目录
18、链表是我们经常要操作的数据结构,现在给你一个单链表的链表头,实现链表的排序,说出具体过程
19、假设时钟频率128MHz,那么1us可以运行多少条指令
1、烧焦检测算法实现?
烧焦实际上肉眼就能发现,然后实际上我们做的工作主要是返回烧焦原因并推荐5/10组参数给用户。根据从经验师傅那里得到的经验来设计程序
激光器烧焦原因:功率过高、频率、脉宽
2、视频实时传输用的什么通信协议?
http通讯协议,mjpg-streamer 可以通过文件或者是HTTP方式访问linux UVC兼容摄像头
wifi:获取端口号和ip地址,获取wifi服务,创建http客户端:HttpURLConnection 和 Apache HTTP。
数据处理通过socket实现:
就是两个进程,跨计算机,他俩需要通讯的话,需要通过网络对接起来。
这就是 socket 的作用。打个比方吧,两个进程在两个计算机上,需要有一个进程做被动方,叫做服务器。另一个做主动方,叫做客户端。他们位于某个计算机上,叫做主机 host ,在网络上有自己的 ip 地址。一个计算机上可以有多个进程作为服务器,但是 ip 每个机器只有一个,所以通过不同的 port 数字加以区分。
因此,服务器程序需要绑定在本机的某个端口号上。客户端需要声明自己连接哪个地址的那个端口。两个进程通过网络建立起通讯渠道,然后就可以通过 recv send 来收发一些信息,完成通讯。
所以 socket 就是指代承载这种通讯的系统资源的标识。
https://blog.csdn.net/bailang_zhizun/article/details/78327974
3、sizeof/strlen
sizeof
a---数组名单独出现,代表整个数组。int a[5] = {1,2,3,4};printf("%d\n",sizeof(a));//20
&a—表示的是整个数组的地址(地址的大小为4,单位为字节。)printf("%d\n",sizeof(a+0));//4 printf("%d\n",sizeof(&a+1));//4
解引用 *&a---代表整个数组的内容printf("%d\n",sizeof(*&a));//20,*&a---代表整个数组的内容,所以为5*4
strlen
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", strlen(arr));//随机值
