在这篇文章里,我们沿大数据发展时间线,从产品、行业、技术多角度讨论其发展脉络,究其发展承其脉络大家可以学习、借鉴、并最终推测未来大致走向。

社区
Hadoop:开源大数据的基石
Hadoop 于 2005 年问世。之前,Doug Cutting 和 Mike Cafarella 已经拜读过 Google 的 GFS 论文,并且自己“手工造轮子”实现自己的 Google 分布式文件系统(最初称为 Nutch 分布式文件系统的 NDFS,后来改名为 HDFS 或 Hadoop 分布式文件系统)。在 2004 年时候,Google 发表神作《MapReduce: Simplified Data Processing on Large Clusters》,上述两位正在构架开源搜索引擎的大牛在考虑构建 Nutch webcrawler 的分布式版本正好需要这套分布式理论基础。因此,上述两位社区大牛基于 HDFS 之上添加 MapReduce 计算层。他们称 MapReduce 这一层为 Hadoop,由于 Hadoop 核心原理均是基于上述两篇论文,即 MapReduce 以及 GFS,其本身在技术理论上并无创新,更多是“山寨”实现。对于技术原理感兴趣的看官可自行阅读 Google 原作立刻了解各自原理,而对于 Hadoop 发展历史感兴趣的可以推荐阅读下 Marko Bonaci 的《The history of Hadoop》。

Hadoop 技术相比于 Google 原作并无新意,甚至在 GFS 系统细节方面折扣实现不少。但笔者在此并无讨论技术差异点的打算,我仍然回到老本行,从产品或者市场角度去探讨 Hadoop 成功因素以及给我们的启示。
在笔者看来,Hadoop 体系能够成功,并在数据处理市场占据一席之地,其初期核心因素就在于以下几点:
时机。彼时互联网 Web 2.0 风头正紧,大量用户与网站交互行为爆炸式增长,如何使用廉价的服务器(大量互联网创业公司就是穷鬼,买不起大小型机)去分析各类网站数据的业务需求已经迫在眉睫。此时,大量 Top 互联网公司有数据、有需求、有硬件,就缺一个廉价的数据分析系统。于是乎,开源、免费的 Hadoop 工具正好钻入此类大数据市场空档,迅速占领了核心种子客户群体,并为后续市场推广奠定了群众基础。
开源。开源在开发者社区感染力不容小觑。Cutting 和 Cafarella 通过开源(以及 HDFS 的源代码)确保 Hadoop 的源代码与世界各地可以共享,最终成为 Apache Hadoop 项目的一部分。Google 此时并未意识到开放论文仅仅自我精神爽了一次:让尔等看看我等技术影响力;实际上并未从长远去思考大数据技术影响力构建以及更加长远的云计算商业生态构建。互联网时代下,大量软件被开发者以及背后的互联网商业公司作为开源系统贡献出来,整个互联网开发者行业已经被开源社区完全洗脑,仿佛开源就是人类灯塔,闭源就是万恶不赦。于是,此时,一个开源的、免费的、感觉挺符合互联网精髓的大数据处理软件出现在各大互联网公司圈中,迅速在互联网大数据处理领域触达了这部分市场群体。
商业。早年开源软件皆靠诸位开源运动人士在业界做社区用户推广,这波人本身毫无金钱汇报全靠一腔精神热血。但本质上来说,人类以及人类社会都是趋利性的,没有利益驱动的市场行为终究无法持续。因此,早期没有找到合适盈利模式的开源软件一直发展缓慢,靠类似 Richard Stallman 类似开源***斗士去做市场推广,市场效率之低下。后期,在 Linux 商业公司红帽逐步摸索出开源软件变现模式后,其他开源软件也纷纷仿效。Hadoop 一时间背后迅速成立三家公司,包括 Cloudera、HotonWorks、MapR,这些公司盈利潜力完全都依赖于 Hadoop 开源生态的规模,因此,三家公司都会尽不遗余力地推进 Hadoop 生态发展,反过来促进了 Hadoop 整个生态用户的部署采用率。到大数据市场更后期的时代,其商业竞争更趋激烈。以 Kafka、Spark、Flink 等开源大数据软件为例,在各自软件提交到 Apache 基金会之时创始人立刻创办商业公司,依靠商业推进开源生态建设,同时通过收割生态最终反哺商业营收。
