监控摄像机的视频摘要(Video Summarization of Surveillance Cameras)
摘要:
近年来,视频监控摄像机的数量大幅增加。因此,需要处理捕获的视频,使得操作人员可以在很长一段时间内快速查看由摄像机记录的活动。我们在本文中提出了一种制作视频摘要的方法,这是一种保留了重要元素的缩略视频。我们引入了一个数据集以及三个评估指标,用于量化视频摘要的性能,包括压缩长度,保留的活动量以及打包到摘要的每个帧中的活动量。
第1节 介绍
部署在私人场所和公共场所的视频监控摄像机的数量正在不断增加。目前运行的摄像机估计数量超过200,000,000。它们每周共产生超过1000万GB的视频数据。虽然在基于内容的自动视频解释方面取得了相当大的进展,但仍然需要人(比如保安人员,警察等)来查看录制视频的内容。视频数据的可视化分析是耗时的并且在长时间观察之后人容易出错。因此,能够提出可以促进这项艰巨任务的有效解决方案很令人兴奋。
本文研究了监控摄像机自动视频摘要的问题。视频摘要是缩略视频,其保留原始视频的重要元素,同时移除不感兴趣的时空片段。我们在此假设从固定摄像机观察到的场景是由许多移动物体组成的。
为了与原视频相关,视频摘要必须符合许多要求。首先,不得修改对象的空间位置和轨迹。其次,必须应用遮挡规则(例如:较近的物体应遮挡较远的物体)。第三,时间顺序必须保持不变。这是视频的缩短版本,即使对象显示之间的时间发生变化,它们出现的顺序也应保留在原始视频中。第四,物体移动的速度不应该改变,或者至少不要过分夸大。不遵守这些准则可能会彻底改变视频事件的解释方式。
当图像的时间序列被视为3D数据结构[7]时,移动的前景对象形成3D时空形状,有时称为tublets。然后可以独立于背景序列操纵这些时空对象,以产生可解释的概要。因此,本文提出的方法旨在通过提取每个感兴趣对象的轨迹并在视频摘要中优化其排列来生成紧凑的视频摘要。本文的主要贡献如下:
一种通过组合背景减法、光流和像素聚类来获得具有静态物体和自适应运动加速度的时空轨迹的方法。
一种使用“类似俄罗斯方块”策略的基于时间缩减的视频摘要的新方法。
新的评估指标和带有标记的根据视频摘要的长度和原始视频中保留的“活动像素”的数量来量化视频摘要的质量的基本事实的基准数据集。
本文的描述说明组织如下。第2节提供相关工作的调查。第3节详细介绍我们提出的制作视频摘要的方法。第4节介绍我们使用的数据集以及我们新提出的评估视频摘要的评估标准。第5节提供我们评估的结果,并讨论我们的方法的优点。最后,第6节给出结束语。
第2节 相关工作
视频摘要算法可以分为三类:快速转发,关键帧选择和帧重组。
2.1。快速转发
快速转发算法基于固定或自适应间隔中的跳帧来计算视频摘要[17] [10] [12]。在固定帧跳过方案中,如果跳过间隔变得太大,则视频的重要部分可能变得不明显甚至可能丢失。Yeung和Yeo [17]使用视频分析来创建其图片摘要,该摘要是按时间顺序排列的视频的重要部分的集合。在[10]中,Nam和Tewfik提出了一种方法,其中局部采样率与视觉活动量成正比。Petrovic等人在[12]中使用学习方法来定义重要内容并相应地调整播放速度。当视频内容被认为不重要时,视频以更高的速度播放; 当帧被认为是重要的时,视频播放率下降。
2.2。关键帧选择
关键帧选择方法是基于识别序列中认为有意义重要的帧的算法。然后可以通过提取关键帧周围的子序列来构建视频摘要,然后将关键帧连接在一起。选择框架的方式需要为每个应用程序定义和调整。Oh等人[11]展示了几种进行这种选择的方法; 他们提出基于动作的选择,基于对象的选择或基于群集的选择。Gong和Liu [4]使用奇异值分解(SVD)来计算幻灯片视频摘要。在[8]中,Laganière等。使用时空兴趣点来识别视频的关键片段。关键帧选择不保留时间连续性,因此有时会丢失上下文信息。
2.3。帧重组