因为在此数组中没有’ \0 ’,函数无法知道在哪里停下来。printf("%d\n",strlen(&arr+1));//随机值-6.但&数组名加上其他操作符—代表整个数组的地址。再接着执行。跳过整个数组,所以大小差6.
char arr[] = "abcdef";
printf("%d\n", strlen(arr));//6
printf("%d\n", strlen(arr+0));//6
二维数组
int a[3][4] = {0};
printf("%d\n",sizeof(a));//48 a---数组名单独出现,代表整个数组。一共有12个元素,每个元素为4字节。12*4
printf("%d\n",sizeof(*a));//16二维数组降级变为一维数组,成为第一行。所以第一行内容的大小为4*4
printf("%d\n",sizeof(a[3]));//16表示第三行的数组长度,元素个数为4,4*4
4、PID算法
横滚角、俯仰角和偏航角
PID经常用于保持环境的稳定,一般它通过关注3种误差和设置3个可调参数最后进行加权求和作为输出,3个误差分别是当前误差、历史误差和近期误差,当前误差用于大幅度的调控,历史误差用于累积收敛,近期误差用于调控整体趋势,再用3个可调参数分别相乘再相加,也就是加权求和,就可以作为控制的输出
5、RW区和ZI区

全局区的初始化区和未初始化区

Code是程序代码所占的字节,即代码区;
RO-data 代表只读数据,程序中所定义的常量数据和字符串等都位于此处,即常量区;
RW-data 代表已初始化的读写数据,程序中定义并且初始化的全局变量和静态变量位于此处,一部分静态区(全局区);
ZI-data 代表未初始化的读写数据,程序中定义了但没有初始化的全局变量和静态变量位于此处,另一部分的静态区(全局区)。ZI英语是zero initial,就是程序中用到的变量并且被系统初始化为0的变量的字节数,keil编译器默认是把你没有初始化的变量都赋值一个0,这些变量在程序运行时是保存在RAM中的。
5、New/delete和malloc/free
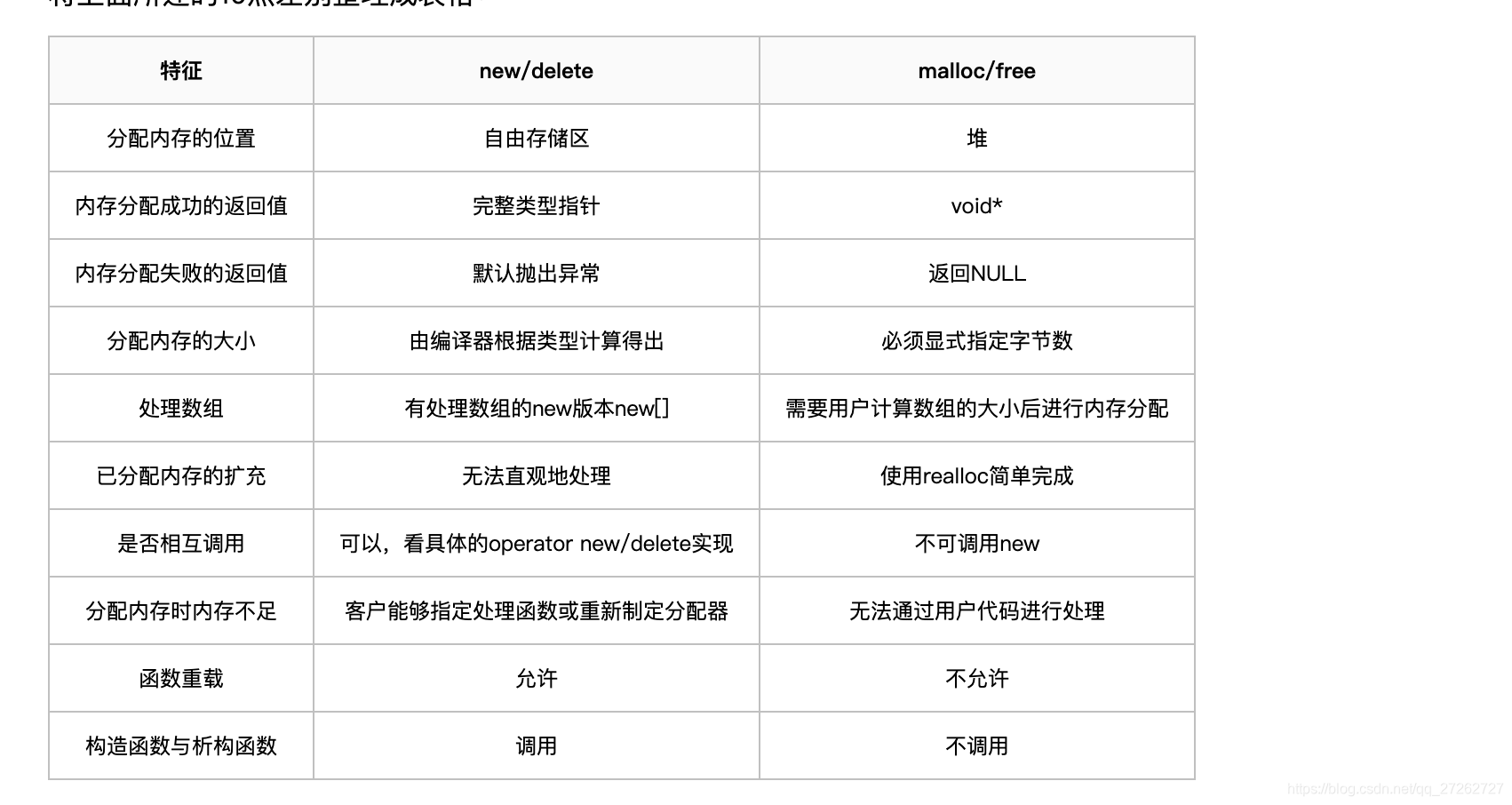
指针左移64位:(char *)ptr -= 64;
6、什么叫波特率?和比特率有什么区别?
