的地址
散列存储方法:根据结点的关键字直接计算出该结点的存储地址
————————————————————————
线性结构—————|
树形结构—————|——|
————————————|——逻辑结构
图状结构—————|——|
纯集合结构————|
——————————————————
顺序存储结构——|
链式存储结构——|
—————————|——存储结构
索引存储结构——|
散列存储结构——|
6、数据类型(Data Type)
一个值的集合和定义在这个值集上的一组操作的总称。 按“值”的特性又可分为:
原子类型(其值不可分解)
结构类型(其值可再分解)
7、抽象数据类型(Abstract Data Type,简称ADT)
一个数学模型以及定义在该模型上的一组操作。包括各处理器中已定义并实现的固有数据类型以及用户自己定义的数据类型。
1)一个含ADT的软件模块通常包含定义、表示和实现3个部分
2)ADT的定义由一个值域和定义在该值域上的一组操作组成。按其值的特性可分为:原子类型、固定聚合类型、可变聚合类型,后两种合称结构类型
3)ADT的形式定义: (D,S,P) 其中D是数据对象,S是D上的关系集,P是对D的基本操作集。形如:
ADT 抽象数据类型名 {
数据对象:〈数据对象的定义〉
数据关系:〈数据关系的定义〉
基本操作:〈基本操作的定义〉
} ADT 抽象数据类型名
例:抽象数据类型复数的定义:
ADT Complex{
数据对象:D={e1,e2 | e1,e2属于实数}
数据关系:R1={<e1,e2>|e1是复数的实数部分
|e2是复数的虚数部分}
基本操作:InitComplex(&Z,v1,v2)
//构造复数Z,实部虚部分别赋值v1和v2
DestroyComplex(&Z) //销毁复数Z
GetReal(Z,&RealPart)//得到复数z的实部
GetImag(Z,&ImagPart) //得到复数的虚部
Add(z1,z2,&sum) //用sum返回复数z1和z2的和
} ADT Complex
1.3抽象数据类型的表示和实现
P9–P13
1.4 算法描述与分析
一、算法
1、算法是解决某个特定问题的方法和步骤的描述。
计算机对数据的操作可以分为数值性和非数值性两种类型。在数值性操作中主要进行的是算术运算;而在非数值性操作中主要进行的是查找、排序、插入、删除、修改等等。
2,算法的五大特性
输入,输出,有穷性,确定性,可行性
3,算法的描述方法
自然语言,计算机,流程图
二、算法的设计要求
(1) 正确性:要求算法能够正确地执行预先规定的功能,并达到所期望的性能要求。
(2) 可读性:便于理解、测试和修改算法。
(3) 健壮性:对非法输入能适当地做出反应或进行处理,而不会产生莫名其妙的输出结果。
(4) 时间与空间效率:算法的时间与空间效率是指将算法变换为程序后,该程序在计算机上运行时所花费的时间及所占据空间的度量。
**算法分析(Algorithm Analysis):
对算法所需要的计算机资源——时间和空间进行估算。
时间复杂性(Time Complexity)
空间复杂性(Space Complexity)
三、算法效率的度量
1、算法的时间效率
(1)事后统计
缺点: 1.必须执行程序
2.软硬件环境易掩盖算法优劣
(2)事前分析估算法
以基本语句的执行次数作为时间单位进行估算。
**和算法执行时间相关的因素:
( 1)算法选用的策略
( 2)问题的规模
(3)编写程序的语言
(4)编译程序产生的机器代码的质量
( 5)计算机执行指令的速度
**时间复杂度的渐进表示法
算法中基本语句重复执行的次数是问题规模n的某个函数f(n),算法的时间量度记作 :T(n)=O(f(n))
表示随着n的增大,算法执行的时间的增长率和f(n)的增长率相同,称渐近时间复杂度。
数学符号“O”的定义为:
若T(n)和f(n)是定义在正整数集合上的两个函数,则T(n) = O(f(n))表示存在正的常数C和n0,使得当n≥n0时都满足0≤T(n)≤Cf(n)。
算法中重复执行次数和算法的执行时间成正比的语句对算法运行时间的贡献最大
n越大算法的执行时间越长
排序:n为记录数
矩阵:n为矩阵的阶数
多项式:n为多项式的项数
集合:n为元素个数
树:n为树的结点个数
图:n为图的顶点数或边数
n * n阶矩阵加法:
for( i = 0; i < n; i++)
for( j = 0; j < n; j++)
c[i][j] = a[i][j] + b[i][j];
语句的频度(Frequency Count ): 重复执行的次数:n*n;
T( n ) = O ( n 2)
即:矩阵加法的运算量和问题的规模n的平方是同一个量级
算法的时间复杂度分析:
算法的执行时间 = 每条语句执行时间之和
| |
每条语句执行次数之和 |
| 执行次数×执行一次的时间 ——单位时间
基本语句的执行次数 |
指令系统、编译的代码质量
分析算法时间复杂度的基本方法
•找出语句频度最大的那条语句作为基本语句