帧重组方法通过选择相关的时空片段并将它们组合成新的时空场景来构建视频摘要。不像前两种方法那样保留每个单独帧的完整性。Pritch等人已经发布了几种遵循这种方法的不同方法。在[15]中,他们通过同时显示几个动作来组合视频,即使它们最初发生在不同的时间。当物体运动太慢时,它们同时播放移动物体的多个动态实例。在[14]中,他们通过指向每个活动的原始时间在原始视频中添加索引。在线转换过程接收视频流并将其转换为对象和活动的数据库。最后,响应阶段基于用户的查询生成视频概要。在[13]中,他们将动作识别与视频摘要相结合,以应对这样一个事实:虽然有效,但同时显示多个活动可能会产生令人困惑的摘要。基于类似活动的聚类,提出了一种生成短视频和连贯视频摘要的新方法。聚类概要也适用于有效创建地面实况数据。最近,Huang等人在[5]中提出了通过将问题公式化为最大后验概率(MAP)估计问题来进行视频概要的方法。物体的位置和框架按时间顺序重新排列,而不需要知道它们的完整轨迹。MAP估计用于确定新检测到的前景对象的时间位置。
存在基于自适应版本的接缝雕刻、内容感知图像尺寸调整算法的其他方法。不是使用该算法进行空间缩减,而是使用它来获得时间缩减。在[9]中,李的等人提出带状雕刻,其中迭代地抑制连续的时空接缝并将广泛分离的动态事件组合在一起。当物体的速度变得太高或者当多个物体以不同的速度和(或)方向移动时,该方法具有一些限制。在[2]中,Décombas等人提出了解决这些问题的替代方案。他们首先定义可以被抑制的接缝和时空约束来限制,但不能消除可能出现的时间假象。
第3节 提议的方法
我们的方法基于帧重组,并遵循Pritch等人介绍的视频概要策略 [14] [13]。正如如[7]中所述一样,我们将帧尺寸为(X, Y)和长度为T的视频序列视为具有尺寸(X, Y,T)的“视频立方体”。为了在视频中稳健精确地提取相关的时空轨迹(第3.1节),我们结合了背景减法器[6]、密集光学流[3]和聚类算法。这些时空轨迹形成可被独立地操作,以产生通过最小化这些3D形状(第3.2节)之间的空间中而得到的短视频摘要时空tublets。。更确切地说,我们使用视频立方体平面上的tublet投影来压缩轨迹。这允许同时看到来自不同时间帧的多个对象。由于慢对象和静态对象可以通过减少其他对象的自由空间来增加视频摘要的长度,因此我们通过对每个轨迹应用自适应运动加速来重塑相应的长tublets(第 3.1.4 节)。时间标签可以被添加到每个对象中以突出显示原始时间表。图1说明了视频摘要构建过程。本节的其余部分将详细描述我们方法的每个组成部分。
3.1.建立时空轨迹
本小节详细介绍我们构建时空轨迹方法的主要步骤。首先,我们检测每个帧中的前景对象(第3.1.1节)。请注意,虽然静态对象的检测和处理是构建时空轨迹的一部分,但我们处理这类对象的方法在3.1.3节中描述。其次,我们通过滑动时间窗口将检测出来的每一个这些前景对象与连续帧关联起来(第3.1.2节)。最后,需要进行碰撞管理,以确保轨迹连贯且不被遮挡(第3.1.5节)。
3.1.1检测前景对象
我们使用背景减法[6],密集光流[3]和聚类算法的组合来检测和分割所有移动的前景物体。光流向量的聚类方法分离出在不同方向上移动的像素,而背景减法则在空间上分离像素。然后,这两者的组成一组表示前景对象检测的像素组。
为了使用稠密光流输出分离的像素,我们修改了一种称为引力聚类的通用数据聚类算法[1]。此算法中,输入一组n个d维数据点,最初将每个数据点作为一个单独的集群。随机选择两个点p_i和p_j,根据重力将它们靠近在一起。如果p_i和p_j在欧几里德阈值范围内,则认为它们在同一簇中。重复选择两个点并移近直到所有n个数据点都被选择。当所有n个数据点都已被移动时,则完成一次聚类算法迭代。经过k次迭代,提取最终的簇。我们修改算法以使用角距离而不是欧几里德距离来移动数据点,并确定是否应将两个数据点(在我们的例子中为像素)视为同一群集。在这种情况下,每个像素可以用极坐标(θ,m)来表示,其中θ是移动方向,m是移动幅度。将这些点绘制在以原点为中心的圆的周长上,两个点之间的角距离通过内积找到。可以将朝向彼此的移动点视为沿着圆的周边移动。