波特率是传输一个码元的时间,而比特率是传输一个二进制位的时间,区别在于,一个码元不一定是一个二进制位(虽然经常都是),比如当传输的状态有4种的时候,需要2个二进制位表示全部状态,此时发送一个状态为一个码元,一个码元其实就是2个二进制位,此时波特率是比特率的两倍,一个通用的公式是比特率=波特率*一个码元对应的二进制位数
7、PWM有占空比的概念,讲一讲占空比
占空比就是在一个脉冲宽度中,通电时间或者高电平时间所占的比例
8、单片机怎么实现占空比
可以用定时功能实现,设置好脉冲宽度和占空比后,计算定时的溢出时间,这段时间就作为高电平的输出时间,其余时间输出低电平
9、怎么实现定时功能
单片机都会有定时器,用定时器和中断就可以了
10、讲一讲中断的概念
中断是用于处理紧急事件的,系统只要预先设置好中断源、中断触发方式、中断服务函数、中断屏蔽位等等就可以使用中断了,当中断源满足中断条件的时候就会触发中断,此时CPU会停止当前工作,然后保护现场,接着跳转到中断服务函数执行,最后恢复现场
11、中断触发方式有哪些
外部中断一般是上升沿、下降沿或者两者都触发,而内部中断是由程序行为触发的,比如未定义行为像数组越界、除数是0等等
12、堆和栈的区别
首先是管理方式不同,堆由程序员负责申请和释放,栈是编译器负责的,然后是结构不同,堆是一种从底部往顶部扩展的结构,栈是从顶部到底部刚好相反的结构,最后是效率有很大的不同,堆的申请和释放都需要经过算法计算,因为要减少内存碎片和提高内存使用率,而栈由编辑器负责,速度非常快,在这点上堆的效率比较低
13、堆和栈使用上有什么区别
因为栈是编译器负责的,所以程序员只需要在函数内部定义变量直接使用,堆是程序员负责的,申请的时候会在内存开辟一块匿名区域,然后返回地址,必须使用指针去访问,所以访问堆都是通过传递指针的方式,最后需要程序员去释放堆空间
14、两个函数怎么共享资源
可以用全局变量,不够由于没有约束,会使得函数变得不可重入,也可以使用指针,以参数的形式传递一个指针,就可以共享指针所指向的资源
15、const和define的区别,分别在什么情况下使用
在编译器的角度下,const其实给出了地址,而define给出了立即数,然后const是有类型的,表达式运算的时候会进行类型安全检查,而define没有,最后const只在第一次使用的时候访问内存,往后的使用都是访问符号表,define则是普通的字符串替换,具有多个副本。
const一般用于函数的参数保护,以免函数内部不小心修改了只读变量,define其实比较自由,按照Linux的风格,define是有崇高的地位,很多短小精悍的功能都由define完成,如果就定义常量而言,const和define都可以,不过我个人认为const定义的常量比define要高效
16、平时的编程环境
如果是51或者Arduino或者STM的话,因为都有丰富的集成开发环境IDE,所以直接在PC编程烧录,如果是ARM的开发,我一般是PC上用sourceinsight编程,然后进入虚拟机Linux编译调试,再通过NFS连接ARM的板载Linux传输数据进行驱动安装
17、代码管理方式
因为代码量都不是很大,不太需要github来管理,所以都是直接保存PC本地,调试的时候直接修改源代码,编译烧录整个过程重复一遍
18、链表是我们经常要操作的数据结构,现在给你一个单链表的链表头,实现链表的排序,说出具体过程
https://www.cnblogs.com/tenosdoit/p/3666585.html
19、假设时钟频率128MHz,那么1us可以运行多少条指令
时钟周期:时钟周期也称为振荡周期,定义为时钟脉冲的倒数(时钟周期就是单片机外接晶振的倒数,例如12M的晶振,它的时钟周期就是1/12us),是计算机中的最基本的、最小的时间单位。在一个时钟周期内,CPU仅完成一个最基本的动作。时钟脉冲是计算机的基本工作脉冲,控制着计算机的工作节奏。时钟频率越高,工作速度就越快。8051单片机把一个时钟周期定义为一个节拍(用P表示),二个节拍定义为一个状态周期(用S表示)。
机器周期:计算机中,常把一条指令的执行过程划分为若干个阶段,每一个阶段完成一项工作。每一项工作称为一个基本操作,完成一个基本操作所需要的时间称为机器周期。8051系列单片机的一个机器周期由6个S周期(状态周期)组成。 一个S周期=2个节拍(P),所以8051单片机的一个机器周期=6个状态周期=12个时钟周期。例如外接24M晶振的单片机,他的一个机器周期=12/24M 秒;
指令周期:执行一条指令所需要的时间,一般由若干个机器周期组成。指令不同,所需的机器周期也不同。
20、volatile的作用
编译器优化常用的方法有:将内存变量缓存到寄存器;调整指令顺序充分利用CPU。
volatile的本意是“易变的” 因为访问寄存器要比访问内存单元快的多,所以编译器一般都会作减少存取内存的优化,但有可能会读脏数据(脏数据就是在物理上临时存在过,但在逻辑上不存在的数据)。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问;如果不使用valatile,则编译器将对所声明的语句进行优化。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错)
21、static关键字
静态局部变量使用static修饰符定义,即使在声明时未赋初值,编译器也会把它初始化为0。且静态局部变量存储于进程的全局数据区,即使函数返回,它的值也会保持不变。
全局变量定义在函数体外部,在全局数据区分配存储空间,且编译器会自动对其初始化。普通全局变量对整个工程可见,其他文件可以使用extern外部声明后直接使用。也就是说其他文件不能再定义一个与其相同名字的变量了(否则编译器会认为它们是同一个变量)。静态全局变量仅对当前文件可见,其他文件不可访问,其他文件可以定义与其同名的变量,两者互不影响。在定义不需要与其他文件共享的全局变量时,加上static关键字能够有效地降低程序模块之间的耦合,避免不同文件同名变量的冲突,且不会误使用。
函数的使用方式与全局变量类似,在函数的返回类型前加上static,就是静态函数。其特性有:静态函数只能在声明它的文件中可见,其他文件不能引用该函数不同的文件可以使用相同名字的静态函数,互不影响。非静态函数可以在另一个文件中直接引用,甚至不必使用extern声明
22、指针和引用的区别
对象是指一块能存储数据并具有某种类型的内存空间,一个对象a,它有值和地址&a,运行程序时,计算机会为该对象分配存储空间,来存储该对象的值,我们通过该对象的地址,来访问存储空间中的值
指针p也是对象,它同样有地址&p和存储的值p,只不过,p存储的数据类型是数据的地址。如果我们要以p中存储的数据为地址,来访问对象的值,则要在p前加解引用操作符"*",即*p。
对象有常量(const)和变量之分,既然指针本身是对象,那么指针所存储的地址也有常量和变量之分,指针常量是指,指针这个对象所存储的地址是不可以改变的,而指向常量的指针的意思是,不能通过该指针来改变这个指针所指向的对象。
