数据预处理
现实中的数据
现实中的数据库数据很庞大,而且数据来源于“不同复杂各异”的数据源。数据库受噪声、缺失值、不一致数据的影响,使得数据低质量,导致低挖掘结果。
为提高数据质量,和挖掘结果的质量,对数据预处理是必要的。
1.数据预处理的技术
- 数据清理:清除数据中的噪声,纠正不一致。
- 数据集成:将多个数据源的数据合并到一个一致的数据存储中,如数据仓库。
- 数据规约:通过聚集、删除冗余特征、聚类来降低数据的规模。
- 数据变换:(如,规范化)可以把数据压缩到较小的区间,如0到1。对涉及距离度量的挖掘算法可提高准确率和效率。
2.数据质量:为什么要对数据预处理?
2.1 数据质量依赖于数据的应用。也即对于同一数据库,不同需求的分析人员对其数据评价不同。(数据质量没有绝对的好坏,只要能满足分析人员的应用要求,那么它就是高质量的。)
影响数据质量的因素:准确性、完整性、一致性、时效性、可信性、可解释性。
假设你是销售经理,公司要求你分析部门的销售数据,想知道每种销售商品是否做了降价销售广告,你需要分析某些属性或维。但是你希望用数据挖掘技术分析的数据是:
不完整的(缺少属性值或某些感兴趣的属性);
不正确的或含噪声的(包含错误的或偏离期望的值);
不一致的(如,用于商品分类的部门编码存在差异)。
以上是数据质量的三要素,是大型数据库的共同特点。而导致三要素出现的原因有多种:
- 收集数据的设备可能故障;
- 人和计算机的错误输入;
- 当用户不希望提交个人信息时,会故意输入错误信息,(如出生年月、个人收入)。这被称为被掩盖的缺失数据。
时效性(有的数据在数据库中需要实时更新,再数据挖掘分析之前未更新的数据将会严重影响数据质量)
可信性 (反映有多少数据是用户信赖的)
可解释性(反映数据是否容易理解,有些数据用编码形式存储,分析人员难以理解,会把它看成低质量的数据)
2.2 数据预处理的主要任务
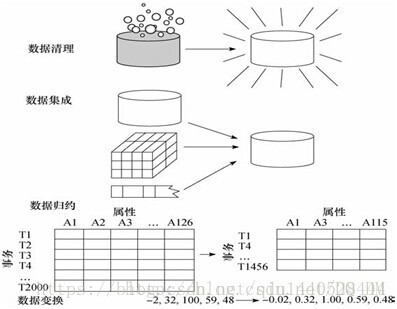
数据预处理的主要步骤:数据清理、数据集成、数据归约、数据变换。
-
数据清理:通过填写缺失的值,光滑噪声数据,识别和删除离群点,解决不一致性来“清理”数据。
-
数据集成:假设分析中使用来自多个数据源的数据,这涉及集成多个数据库、数据立方体或文件。
-
数据归约:由于数据集大都很庞大,降低了数据挖掘的速度,为降低数据集的规模,而又不损害数据挖掘的结果。数据归约能得到数据集的简化表示,并产生同样的分析结果。包括维归约和数值归约。
1.)在维归约中,使用数据编码方案,以便得到原始数据的简化或“压缩”表示。包括数据压缩技术(如,小波变换、主成分分析);和属性子集选择(如,去掉不相关的属性);属性构造(如,从原来的属性集导出更有用的小属性集)。
2.)在数值归约中,使用参数模型(如,回归和对数线性模型)或非参数模型(如,直方图、聚类、抽样、数据聚集),用较小的表示取代数据。 -
数据变换:数据被变换成或统一成适合于挖掘的形式。包括,规范化、数据离散化、概念分层。
如下图为数据预处理的形式:
3.数据清理
3.1 缺失值
假设你需要分析顾客数据,许多元组的一些属性(如,顾客的income)没有记录值。如何填写缺失值呢?
- 忽略元组:当元组的多个属性值缺失时,且每个属性值的百分比变化不大时,可采用忽略该元组。忽略后该元组的剩余属性值不能再考虑使用。
- 人工填写缺失值:当数据集很大时,缺失值很多,该方法不适合。
- 使用一个全局常量填充缺失值:将缺失属性值用同一个常量(如,Unknown)替换。该方法简单但并不可靠。
- 使用属性的中心度量(如,均值或中位数)填充缺失值:在讨论数据的中心趋势度量时,可指示数据分布的“中间”值。因此,对于正常的(对称的)数据分布,可使用均值。对于倾斜数据分布可使用中位数。如,顾客的income数据分布是对称的,平均收入为5000元,则可用该值替换income的缺失值。
3.1 噪声数据
什么是噪声呢? 噪声是被测量的变量的随机误差或方差。
如何表示呢? 使用统计描述技术(如,盒图、散点图)和数据可视化方法来识别代表噪声的离群点。
给定一个数值属性,如price,如何“光滑”数据、去掉噪声?
