任何爬虫爬取的数据都需要存储,除了使用pandas和csv模块存为本地文件,也可以用数据库完成存储。
根据橡皮擦老师的例子,mongodb数据库存储数据,对应的python模块是pymongo
使用例子,在scrapy框架下,一个典型的pipeline.py文件如下
使用前期,操作本地数据库,数据库是自启动的,并且已经建立了一个db,名称为sun,建立了用户/密码:dba/dba
import time
import pymongo
DATABASE_IP = '127.0.0.1'
DATABSSE_NAME = 'sun'
DATABASE_PORT = 27017
client = pymongo.MongoClient(DATABASE_IP,DATABASE_PORT) #连接数据库
db = client.sun #获取数据库
db.authenticate("dba", "dba") #登录鉴权
collection = db.cloudwork #生成存储表单
class CloudworkPipeline(object):
def process_item(self, item, spider):
try:
#scrapy的存储很简单,就是直接将爬虫返回的item写入表单即可
collection.insert(item)
except Exception as e:
print(e.args)
使用数据库工具查看该数据库内容,我用的是navicat(for mongodb)
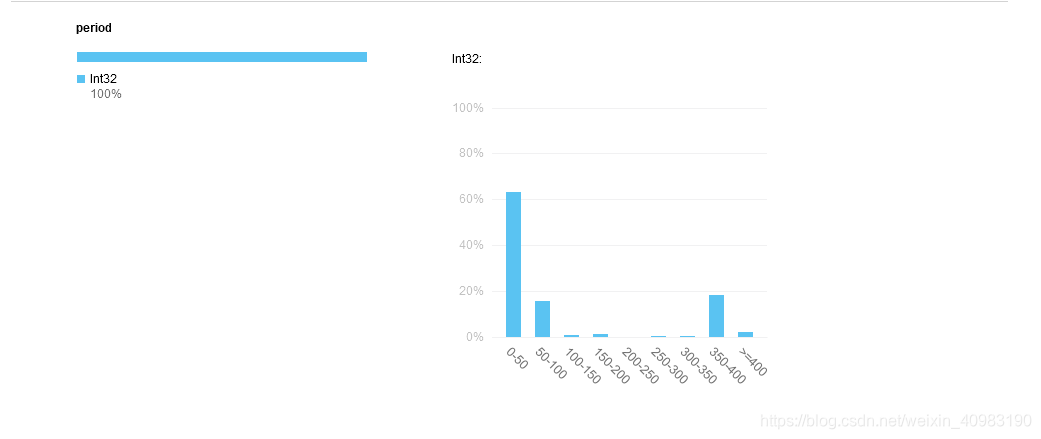
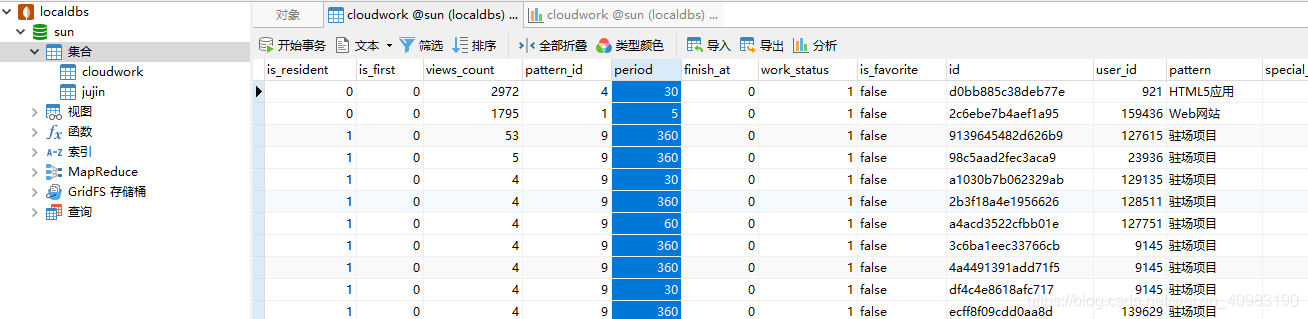 也可以点击分析查看分析图表,比如分析period,可以看到工期分布的柱状图
也可以点击分析查看分析图表,比如分析period,可以看到工期分布的柱状图
 如果要在代码里取用数据库,同样的流程
如果要在代码里取用数据库,同样的流程
# 先连接数据库
client = pymongo.MongoClient("localhost",27017)
db = client.sun
db.authenticate("dba", "dba")
collection = db.cloudwork
# 加载数据,data就是collection表单
data = DataFrame(list(collection.find()))
# 再通过data取出表的某一列操作
views = data["views_count"]