针对一个二分类问题,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况.
(1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
(2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
TP:正确的肯定数目
FN:漏报,没有找到正确匹配的数目
FP:误报,没有的匹配不正确
TN:正确拒绝的非匹配数目
TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。TPR=TP/(TP+FN)
FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。FPR=FP/(FP+TN)
TPR=Y
FPR=X
如在医学诊断中,判断有病的样本。那么尽量把有病的揪出来是主要任务,也就是
TPR: 判断有病的样本。那么尽量把有病的揪出来是主要任务,第一个指标TPR,要越高越好。
FPR: 把没病的样本误诊为有病的,要越低越好。
不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。

我们可以看出:
(0,1): 左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对;
A: (TPR>FPR),医生A的判断大体是正确的。
B: (TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;
C: (TPR<FPR),这个医生说你有病,那么你很可能没有病,医生C的话我们要反着听。
上图中一个阈值,得到一个点。现在我们需要一个独立于阈值的评价指标来衡量这个医生的医术如何,也就是遍历所有的阈值,得到ROC曲线。还是一开始的那幅图,假设如下就是某个医生的诊断统计图,直线代表阈值。我们遍历所有的阈值,能够在ROC平面上得到如下的ROC曲线。
**
- 如何画roc曲线(下面有详细过程)
假设已经得出一系列样本被划分为正类的概率,然后按照大小排序,下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
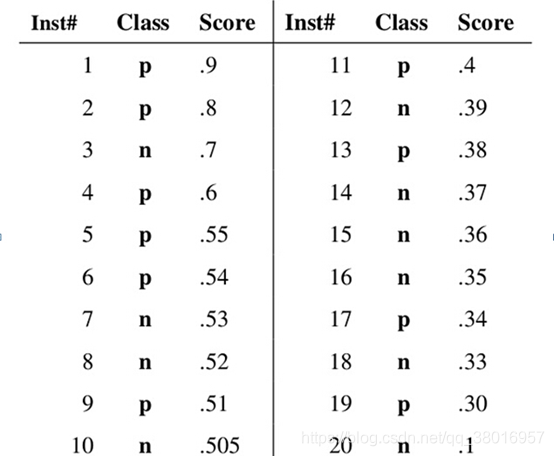
接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:

如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的FPR=0.23的情况下,红色分类器得到更高的TPR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化他。
对于图中的第4个样本,其“Score”值为0.6,在此阈值的情况下,仍然能够使TPR很大,FPR很小,对于每个Score都能这样的话,AUC值越大,这个曲线会越接近(0,1),得到的面积会越大
AUC:一个正例,一个负例,预测为正的概率值比预测为负的概率值还要大的可能性。
所以根据定义:我们最直观的有两种计算AUC的方法
1:绘制ROC曲线,ROC曲线下面的面积就是AUC的值
2:假设总共有(m+n)个样本,其中正样本m个,负样本n个,总共有mn个样本对,计数,正样本预测为正样本的概率值大于负样本预测为正样本的概率值记为1,累加计数,然后除以(mn)就是AUC的值
**
- AUC值的定义
**
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
AUC常常被用来作为模型排序好坏的指标,原因在于AUC可以看做随机从正负样本中选取一对正负样本,其中正样本的得分大于负样本(负样本的Score小于阈值)的概率
举例:一个正样本,一个负样本,模型预测出正样本的Score为a%,负样本为b%,且阈值在ab之间,AUC为a大于b的概率,此概率即为预测正确的概率。
AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地正确分类。
**
- AUC计算
- 由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯 下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么 做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此 时,我们就需要计算这个梯形的面积。由此,我们可以看到,用这种方法计算AUC实际上是比较麻烦的。
2.任意给一个正类样本和一个负类样本,正类样本的score大于负类样本的score的概率。有了这个定义,我们就得到了另外一中计算AUC的办法:得到这个概率。我们知道,在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。这 和上面的方法中,样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
-
第三种方法实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去M-1种两个正样本组合的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即
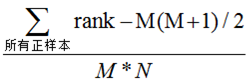
公式解释:
1、为了求得组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为12、根据上面的解释,不难得出,rank的值代表的是能够产生score前大后小的这样的组合数,但是这里包含了(正,正)的情况,所以要减去这样的组(即排在它后面正例的个数),即可得到上面的公式
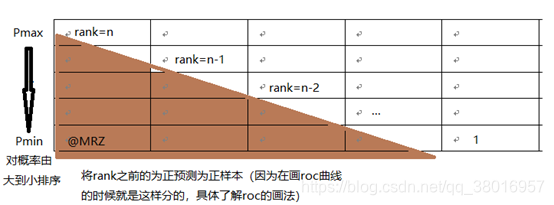
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
原文:https://blog.csdn.net/u013385925/article/details/80385873
**
- 如下是sklearn计算ROC曲线的例子
**
sklearn给出了一个计算ROC的例子[1]。
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
通过计算,得到的结果(TPR, FPR, 阈值)为
fpr = array([ 0. , 0.5, 0.5, 1. ])
tpr = array([ 0.5, 0.5, 1. , 1. ])
thresholds = array([ 0.8 , 0.4 , 0.35, 0.1 ])# 阈值,预测结果
将结果中的FPR与TPR画到二维坐标中,得到的ROC曲线如下(蓝色线条表示),ROC曲线的面积用AUC表示(淡黄色阴影部分)。
详细计算过程
针对score,将数据排序
样本 预测属于P的概率(score) 真实类别

将阈值依次取值为0.1,0.35,0.4,0.8时,计算TPR和FPR的结果。
阈值0.1:

scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [1, 1, 1, 1]
TPR = TP/(TP+FN) = 1
FPR = FP/(TN+FP) = 1
阈值0.35:
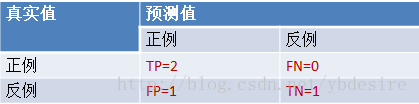
y_pred = [0, 1, 1, 1]
TPR = TP/(TP+FN) = 1
FPR = FP/(TN+FP) = 0.5
阈值0.4:
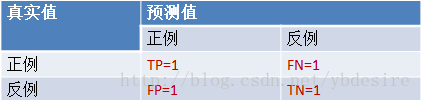
y_pred = [0, 1, 0, 1]
TPR = TP/(TP+FN) = 0.5
FPR = FP/(TN+FP) = 0.5
阈值0.8:
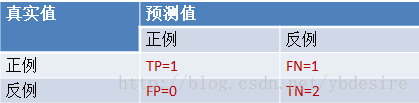
y_pred = [0, 0, 0, 1]
TPR = TP/(TP+FN) = 0.5
FPR = FP/(TN+FP) = 0