日期:2019/5/4
关键词:操作系统笔记;内存管理;连续分配
一、概述
物理内存分配方案:
- 连续分配存储管理
- 分页存储管理
- 分段存储管理
- 段页式存储管理
可分为2大类:连续分配(1)和离散分配(2,3,4)。

二、动态内存分配
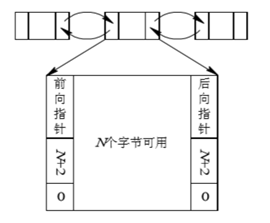
2.1 数据结构
- 空闲分区表(二维表):在系统中设置一张空闲分区表,用于记录每个空闲分区的情况。每个 空闲分区占一个表目,表目中包括分区序号、分 区始址及分区的大小等数据项。
-
空闲分区链(链表)
2.2 分配与回收操作
-
内存分配
u.size:请求分区的大小。
m.size:每个空闲分区的大小。
size:事先规定不再切割的剩余分区大小。
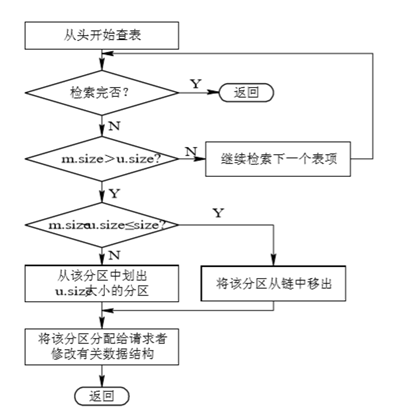
注:m.size – u.size <= size?
- 内存回收
... |
... |
... |
... |
F1 |
非空闲 |
F1 |
非空闲 |
回收区 |
回收区 |
回收区 |
回收区 |
非空闲 |
F2 |
F2 |
非空闲 |
... |
... |
... |
.... |
1 |
2 |
3 |
4 |
四种情况:
1. 向前合并:与插入点的前一个空闲分区 F1相邻接,不必为回收分区分配新表项,而只需修改其前一分区 F1的大小。
2. 向后合并:与插入点的后一空闲分区 F2相邻接,用回收区的首址作为新空闲区的首址,大小为两者之和。
3. 前后合并:回收区同时与插入点的前、后两个分区邻接,此时将三个分区合并, 使用 F1的表项和 F1的首址,取消 F2的表项,大小为三者之和。
4. 回收区既不与 F1邻接,又不与 F2邻接。这时应为回收区单独建立一新表项,填写 回收区的首址和大小,并根据其首址插入到空闲链中的适当位置。
2.2 分配算法——基于顺序搜索
-
首次适应算法(First Fit)
空闲分区以地址递增的次序链接,分配时,从链首开始顺序查找,找到后,再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。
优点:高地址区存在大的空闲区。
缺点:低址部分留下许多无用留碎片(因为不断被划分),而每次查找又都从低址部分开始,增加了查找开销。
-
循环首次适应算法(Next Fit)
从上次找到的空闲分区的下一个开始查找。
优点:该算法能使内存中的空闲分区分布比较均匀,从而减少查找空闲分区的时间。
缺点:缺少大的空闲区。
-
最佳适应算法(Best Fit)
空闲分区按其从小到大的顺序链接。顺链找第一个满足要求的空闲区。(即所有满足条件的空闲分区中最小的那个)
缺点:分配后,切割下来的剩余部分总是最小的,产生很多难以利用的碎片。
-
最坏适应算法(Worst Fit)
所有满足条件的空闲分区中最大的那个。(实际上就是所有空闲分区中最大的那个)
2.3 分配算法——基于索引搜索
- 快速适应算法(Quick Fit)
- 哈希算法
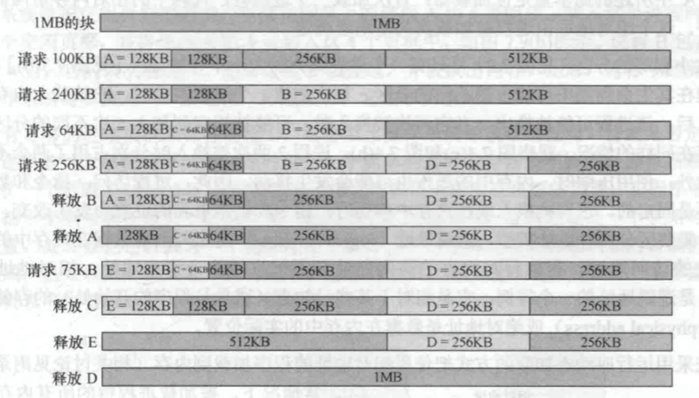
- 伙伴系统(Buddy System)
固定分区如果分区大小与进程大小很不匹配,利用率低下;动态分区维护复杂;伙伴系统是一种折中的方案。
Unix存储分配就采用改进后的伙伴系统。
口诀:大于一半拿整个,小于一半拿一半。
算法示例:
三、可重定位分区分配
妈蛋,这里就是把动态内存分配中产生的"空洞"压缩。课本讲得跟shit一样。