最终 Hadoop 在生态建设上获得了巨大的成功,其影响力在开源业界开创了一个崭新领域:大数据处理可见一斑。我们从如下几个维度来看看 Hadoop 生态成功的各类体现:

Hadoop 的技术生态
不得不承认,Hadoop 有技术基座的先天优势,特别类似 HDFS 的存储系统。后续各大 Hadoop 生态圈中的大数据开源软件都多多少少基于 Hadoop 构建的技术底座。故而,大量大数据生态后起之秀基本均源于 Hadoop,或者利用 Hadoop 作为其基础设施,或者使用 Hadoop 作为上下游工具。此类依存共生关系在整个 Hadoop 社区生态已蔚然成风,越多大数据开源系统加入此生态既收割现有大数据生态客户流量,同时亦添加新功能进入 Hadoop 社区,以吸引更多用户使用 Hadoop 生态体系。就好比淘宝买家卖家相互增长,形成商业互补,相辅相成。
Hadoop 的用户生态
前文已述,优秀的开源(免费)系统确实非常容易吸收用户流量、提升用户基数,这个早已是不争事实。通过开源 (免费) 的系统软件铺开发者市场、培养开发者习惯、筹建开发者社区,早已是开源软件背后商业公司的公开市场打法,这就类似通过免费 APP 培养海量客户技术,最终通过收割头部客户实现营收。或者好比一款游戏,大部分可能均是免费玩家,但用户基数达可观规模之时,一定涌现出不少人民币玩家,并通过他们实现整体营收。当前风头正紧的开源大数据公司,包括 DataBricks(Spark)、Confluent(Kafka)、Ververica(Flink)莫不如此。在开源软件竞争激烈日趋激烈的环境下,其背后若无商业公司资金支撑,其背后若无市场商业团队运营支撑,当年写一个优秀的开源软件就凭”酒香不怕巷子深“的保守概念,现如今早已推不动其软件生态圈发展。试看当前大数据生态圈,那些日暮西山、愈发颓势的开源软件,其背后原因多多少少就是缺乏商业化公司的运作。
Hadoop 的商业生态
大量商业公司基于 Hadoop 构建产品服务实现营收,云计算公司直接拉起 Hadoop 体系工具作为大数据云计算服务,软件集成商通过包装 Hadoop 引擎提供客户大数据处理能力,知识机构(包括书籍出版社、Hadoop 培训机构)通过培训 Hadoop 开发运维体系实现营收和利润,上述种种商业行为均基于 Hadoop 体系实现商业利润。整个 Hadoop 开创了开源大数据的新概念,并由此养活大数据行业数不胜数的参与者。这波参与者享受了开源 Hadoop 的收益,同时也在为 Hadoop 贡献知识。
如果说 Google 三篇论文发表后敲开了大数据时代的理论大门,但论文绝逼异常高冷、不接地气、无法落地投产。真正人人皆用大数据的时代是直到开源社区提供了成熟的 Hadoop 软件生态体系之后,我们才可以说企业界方才逐步进入到大数据时代。可以说,当代 Hadoop 的诞生,为企业大数据应用推广起到了决定性作用。
生态:大数据的林林总总
Google 三家马车叩开了大数据理论大门,而 Hadoop 才真正开启了行业大数据时代。前文已述,Hadoop 已经早已超出 MapReduce(计算模型)和 HDFS(分布式存储)软件范畴。当前早已成为 Hadoop 大数据代名词,指代大数据社区生态,无数号称新一代、下一代的大数据技术无不构建在 Hadoop 生态基石之上。下文我们分维度重点讨论基于 Hadoop 生态之上的各式各样大数据组件抽象。
高阶抽象:让人人成为大数据用户
上篇道,数据库两位大拿 David J. DeWitt 以及 Michael Stonebraker 十分不待见 MapReduce 论文所诉理论,基本上是羽檄争执、口诛笔伐。其讨伐重点之一便是使用 MapReduce 而抛弃 SQL 抽象,将实际问题的解决难度转嫁用户非正确的系统设计方式。同样,这个批判确为 MapReduce 之缺陷,凡是正常人类绝逼感同身受。一个普普通通数据处理业务,用 SQL 表达多则百行、少则数行,熟练的数据工程师多则数小时少则数分钟即可完成业务开发,轻松简便。而一旦切换到 MapReduce,需要将 SQL 的直接业务表达子句换成底层各种 Map、Reduce 函数实现,少则数千行多达数万行,导致整个数据开发难度陡增,业务开发效率抖降。