一旦我们从稠密光流的聚类中得到一组像素组,这些像素组进一步细分为背景减法的输出。由于背景减法可以为我们提供在空间上分离的像素组,它将划分一组在空间上都在相同的方向上移动的像素。最终的结果是一组像素组表示在当前帧中的运动的前景对象。
3.1.2前景对象关联
使用k帧的滑动时间窗口将连续帧中的检测对象彼此关联起来,从而为输入视频序列中的单个活动对象建立时空轨迹。一旦检测到的对象与来自具有移动物体的每个轨迹的最后已知检测相匹配(即:排除具有静态物体的轨迹)并且它们之间的像素重叠大于阈值,则进行关联。一旦轨迹不再具有与之滑动时间窗内相关联的任何活动对象检测,它被标记作进一步检查,以确定被跟踪对象是否已变为静态(参见第3.1.3节))或处于框架之外。在后一种情况下,如果轨迹长于给定数量的帧,则轨迹被标记为已完成。前一种情况用第3.1.3节中描述的方法来处理。
3.1.3管理静态对象
当前景对象在退出场景之前停止移动时,它们变为“静态对象”。也就是说,它们仍然是对摘重要但不移动的对象,因此我们在3.1.1节中检测前景对象的方法是不完善的。为了检测这些静态对象,用没有前景对象(静态或其他)的最后一帧来定义背景。如对象关联阶段(第3.1.2节)所述,没有与其相关联的其他前景对象的轨迹t似乎已成为静态对象或已退出场景。为了检测t是否已成为静态对象,我们在前景对象的最后已知位置的填充边界框与背景之间进行像素方面的差异比较。如果大量像素与背景像素不同,则将对象定义为静态。此外,该静态对象必须与轨迹t相关联,因为仅当不再有与轨迹匹配的任何新的活动前景对象时才执行该检查。对每个帧执行逐像素差异测试,直到对象移动到填充边界框之外,这是再次使用3.1.1节中的方法。
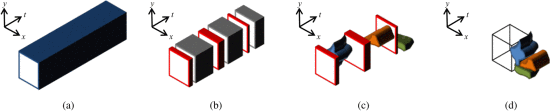
图.1.我们的视频摘要构造的插图。(a)作为3D结构的原始视频。(b)具有(灰色)和无(红色)活动像素的帧。(c)建造三个时空帷幔(蓝色,橙色和绿色)。(d)总结视频。
3.1.4加速轨迹
应用输出轨迹的自适应运动加速度以提高慢速移动物体的速度而不会损失很多清晰度。这是通过确定活动对象的平均速度来完成的。由于静态物体没有运动,因此通过每第N帧来加速它们。在我们的实验中,我们选择了N= 10。请注意,仅当只有静态对象可见时,快速转发才应用于框架,因为我们希望最大限度地减少清晰度的损失。因此,如果任何活动对象穿过静态对象,或者如果静态对象再次变为活动状态,则应当使用先前的加速方法。
3.1.5处理碰撞
在完整的时空轨迹集可以用作摘要算法的3D形状之前,需要考虑最后一个因素。当两个(或更多)对象进入场景,交叉路径或退出场景时,必须做出决定:将所有这些物体一起视为一个时空轨迹(即:合并这些物体)或将每个物体视为一个单独的时空轨迹。若选择前者作为后者来使用会导致被遮挡物体仅部分可见。此决定结果是在大时空轨迹中的场景的具有大量交叉的对象,因此摘要可能不是最佳的。从本质上讲,我们以可能更长的摘要为代价来交易改进的可视化和易于理解。
3.2。概要
在获得所有轨迹之后,我们基于它们在视频立方体平面(x ,y),(x ,t) 和 (y ,t)上的时空投影重新组合它们 。每个轨迹首先投射在(x ,y)平面上,并尽可能接近(x ,y)平面中已经集成的轨迹来投影。这允许来自不同时空位置的多个轨迹永远不会交叉(在空间和时间上)的物体同时出现。在不同时间帧遵循相似轨迹的多个对象在(x ,y)平面上产生碰撞。为了处理这些碰撞,我们将这些轨迹投射到(x ,t)平面上,然后尽可能接近时间(见图2)。(y , t)平面也是如此。这结果是来自不同时间帧的对象一个接一个地出现。可以在摘要中添加详细说明原始视频中对象的时间戳的文本信息,以帮助用户理解最终摘要。最后,可以通过不同的时间戳颜色识别加速的任何轨迹,以通知用户物体的加速已经发生。为了进一步减小视频摘要的长度,允许在对象的时空轨迹之间重叠。通过表示两个轨迹的投影之间允许的重叠百分比的阈值来控制精确的重叠量。