引用可以理解成变量的别名。定义一个引用的时候,程序把该引用和它的初始值绑定在一起,而不是拷贝它。计算机必须在声明r的同时就要对它初始化,并且,r一经声明,就不可以再和其它对象绑定在一起了。引用的一个优点是它一定不为空,因此相对于指针,它不用检查它所指对象是否为空,这增加了效率。
23、C++多态的实现方式
1、覆盖
覆盖是指子类重新定义父类的虚函数的做法。当子类重新定义了父类的虚函数后,父类指针根据赋值给它的不同的子类指针,动态的调用属于子类的该函数,这样函数调用在编译期间是无法确定的,这样的函数地址在运行期间绑定称为动态联编。
2、重载
重载是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数。
24、C++内存分配(堆、栈、静态存储区)
栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。
堆,就是那些由 new 分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个 new 就要对应一个 delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。堆可以动态地扩展和收缩。
自由存储区,就是那些由 malloc 等分配的内存块,他和堆是十分相似的,不过它是用 free 来结束自己的生命的。
全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的 C 语言中,全局变量又分为初始化的和未初始化的(初始化的全局变量和静态变量在一块区域,未初始化的全局变量与静态变量在相邻的另一块区域,同时未被初始化的对象存储区可以通过 void* 来访问和操纵,程序结束后由系统自行释放),在 C++ 里面没有这个区分了,他们共同占用同一块内存区。
常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改,而且方法很多
25、平衡二叉树的实现原理
平衡二叉树引入了平衡因子BF(Balance Factor),根据平衡因子可以构造平衡二叉树以及判断该二叉树是否一棵平衡二叉树!BF的定义:二叉树上的结点上的左子树的深度值与右子树的深度值之差,如果绝对值小于等于1,表示该树是平衡二叉树!
26、线程和进程的区别
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
1) 简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
2) 线程的划分尺度小于进程,使得多线程程序的并发性高。
3) 另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
4) 线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
5) 从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
27、进程之间相互通信的方式
1. 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2. 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
4. 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5. 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
6. 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
7. 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
8. 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
28、网络IO模式(select、epoll)
I/O 多路复用( IO multiplexing):select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);不同与select使用三个位图来表示三个fdset的方式,poll使用一个 pollfd的指针实现。
struct pollfd { int fd; /* file descriptor */ short events; /* requested events to watch */ short revents; /* returned events witnessed */};pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时,pollfd并没有最大数量限制(但是数量过大后性能也是会下降)。 和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
29、Linux的进程调度(优先级、时间片轮转调度)
1、先来先服务调度算法
先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入就绪队列。在进程调度中采用FCFS算法时,则每次调度是从就绪队列中选择一个最先进入该队列的进程,为之分配处理机,使之投入运行。该进程一直运行到完成或发生某事件而阻塞后才放弃处理机。
2、短作业(进程)优先调度算法
短作业(进程)优先调度算法,是指对短作业或短进程优先调度的算法。它们可以分别用于作业调度和进程调度。短作业优先(SJF)的调度算法是从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行。而短进程优先(SPF)调度算法则是从就绪队列中选出一个估计运行时间最短的进程,将处理机分配给它,使它立即执行并一直执行到完成,或发生某事件而被阻塞放弃处理机时再重新调度。
3、时间片轮转法
在早期的时间片轮转法中,系统将所有的就绪进程按先来先服务的原则排成一个队列,每次调度时,把CPU分配给队首进程,并令其执行一个时间片。时间片的大小从几ms到几百ms。当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便据此信号来停止该进程的执行,并将它送往就绪队列的末尾;然后,再把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。这样就可以保证就绪队列中的所有进程在一给定的时间内均能获得一时间片的处理机执行时间。换言之,系统能在给定的时间内响应所有用户的请求。
30、交叉编译
交叉编译是在一个平台上生成另一个平台上的可执行代码
常用:gcc