针对上述两个问题,Google 和 Hadoop 两条技术分别做出各自的技术方案:
Google 公司的 FlumeJava
Google 尝试提供高阶的 API 去描述数据处理 Pipeline,进而解决上述业务表达难题。FlumeJava 通过提供可组合的高级 API 来描述数据处理流水线,从而解决了这些问题。这套设计理念同样也是 Apache Beam 主要的抽象模型,即 PCollection 和 PTransform 概念,如下图:

这些数据处理 Pipeline 在作业启动时将通过优化器生成,优化器将以最佳效率生成 MapReduce 作业,然后交由框架编排执行。整个编译执行原理图如下图。

FlumeJava 更清晰的 API 定义和自动优化机制,在 2009 年初 Google 内部推出后 FlumeJava 立即受到巨大欢迎。之后,该团队发表了题为《Flume Java: Easy, Efficient Data-Parallel Pipelines》的论文,这篇论文本身就是一个很好的学习 FlumeJava 的资料。
开源生态的 Hive
开源社区受众更广,其使用者更多,因此实际上开源社区对于开发效率提升诉求更高。但 Hadoop 社区似乎对于 SQL 情有独钟,更多将精力投入到 SQL-On-Hadoop 类的工具建设之中,最终,社区吸收 Facebook 提交给 Apache 基金会的 Hive,并形成了业界 SQL-On-Hadoop 的事实标准。
大数据开发技术群:957205962
对于 Hive 而言,其官网特性说明充分阐释了 Hive 的作为一套 Hadoop MapReduce 之上的 DSL 抽象之价值和特性:
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
于笔者这样的产品经理而言,其重要意义是将 MapReduce 进一步进行抽象为业务高阶语言,让更多不善于 Java/C++ 编码的数据工程师能够快速上手使用大数据工具进行数据分析,让大数据业务开发成本更低、使用门槛更低、维护成本更低,让传统的、使用数据库的数据分析师能够基本无缝迁移到基于 Hadoop 的大数据平台,从而极大扩展了大数据用户群体,进一步拉动 Hadoop 社区的用户生态以及商业生态。
从另外一个方面,Hive 作为一个 SQL-On-Hadoop 工具,为后续诸多大数据处理软件提供了很好的表率:即越高阶的业务抽象 API 能够极大降低用户开发门槛,拉动使用者基数。后续大量的开源闭源大数据系统都或多或少、有模有样地提供了各自 SQL 方言,方便用户更加快速、简单地上手各自的大数据软件。开源社区来看,从 Hive 开始,Presto、Impala、Spark、或者当前风头正紧的 Flink,无不提供 SQL 作为高阶数据分析语言。从闭源产品而言,阿里云的 MaxCompute、AWS 的 Redshift、Google 的 BigQuery,均提供各自 SQL 抽象以争取更多云上开发人员的使用。据阿里对外宣传的文章来看,基于 MaxCompute 的离线数仓体系服务了整个阿里集团数万名员工之众、每日运行作业达数百万至多,以至于集团内部包括数据工程师、产品经理、运营人员、财务人员人人可以分析数据,人人可以提取数据,人人皆为数据分析师。可以想像,若非 SQL 这类高阶业务表达语言助力,阿里集团大数据体系绝无可能有如此规模的受众群体,亦不可能产生巨大业务价值。

实时计算:让计算更快产生业务价值
大数据诞生之初给使用者最大的疑惑在于:为何计算如此之慢?彼时使用数据库多数查询在亚秒级别返回,使用数仓多数查询在数秒级别返回,到 Hadoop 的大数据时代,大部分查询在数分钟、数小时、甚至于数天级别方才能够查询出结果。大数据、大数据,在一旦解决计算可处理的问题之后,时效性问题便摆上台面。