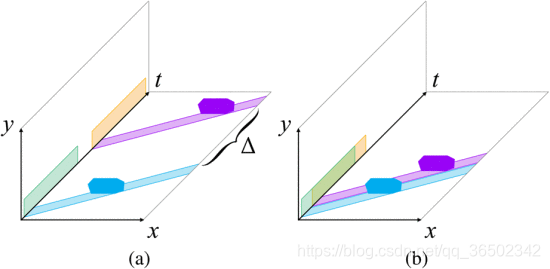
图.2.从物体轨迹的投影到 (x ,t ) 平面的时间减少。(a)具有两个物体的原始视频及其在(x ,t ) 和
(y,t)平面上的投影,其中 Δ作为时间距离。(b)通过收缩Δ得到的摘要
。
第4节 数据集和评估
视频摘要的客观评估是很困难的,因为摘要的质量本质上是主观的。本节介绍可用于估计摘要质量的新评估指标(第4.2节)。这些措施旨在评估给定视频摘要在监控视频中捕获相关活动的程度。在本文中,实验评估是在监测视频的数据集上进行的,其中添加了适当的地面实况注释(第4.1节)。
4.1。数据集
为了验证和比较我们的方法与传统方法的效率,引入了五个附有所有活动像素的手动创建的二元掩模2序列的数据库,以显示每个序列的原始序列的一个例子和 与它们相关的二进制掩码。表1总结了每个序列的基本信息(名称,尺寸,帧速率,总长度,前景对象的数量和存在的特征的简要描述)。
4.2。评估指标
我们将活动像素定义为重要的像素,因此它们应包含在视频摘要中。通过手动标记4.1节中描述的数据集来识别这些活动像素。下面列出了我们提出的指标及其衡量方法:
压缩率
这是视频长度相对于原始视频的减少量。它被定义为:
(1)
其中CR是压缩率,
是视频摘要中的帧数,
是原始视频中的帧数。 当视频摘要与原始视频具有完全相同的长度时,CR为零。
活动回忆
最终摘要中可见的活动像素的总百分比(相对于原始视频)。简单地计算每个轨迹中与地面实况活动像素相交的像素数量是不够的,因为在视频摘要中可能有重叠的轨迹(第3.2节)。因此,来自重叠轨迹的活动像素应该仅被计数一次,因为观看者不能同时看到两个(或更多个)重叠像素。这为我们提供了以下活动召回(AR)的定义:
(2)
其中P_retained是在汇总发生之前保留的活动像素数,
是与视频摘要中的其他活动像素重叠的活动像素数,
是地面实况中活动像素的总数。
这AR是从0到1范围取值,其中值为零意味着在视频摘要中没有找到来自地面实况的活动像素,而值为1则意味着在视频摘要中找到了来自地面实况的所有活动像素。
活动密度
将被填充活动像素的单个帧的平均百分比。例如,如果视频中所有像素的10%是活动像素,那么我们会认为,平均而言,任何给定帧应该有10%的像素是活动像素。视频摘要应该增加每帧的活动像素,因为我们正在删除不相关的帧并填充可能已经包含活动的其他帧中的空位置。我们将活动密度(AD)定义如下:
(3)
其中
定义为活动召回度量,W和H分别是视频的宽度和高度,L是帧数。
第5节 结果和讨论
在本节中,我们通过三个不同的视角展示我们的结果:(1)总结感知,(2)总结评估及(3)时空轨迹建立性能。在5.1节中,介绍和检查我们提出的方法产生的最终视频摘要的可视化。在第5.2节中,我们利用第4.2节中定义的评估度量来衡量我们提出的方法的表现。最后在5.3节中,我们研究了3.1节中定义的对象跟踪器的性能,该对象跟踪器用于构建时空轨迹。
5.1。总结感知
如第4节所述,视频摘要捕获和压缩信息的程度以及理解摘要中所有操作的简便性本质上都是主观的。虽然我们在4.2节中提出了一些减少主观性的指标,但如果不对我们提出的方法的结果进行一些主观讨论,最终结果的分析就不会完整。图4和5显示了两个序列的最终视频摘要中的单个帧。

图.3.我们数据集的缩略图。每列是一个完整的序列。顶行是序列中的单个帧,底部是来自相应手动二进制掩码的单个帧。
| ID | 序列名称 | 尺寸 | FPS | 时长 | 对象数量 | 描述性功能 |
| A | Cesta4[16] | 360×288 | 25 | 0:49 min | 12 | 沿着道路两个方向的线性水平移动 |