我们看看以下数据光滑技术
分箱:通过考察数据的“近邻”(周围值)来光滑 有序数据值。将这些有序的值分布到一些“桶”或箱中。由于分箱方法考察近邻值,因此进行的是局部光滑。
如下图是数据光滑的分箱方法:
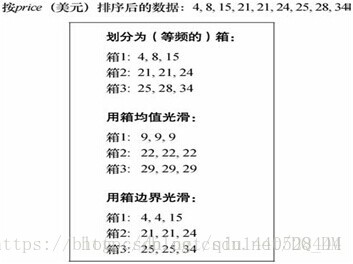
- 用箱均值光滑:箱中每一个值被箱中的平均值替换。
- 用箱中位数光滑:箱中的每一个值被箱中的中位数替换。
- 用箱边界光滑:箱中的最大和最小值被视为边界。箱中的每一个值被最近的边界值替换。
回归:也可用一个函数拟合数据来光滑数据。称为回归。线性回归是找出拟合两个属性的“最佳”直线,使得一个属性可以用来预测另一个。多元线性回归,涉及多个属性将数据拟合到一个曲面。
离群点分析:可通过聚类来检测离群点。直观的,落在簇外的值被视为离群点。
4.数据集成
数据挖掘经常需要数据集成——合并来自多个数据存储的数据。合理有效的集成有助于减少结果数据集的冗余和不一致。
由于数据语义和结构的多样性,对数据集成提出了巨大挑战。如何匹配多个数据源的模式和对象,这实际上是实体识别问题。
4.1 实体识别问题
- 数据集成时,通常需要模式集成和对象匹配,*来自多个信息源的等价实体如何才能“匹配”?*如,计算机如何确定一个数据库中的customer_id和另一个数据库中的cust_number指的是相同的属性。
- 其实,每个属性的元数据包含名字、含义、数据类型和属性的允许取值范围,以及处理空白、零、NULL的空值规则。这样的元数据可以用来帮助避免模式集成的错误。元数据还可以用来帮助变换数据。
4.2 冗余和相关分析
- 冗余是数据集成的另一个重要问题。一个属性(如,年收入)如果能由其他属性导出,则这个属性可能是冗余的。属性或维命名的不一致也可能导致结果数据集成的冗余。
- 有些冗余可以被相关分析检测到。对于两个可能存在冗余的属性,这种分析可以根据可用的数据,度量一个属性能在多大程度上蕴涵另一个。
对于标称数据,我们使用卡方检验。对于数值数据,我们使用相关系数和协方差。它们都可以用来评估一个属性的值如何随另一个变化。
4.3 元组重复
除了检测属性间的冗余外,还应当在元组间检测重复(例如,对于给定的唯一数据实体,存在两个或多个相同的元组)。
4.4 数据值冲突的检测与处理
- 数据集成还涉及数据值冲突的检测与处理。例如,对于现实世界的同一实体,来自不同数据源的属性值可能不同。这可能是因为表示、尺度或编码不同。例如,重量属性可能在一个系统中以公制单位存放,而在另一个系统中以英制单位存放。
- 属性也可能在不同的抽象层,其中属性在一个系统中记录的抽象层可能比另一个系统中“相同的“属性低。比如,total_sales在一个系统中表示分店销售额,但在另一个系统表示区域销售额。
5. 数据归约
数据归约技术可以用来得到数据集的归约表示,它很小,但任然保持了原始数据的完整性。也即在归约后的数据集上挖掘更有效,任然产生相同的分析结果。
5.1 数据归约的策略概述
数据归约策略包括维归约、数量归约、数据压缩
-
维归约: 减少所考虑的随机变量或属性的个数。 维归约方法包括小波变换、主成分分析(把原数据变换或投影到较小的空间)、属性子集选择(其中不相关、弱相关、冗余的属性或维被检测和删除)。
-
数量归约:用替代的、较小的数据表示形式,替换原数据。这些技术可以是参数的或非参数的。 对于参数方法,使用模型估计数据(一般只需要存放模型参数,而不是实际数据)。非参数方法包括,直方图、聚类、抽样、数据立方体聚集。
-
数据压缩:使用变换,以便得到数据的归约或“压缩”表示。如果原数据能够从压缩后的数据重构,而不损失信息,则该数据规约称为无损的。如果我们只能近似重构原数据,则该数据规约称为有损的。
6. 数据变换与数据离散化
在数据预处理阶段,数据被变换或统一,使得挖掘过程更有效,挖掘的模式可能更容易理解。
6.1 数据变换策略概述
在数据变换中,数据被变换或统一成适合于挖掘的形式。数据变换策略包括如下几种:
- 光滑:去掉数据中的噪声。这类技术包括分箱、回归、聚类。 属性构造(或特征构造):可以由给定的属性构造新的属性并添加到属性集中。
- 聚集:对数据进行汇总或聚集。例如,可以聚集日销售数据,来计算月和年销售量。
- 规范化:把属性数据按比例缩放,使落到一个特定的小区间,如,0.0-1.0。
- 离散化:数值属性(如,年龄)的原始值,用区间标签(如,0-20,21-30);或概念标签(如,youth,adult,senior)替换。
由标称数据产生概念分层:属性,如street,可以泛化到较高的概念层,如city。