硬件相关==========================================
nandflash和norflash的区别,对norflash的操作方式的理解
NAND Flash:
优点:以页为单位存取,在容量,使用寿命和成本上有较大优势。
缺点:读出速度慢,编程较为复杂,必须采用专用的I/O控制器,需要对介质进行初始化扫描以发现坏块,并将坏块标记为不可用。
应用:大多作为数据存储器使用,如:U盘
Nor Flash:
优点:以字节为单位存取,应用程序可以直接在Nor Flash中执行,读写接口简单,可直接连接到处理器的外围总线上。
缺点:写入和擦除慢。
应用:大多作为代码存储器使用。
两种芯片的结构不同 NORflash之所以可以片内执行,就是因为他符合CPU去指令译码执行的要求。CPU送一个地址出来,NORflash就能给一个数据让CPU执行,中间不需要额外的处理操作。
NAND flash不一样是因为nandflash有地址,数据,命令共用IO口的问题,cpu把地址发出来之后,并不能直接得到数据,还需要控制线的操作才能完成。就是他没有专用的SRAM接口。
uboot相关==========================================
uboot启动过程都做了些什么?
扫描二维码关注公众号,回复: 6193592 查看本文章
上电自检,硬件初始化,建立存储空间映射,配置系统参数,建立上层软件的运行环境,加载和启动操作系统。
为什么uboot要关掉cache?
答: 根据cache的定位可以看出来,它是用来加快cpu从内存中取出指令的速度,但我们都知道,在设备上电之初,我们的内存初始化比较慢一拍,当cpu初始化了,但内存还没准备好之后,就对内存进行数据读,那么势必会造成了指令取址异常,系统就会挂了。所以,在u-boot的上电之初,就得关闭掉数据cache,指令的cache关闭与不关闭没有太大的关系。
注:Dcache只能在MMU开启之后使用,因为没有MMU就没法完成虚实地址映射,也就不能索引Dcache了。
uboot怎么传参给内核的
答: 简单的讲,uboot利用函数指针及传参规范,它将
R0: 0x0
R1: 机器号
R2: 参数地址
三个参数传递给内核。
其中,R2寄存器传递的是一个指针,这个指针指向一个TAG区域。
Linux相关==========================================
linux怎么进行内存管理
早期计算机中,由于应用程序比较小,可以直接在物理内存中运行,但现在计算机里面程序那么多又那么大,所以就需要对内存进行管理。
1、对内存的分配和管理,也就是平时应用层malloc和内核层vmalloc、kmalloc之类的内存申请的管理。
2、虚拟内存和物理内存之间的转换。
说说进程和线程的区别
简单的来说,一个程序至少有一个进程,一个进程至少有一个线程。
第一点、进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
但这样带来的缺点就是,多线程程序只要有一个线程挂掉了,那么整个进程也就挂掉了,而进程则不会影响另外一个进程,它有自己的独立地址空间。
第二点、线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。
进程间通信都有些什么?
答:
1、无名管道通信
内核维护一块内存,有读端和写端。只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2、有名管道通信
内核维护一块内存,表现形式为一个有名字的文件。传输方式:半双工
3、消息队列通信
4、信号
5、信号量通信
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
6、共享内存通信
7、套接字通信
套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
对内核各种锁的了解
内核锁
1、原子操作(atomic):
2、自旋锁(spinlock/spinlock_irqsave):
3、读写自旋锁(rwlock):
4、顺序自旋锁(seqlock):
5、RCU(读-拷贝-更新):
6、信号量(semaphore):
7、读写信号量:
创建一个文件的时候,会创建一个怎么样的节点。
答:一个文件被创建后至少要占用一个inode和一个block
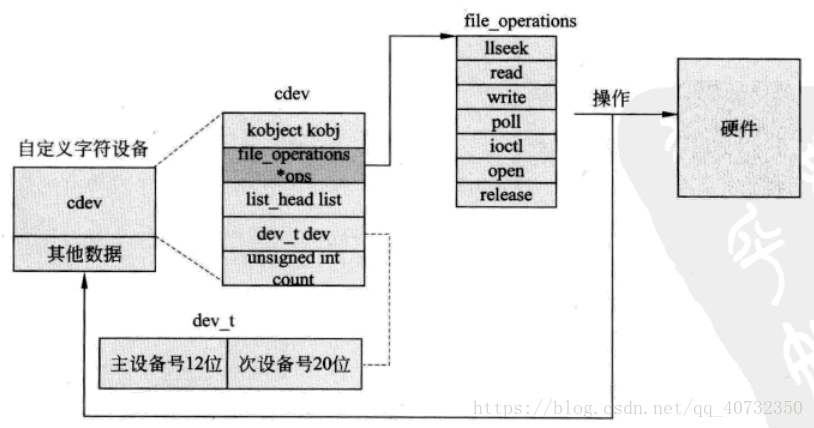
在应用层调用一个read,是怎么传到内核中去的,流程是啥。
第一:一个文件,不管是符号链接还是硬链接,都对应一个inod

第二:一个inod又对应一个驱动设备(这里以字符设备为例)

第三:通过设备cdev找到相应的file_operations,再找到相应的驱动中的read函数指针。
但是如果用的是驱动模型就是下面的情况:但是大的方向都是一样的。

驱动相关==========================================
特殊属性声明
GNU C 允许声明函数、变量和类型的特殊属性,以便手动优化代码和定制代码检查的方法。要指定一个声明的属性,只需要在声明后添加 _ _attribute_ _ (( ATTRIBUTE ))。其中 ATTRIBUTE 为属性说明,如果存在多个属性,则以逗号分隔。 GNU C 支持 noreturn、
format、 section、 aligned、 packed 等十多个属性。
noreturn 属性作用于函数,表示该函数从不返回。这会让编译器优化代码,并消除不必
要的警告信息。例如:
# def ine ATTRIB_NORET _ _attribute_ _((noreturn)) ....
asmlinkage NORET_TYPE void do_exit(long error_code) ATTRIB_NORET;字节对齐:
struct example_struct {
char a;
int b;
long c;
}_ _attribute_ _((packed));设备驱动模型三大组件

总结:
不管是平台总线还是IIC总线都都有这样的调用路线:
当系统发现了新设备或者新驱动就会掉用相应总线的Match()进行匹配,当找到后就会掉用相对应的总线的Probe函数,最后Probe函数再调用驱动自己的Probe函数
虽然平台总线和IIC总线的实现有些不同,但是大体使一样的
如下:
//platform 总线
int platform_driver_register(struct platform_driver *drv)
{
if (drv->probe)
drv->driver.probe = platform_drv_probe;
return driver_register(&drv->driver);
}
static int platform_drv_probe(struct device *_dev)
{
struct platform_driver *drv = to_platform_driver(_dev->driver);
struct platform_device *dev = to_platform_device(_dev);
return drv->probe(dev);
}
// IIC总线
static int i2c_device_probe(struct device *dev)
{
status = driver->probe(client, i2c_match_id(driver->id_table, client));
}