| B | Building | 480×270 | 24 | 4:20 min | 5 | 对象从视频帧的中心进入。运动是非线性的。 |
| C | BuildingStatic | 480×270 | 24 | 6:06 min | 16 | 与构建序列相同,添加了一个静态对象,其中有多个对象穿过它 |
| D | 公交专用道1 | 480×270 | 24 | 3:15 min | 14 | 沿着道路两个方向的对角线运动。背景包含一些微妙的运动。 |
| E | 公交专用道2 | 480×270 | 24 | 2:50 min | 16 | 与公交专用道1相同,添加重叠对象。 |
图4来自概括的建筑物序列,其中我们可以看到来自原始视频(顶行)中的不同时间位置的多个对象已经组合在一个帧(底行)中。图5显示了公交专用道2序列的两个不同视频摘要。在图5a中,允许轨迹重叠并且隐藏时间戳,而在图5b中,不允许轨迹重叠并且显示时间戳。在图5a中重叠轨迹导致一次播放所有车辆轨迹(总共14个)。从该示例可以清楚地看出,虽然允许重叠减少了视频摘要的最终长度,但是结果是不合要求的,因为摘要变得不可辨认理解的。虽然图5b中显示的对象少于图5a中的对象,但除了能够快速连续地分别看到每个对象之外,我们还可以在不损害理解的情况下可视化它们的时间戳。
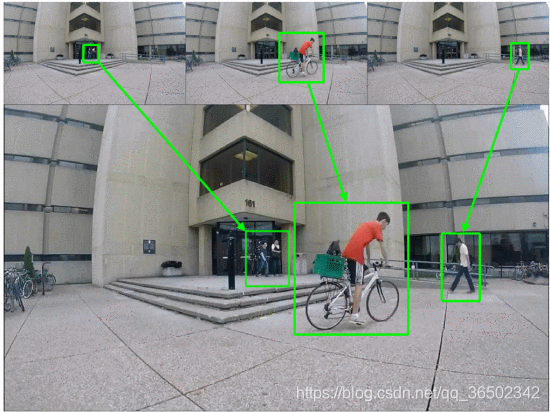
图.4.视频摘要中的单个帧(底行)和构建序列的摘要(顶行)中每个对象的原始帧
5.2。总结评估
我们提出的方法与三种不同的快速转发方法进行比较,这些方法将被表示为统一采样(UniSamp),非活动跳过(NAS)和具有非活动跳过的统一采样(UniSamp-NAS)。UniSamp只保留每第N帧, 对于我们的实验,我们设置N = 10。NAS会跳过对于摘要没有任何活动像素的所有帧。我们使用每个序列的基础真值二进制掩码确定哪些帧包含活动像素。UniSamp-NAS将NAS的结果作为UniSamp的输入,有效地结合了两种方法。应当注意的是,对于所有序列UniSamp,其中N = 10, 导致CR = 0:9且AR = 0:1,而NAS导致变量CR,同时具有AR = 1:0。因此,UniSamp-NAS将产生CR≥0:9,AR = 0:1。针对我们的方法的若干变体计算AR和CR值,并将图6中的快速转发方法的AR和CR值与AR-CR值一起可视化,作为AR-CR图。完整的数值评估结果可在附带的补充材料中找到。对于本节的其余部分,我们通过表1中定义的ID来引用序列。

图.5.来自公交专用道2两个不同视频摘要中的单帧。(a)重叠轨迹,没有时间戳。(b)没有重叠的轨迹和时间戳
从图6中我们可以看到,为了使任何视频摘要比传统的快速转发方法更有效,它必须具有由NAS和UniSamp-NAS方法定义的蓝线的上方的AR和CR值。如果摘要位于蓝线下方,那么这意味着我们可以选择蓝线上的最近点以获得UniSamp-NAS的变体,其可以产生改进AR和(或)CR的摘要。使用这一观察结果,我们发现放在蓝线上方和远离蓝线的摘要通常是最有效的。
加速移动物体的轨迹对序列B,D和E的影响可忽略不计,因为物体全部以大致相同的速度移动,而序列A和C具有明显的差异。由于序列C也有一个静态对象,因此产生三种不同的摘要:无加速度,仅静态对象加速度和静态对象加活动对象加速度。允许重叠对序列C没有影响,因为在构建时空轨迹期间合并了穿过静态对象的所有对象轨迹。
对于所有序列,当不允许轨迹重叠并且没有执行轨迹加速时,我们实现了AR> 0:97(图6中的绿色方块)。与UniSamp相比,我们的方法导致AR大幅增加,并且能够实现所有序列的CR> 0:7,除了具有CR≈0:01的C,因为静态物体几乎在整个持续时间内都可见的序列。如果我们允许加速静态物体,则CR跳跃到≈0:59,而AR下降到≈0:58(图6中的品红色正方形)。由于我们只在没有其他对象可见的情况下加速静态对象,因此在缺少活动方面几乎没有视觉差异。如果我们进一步允许穿越静态对象的活动对象被加速,我们实现了CR≈0:86和AR≈0:2(图6中的品红色菱形)。尽管AR大幅下降,但几乎没有视觉差异。