大数据领域下,时效性分为两个方面:
数据从用户请求到最终呈现的实时性,这条路径强调的是请求响应的及时性。
数据从发生到处理、并最终产生业务价值的全链路时效性,这条路径强调的是数据链路及时性。
前者我们称之为交互式计算领域,后者我们称之为实时(流)计算领域。我一直认为交互式查询是技术方面的优化,是人人痛恨 MapReduce 计算模型太慢太落后的技术优化,和产品形态并无太大关联。而后者,则是整个大数据产品模型的变化,这是一种触发式计算,有点类似阿里云的 FunctionCompute,或者是 AWS 的 Lambda;或者更加准确地定义是:基于事件流的实时流计算。我们通常看到三个系统:
第一代:Storm
Storm 是 Nathan Marz 的心血结晶,Nathan Marz 后来在一篇题为《History of Apache Storm and lessons learned》的博客文章中记录了其创作历史。这篇冗长的博客讲述了 BackType 这家创业公司一直在自己通过消息队列和自定义代码去处理 Twitter 信息流。Nathan 和十几年前 Google 里面设计 MapReduce 相关工程师有相同的认识:实际的业务处理的代码仅仅是系统代码很小一部分,如果有个统一的流式实时处理框架负责处理各类分布式系统底层问题,那么基于之上构建我们的实时大数据处理将会轻松得多。基于此,Nathan 团队完成了 Storm 的设计和开发。

上述将 Storm 类比为流式的 MapReduce 框架,我自认为特别贴切,因为这个概念类比更好向各位看官传达了 Storm API 的 low-level 以及开发效率低下,这类基础大数据的 API 让业务人员参与编写业务逻辑好比登天。同时,Storm 的设计原则和其他系统大相径庭,Storm 更多考虑到实时流计算的处理时延而非数据的一致性保证。后者是其他大数据系统必备基础产品特征之一。Storm 针对每条流式数据进行计算处理,并提供至多一次或者至少一次的语义保证。我们可以理解为 Storm 不保证处理结果的正确性。
第二代:Spark
Spark 在 2009 年左右诞生于加州大学伯克利分校的著名 AMPLab。最初推动 Spark 成名的原因是它能够经常在内存执行大量的计算工作,直到作业的最后一步才写入磁盘。工程师通过弹性分布式数据集(RDD)理念实现了这一目标,在底层 Pipeline 中能够获取每个阶段数据结果的所有派生关系,并且允许在机器故障时根据需要重新计算中间结果,当然,这些都基于一些假设 a)输入是总是可重放的,b)计算是确定性的。对于许多案例来说,这些先决条件是真实的,或者看上去足够真实,至少用户确实在 Spark 享受到了巨大的性能提升。从那时起,Spark 逐渐建立起其作为 Hadoop 事实上的继任产品定位。
在 Spark 创建几年后,当时 AMPLab 的研究生 Tathagata Das 开始意识到:嘿,我们有这个快速的批处理引擎,如果我们将多个批次的任务串接起来,用它能否来处理流数据?于是乎,Spark Streaming 就此诞生。相比于 Storm 的低阶 API 以及无法正确性语义保证,Spark 是流处理的分水岭:第一个广泛使用的大规模流处理引擎,既提供较为高阶的 API 抽象,同时提供流式处理正确性保证。 有关更多 Spark 的信息,笔者推荐 Matei Zaharia 关于该主题的论文《 An Architecture for Fast and General Data Processing on Large Clusters》:
第三代:Flink
Flink 在 2015 年突然出现在大数据舞台,然后迅速成为实时流计算部分当红炸子鸡。从产品技术来看,Flink 作为一个最新的实时计算引擎,具备如下流计算技术特征:
完全一次保证:故障后应正确恢复有状态运算符中的状态