•计算基本语句的频度得到问题规模n的某个函数f(n)
•取其数量级用符号“O”表示
x=0;y=0;
for ( int k = 0; k < n; k ++ )
x ++;
for ( int i = 0; i < n; i++ )
for ( int j = 0; j < n; j++ )
y ++;
//f(n)=n2 -> T(n)=O(n2)
时间复杂度是由嵌套最深层语句的频度决定的
void exam ( float x[ ][ ], int m, int n ) {
float sum [ ];
for ( int i = 0; i < m; i++ ) {
sum[i] = 0.0;
for ( int j = 0; j < n; j++ )
sum[i] += x[i][j]; //f(n)=m*n -> T(n)=O(m*n)
}
for ( i = 0; i < m; i++ )
cout << i << “ : ” <<sum [i] << endl;
}
//例1:N×N矩阵相乘
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
{c[i][j]=0;
for(k=1;k<=n;k++)
c[i][j]=c[i][j]+a[i][k]*b[k][j]; //T(n)=O(n3)
}
//算法中的基本操作语句为c[i][j]=c[i][j]+a[i][k]*b[k][j];
例2:
for( i=1; i<=n; i++)
for (j=1; j<=i; j++)
for (k=1; k<=j; k++)
x=x+1;

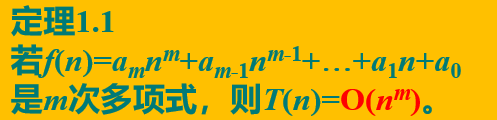
忽略所有低次幂项和最高次幂系数,体现出增长率的含义
//例3:分析以下程序段的时间复杂度
i=1;
while(i<=n)
i=i*2;
即f(n)≤log2n,取最大值f(n)=log2n
所以该程序段的时间复杂度T(n) =O( log2n)
有的情况下,算法中基本操作重复执行的次数还随问题的输入数据集不同而不同
//例4:顺序查找,在数组a[i]中查找值等于e的元素,返回其所在位置。
for (i=0;i< n;i++)
if (a[i]==e) return i+1;
return 0;
//最好情况:1次
//最坏情况:n
//平均时间复杂度为:O(n)
当n取得很大时,指数时间算法和多项式时间算法在所需时间上非常悬殊
时间复杂度T(n)按数量级递增顺序为:
复杂度低 复杂度高
——————————————————————————————>
| 常数阶 | 对数阶 | 线性阶 | 线性对数阶 | 平方阶 | 立方阶 | 。。。 | K次方阶 | 指数阶 |
|---|---|---|---|---|---|---|---|---|
| O(1) | O(log2n) | O(n) | O(nlog2n) | O(n2) | O(n3) | … | O(nK) | O(2n) |
//例一:
{++x;}
//基本操作: x自加操作
//语句频度: 1
//时间复杂度: O(1)
//例二:
for(i=1;i<=n;i++)
{++x;}
//基本操作: x自加操作
//语句频度: n
//时间复杂度: O(n)
//例三:
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
{++x;}
//基本操作: x自加操作
//语句频度: n2
//时间复杂度: O(n2)
//例四:
for(i=0;i<n;i++)
for(j=0;j<n;j++)
{
c[i][j]=0;
for(k=0;k<n;k++)
c[i][j] += a[i][k]*b[k][j];
}
//基本操作: 乘法操作
//语句频度: n3
//时间复杂度: O(n3)
//例5:
for(i=2;i<=n;i++)
for(j=2;j<=i-1;j++)
++x;
//基本操作: x自加操作
//语句频度: (n-1)(n-2)/2
//时间复杂度: O(n2)
2,算法的空间效率分析
空间复杂度:算法所需存储空间的度量,记作: S(n)=O(f(n))
其中n为问题的规模(或大小)
四、算法的存储空间的需求
算法本身要占据的空间,输入/输出,指令,常数,变量等
算法要使用的辅助空间
//例5:将一维数组a中的n个数逆序存放到原数组中。
//【算法1】
for(i=0;i<n/2;i++)
{ t=a[i];
a[i]=a[n-i-1];
a[n-i-1]=t;
}
//S(n) = O(1)
//【算法2】
for(i=0;i<n;i++)
b[i]=a[n-i-1];
for(i=0;i<n;i++)
a[i]=b[i];
//S(n) = O(n)
小结:
1、数据、数据元素、数据项、数据结构等基本概念
2、对数据结构的两个层次的理解
•逻辑结构
•存储结构
3、抽象数据类型的表示方法
4、算法、算法的时间复杂度及其分析的简易方法