通过重叠轨迹增加CR可使AR的大幅下降,这会增加解释的难度(参见图5)。这在具有车辆的序列中尤其明显,因为它们都沿着道路的方向移动,仅在不同的时间。因此,通过重叠若干轨迹,结果是具有在相同时间彼此重叠的几个或所有车辆轨迹的概要。例如,在序列D和E中,允许轨迹重叠有效地减少了在AR-CR性能方面对UniSamp-NAS的摘要(见图6),另外还有理解上的困难(参见图5)。将其与使用下降非常小的AR来增加重叠CR的序列B进行比较,这是更可接受的权衡。
根据AD度量以及对原始视频序列和摘要中内容的观察,我们发现允许重叠轨迹的摘要相对于原始视频的AD具有显着的AD增加。大幅增加意味着每帧打包更多活动像素,因此发生的重叠量必须与额外AD的量成比例。例如,在序列E中,当轨迹重叠时,我们看到AD从0:08增加到0:17。在图5a中可以看到AD的附加0:09的结果,其大于没有重叠的概括视频的AD。。由于所有车辆轨迹彼此重叠,因此难以理解该概要。图5a中的问题在序列D中更加明显,我们观察到当轨迹允许重叠时,AD增加超过0:50。
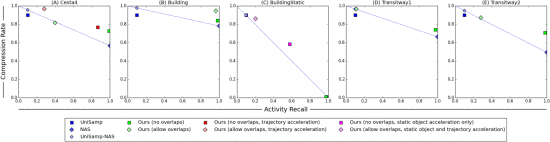
图.6.每个序列的AR-CR图。在NAS和UniSamp-NAS方法之间绘制一条蓝线,代表不同的摘要,以及它们落入AR-CR图的位置,可以通过改变UniSamp-NAS的N参数来产生。
| 序列名称 | 真阳性(TP) | 假阳性(FP) | 真阴性(TN) | 假阴性(FN) | ||||
| GT | Ours | GT | Ours | GT | Ours | GT | Ours | |
| Cesta4 | 2,412 | 2.395 | 0.000 | 4.114 | 97.588 | 93.474 | 0.000 | 0.017 |
| Building | 0.118 | 0.116 | 0.000 | 0.314 | 99.882 | 99.568 | 0.000 | 0.002 |
| BuildingStatic | 0.395 | 0.385 | 0.000 | 2.289 | 99.605 | 97.319 | 0.000 | 0.009 |
| 公交专用道1 | 2.061 | 2.015 | 0.000 | 2.645 | 97.939 | 95.294 | 0.000 | 0.046 |
| 公交专用道2 | 2.216 | 2.183 | 0.000 | 2,762 | 97.784 | 97.784 | 0.000 | 0.033 |
表2. 真/假阳性和真/假阴性表示为地面实况(GT)和我们的时空轨迹的构建方法的每个序列中的总像素的百分比
5.3。时空轨迹建筑性能评估
为了测量我们的时空轨迹构建方法(第3.1节)的性能,我们检查了真实阳性(TP),假阳性(FP),真阴性(TN)和假阴性(FN)的像素数量。每个视频序列的基本真实二进制掩码。TP是由我们的轨迹和地面实况标记为活动像素的像素,而FP是我们轨迹中的活动像素,但不是地面实况。对于未被我们的轨迹标记为活动像素的像素,TN和FN被类似地定义。我们建立时空轨迹的方法能够保留97%的地面实况活动像素。表2总结了该评估的结果。
虽然理想情况下时空轨迹与基本事实完全相同,但在视频概要的情况下,最小化FN更为重要,因为它们不会包含在最终视频摘要中。这意味着FN的量越大,保留的活动越低,这导致理解难度增加,因为在时空轨迹中将丢失对象的部分。从表2中我们可以看出,对于我们数据集中的任何给定序列,我们的方法产生低于4.2%FP和0.05%FN。因此,虽然我们的时空轨迹构建方法确实产生了更大量的FP,但它也产生非常少的FN,因此在我们的视频摘要中很少看到部分对象或破碎的轨迹。