低延迟:越低越好。许多应用程序需要亚秒级延迟
高吞吐量:随着数据速率的增长,通过管道推送大量数据至关重要
强大的计算模型:框架应该提供一种编程模型,该模型不限制用户并允许各种各样的应用程序在没有故障的情况下,容错机制的开销很低
流量控制:来自慢速算子的反压应该由系统和数据源自然吸收,以避免因消费者缓慢而导致崩溃或降低性能
乱序数据的支持:支持由于其他原因导致的数据乱序达到、延迟到达后,计算出正确的结果。
完备的流式语义:支持窗口等现代流式处理语义抽象
你可以理解为整个实时计算产品技术也是时间发展而逐步成熟发展而来,而上述各个维度就是当前称之为成熟、商用的实时计算引擎所需要具备的各类典型产品技术特征。Flink 是当前能够完整支持上述各类产品特征参数的开源实时流处理系统。

全家桶:一套引擎解决“所有”大数据问题
Flink 和 Spark:All-In-One
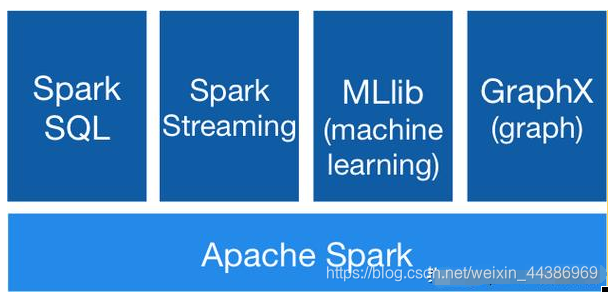
大数据全家桶其实是一个实打实的产品问题:从大数据社区反馈的情况来看,对于大部分大数据处理用户,实际上的大数据处理诉求分类有限,基本上在 Batch(60%+)、Stream(10%+)、Adhoc(10%+)、其他(包括 ML、Graph 等等)。对于任何一个大数据处理引擎深入做透一个领域后,势必会考虑下一步发展,是继续做深做专,抑或还是横向扩展。做又红又专?从商业来看,这个领域的市场规模增长可能有限,眼瞅着都到天花板了;但从横向角度来看,周边大数据引擎虎视眈眈,随时都有杀入我们现有市场之中。面对市场,各色需求可穷举;面对技术,引擎基础业已夯实,为何不周边突破扩展,开拓新的大数据领域。Spark 从批入手,针对 Hadoop 处理性能较差的问题,将 Spark 的 Batch 功能做成一个“爆款应用”,同时提供 Spark Streaming、Spark ML,前期靠 Spark Batch 为整个 Spark 社区用户倒流,并吸收为 Spark Streaming、Spark ML 的客户。而通过 Spark 大数据全家桶功能,Spark 产品构建一个粘性的护城河。大量中小用户一旦全功能上了 Spark,大家理解后续很难因为 Spark 某个功能点不太满足需求而抛弃使用 Spark。
Spark 从批入手,尝试在一个技术栈体系内统一基础的大数据处理;在另外一个方向,Flink 从 Stream 入手,在构建出 Flink Stream 强大生态后,也在考虑布局 Flink Batch,从 Stream 切入 Batch 战场。
下图是 Spark 的软件栈体系:
下图是 Flink 的软件栈体系:

两者在产品功能栈上早已十分相似,缺的是各自薄弱领域的精细化打磨。在此,我们不讨论两者功能强弱分布,毕竟本文不是一个产品功能介绍文章。未来两个系统鹿死谁手花落谁家,各位看官拭目以待吧。
Beam: One-Fits-All
前文已述,早期 Google 在大数据领域纯粹扮演了一个活雷锋的角色,以至于整个开源大数据生态蓬勃发展起来,并最终形成完整的大数据商业生态之时,Google 基本门外一看客,眼瞅着自己的技术理论在开源社区发扬光大,自己没捞半点好处。适时,Google 云业已发展起来,并拉起诸多祖师爷级别的产品技术服务客户,例如 BigTable。常理而言,BigTable 开创 NoSQL 大数据之先河,其 Paper 位列 Google 大数据三驾马车之中,技术地位可见一斑。再看社区 HBase,乃直接“抄袭”Google BigTable 论文理论,实乃徒子徒孙之技术。但最终,Google 云发布 BigTable 产品之时,为了考虑社区产品兼容性以及用户上云迁移成本,竟然不得不兼容 HBase 1.0 的 API 接口。可以想象,BigTable 项目组成员当时内心感觉只能是:简直日了狗!但一切为了云计算营收,BigTable 产品放下技术执念选择兼容 HBase 接口,实属难得!我们为 Google 尊重市场而放下身段的行为点赞!