第6节 结论
在本文中,我们详细介绍了基于帧重组策略的视频摘要方法。我们提供了一个专为视频摘要设计的对象跟踪器,在我们的实验中,它可以提取保留原始视频中97%以上活动的时空轨迹。此外,我们提供基准数据集,包括手动构建的二进制掩码,用于视频摘要以及建议的评估指标,以便根据压缩率(CR),活性召回(AR)和活动密度(AD)来量化摘要视频的性能。我们提出的策略是使用我们的数据集对标准快速转发方法进行基准测试,我们发现我们的摘要算法是通过提供压缩率和召回活动之间的良好折衷来执行这些方法。
参考
[1] D. Dasguptal. A new gravitational clustering algorithm. In Proceedings of the Third SIAM International Conference onData Mining, volume 112, page 83. SIAM, 2003. 3
[2] M. Decombas, F. Dufaux, and B. Pesquet-Popescu. Spatiotemporal grouping with constraint for seam carving in video summary application. In Digital Signal Processing (DSP),2013 18th International Conference on, pages 1–8. IEEE,2013. 2
[3] G. Farneback. Two-frame motion estimation based on poly- ¨nomial expansion. In Image Analysis, pages 363–370.Springer, 2003. 3
[4] Y. Gong and X. Liu. Video summarization using singular value decomposition. In Computer Vision and PatternRecognition, 2000. Proceedings. IEEE Conference on, volume 2, pages 174–180. IEEE, 2000. 2
[5] C.-R. Huang, P.-C. J. Chung, D.-K. Yang, H.-C. Chen, and G.-J. Huang. Maximum a posteriori probability estimationfor online surveillance video synopsis. Circuits and Systems for Video Technology, IEEE Transactions on, 24(8):1417–1429, 2014. 2
[6] P. KaewTraKulPong and R. Bowden. An improved adaptive background mixture model for real-time tracking with shadow detection. In Video-based surveillance systems,pages 135–144. Springer, 2002. 2, 3
[7] C. Keimel, M. Rothbucher, H. Shen, and K. Diepold. Video is a cube. Signal Processing Magazine, IEEE, 28(6):41–49,2011. 1, 2
[8] R. Laganiere, R. Bacco, A. Hocevar, P. Lambert, G. Pa ` ¨ıs, and B. E. Ionescu. Video summarization from spatio-temporal features. In Proceedings of the 2nd ACM TRECVid Video Summarization Workshop, pages 144–148. ACM, 2008. 2
[9] Z. Li, P. Ishwar, and J. Konrad. Video condensation by ribbon carving. Image Processing, IEEE Transactions on,18(11):2572–2583, 2009. 2
[10] J. Nam and A. H. Tewfik. Video abstract of video. In Multimedia Signal Processing, 1999 IEEE 3rd Workshop on, pages 117–122. IEEE, 1999. 2
[11] J. Oh, Q. Wen, S. Hwang, and J. Lee. Video abstraction.Video data management and information retrieval, pages 321–346. 2
[12] N. Petrovic, N. Jojic, and T. S. Huang. Adaptive video fast forward. Multimedia Tools and Applications, 26(3):327–344, 2005. 2
[13] Y. Pritch, S. Ratovitch, A. Hende, and S. Peleg. Clustered synopsis of surveillance video. In Advanced Video and Signal Based Surveillance, 2009. AVSS’09. Sixth IEEE International Conference on, pages 195–200. IEEE, 2009. 2
[14] Y. Pritch, A. Rav-Acha, and S. Peleg. Nonchronological video synopsis and indexing. Pattern Analysis and
Machine Intelligence, IEEE Transactions on, 30(11):1971–1984, 2008. 2
[15] A. Rav-Acha, Y. Pritch, and S. Peleg. Making a long video short: Dynamic video synopsis. In Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on, volume 1, pages 435–441. IEEE, 2006. 2
[16] R. Vezzani and R. Cucchiara. Video surveillance online repository (visor): an integrated framework. Multimedia Tools and Applications, 50(2):359–380, 2010. 6
[17] M. M. Yeung and B.-L. Yeo. Video visualization for compact presentation and fast browsing of pictorial content. Circuits and Systems for Video Technology, IEEE Transactions on, 7(5):771–785, 1997. 2