Google 受此大辱,吃此大亏,当然会痛定思痛,考虑建设开源社区并尝试力图控制社区。于是在此背景之下,Apache Beam“粉墨登场”。Google 考虑问题之核心不在于是否要开源一个大数据处理系统(当时社区 Spark 已经蔚然成风,Flink 的发展同样亦是扶摇直上,似乎社区并无缺少一个好的大数据引擎),而仅仅缺乏开源社区大数据处理接口之统一,包括将核心的批处理以及流处理接口统一。而之前 Google 内部的 FlumeJava 一直承担大数据 Data Pipeline 之 API 定义角色,于是想当然地从内部将之前的 FlumeJava 接口进行抽象改进,提供统一的批流处理 API 后在 2016 年贡献提交给 Apache 基金会。试图通过定义一套统一的 API 抽象层,说服各个厂商实现该套抽象,即可完成 API 统一的千秋大业,并为用户迁移 Google 云上埋下最大伏笔。
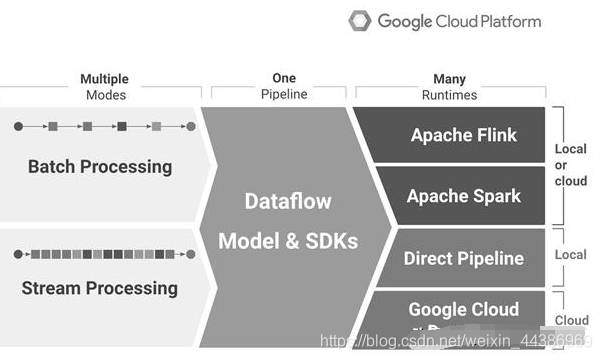
此类打法构思只能是技术人员对于大数据社区发展不切实际的梦想,或者是 Google 实在太高估自己的技术影响力,认为只要 Google 技术一出,开源社区绝对俯首称臣,拉下老脸哭着喊着求兼容。但 Google 打错算盘的是,从没有一个市场追赶者角色制定标准来让市场领导者来做适配,市场领导者凭什么鸟你。你区区一个追赶者,制定标准,挖下大坑,让领导者来兼容你的标准绝对是痴人说梦。于是乎,在 Apache Beam 发布之后,除 Flink 社区意图想联合 Beam 社区一起做做技术影响力之外,其他开源大数据产品和 Beam 一直若即若离。大家都是明白人,都明白 Google 大力推动 Beam 的明修栈道暗度陈仓,我兼容你标准,最终你不是靠云上产品想把大家的流量全部收割了么。因此,开源社区难以有真心和 Beam 社区结成歃血同盟者,社区合作者多半皆是善于投机的机会主义者。一时间,Beam 的前景黯淡。
结语
本文浏览了整个大数据发展历史,特别重点关注了数据计算处理部分的内容。我们从程序本质以及行业发展脉络分别描述了大数据之前的程序时代以及数据库时代,大数据当代的各类理论、系统、社区发展。我们观察历史,是让我们有信心面对当前;我们分析当代,是让我们有机会看清未来。未来整个云计算以及之上的大数据发展,已经超出本文的讨论范畴,但从上述历史、当代分析能对未来其发展推测一二,欢迎大家自行思考。文章行文较为仓促,定有纰漏之处,望各位看官不吝赐教。
大数据开发技术群:957205962
-!