什么是内存?有何作用
内存是用于存放数据的硬件。程序执行前需要先放到内存中才能被CPU处理。
在多道程序环境下,系统中会有多个程序并发执行,也就是说会有多个程序的数据需要同时放到内存中。那么,如何区分各个程序的数据是放在什么地方的呢?
方案:给内存的存储单元编地址
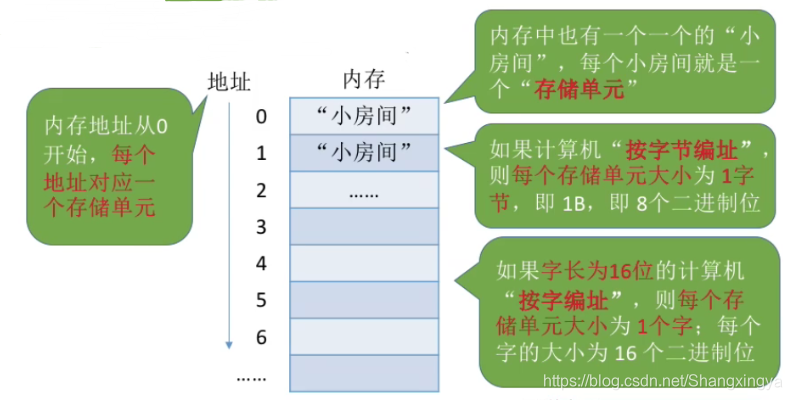
值得注意的就是每个计算机的位数不同, 有16位, 32位, 那么每个地址对应的存储空间是不一样的, 而且CPU一次处理指令的位数也是不一样的
进程的运行原理 - 指令

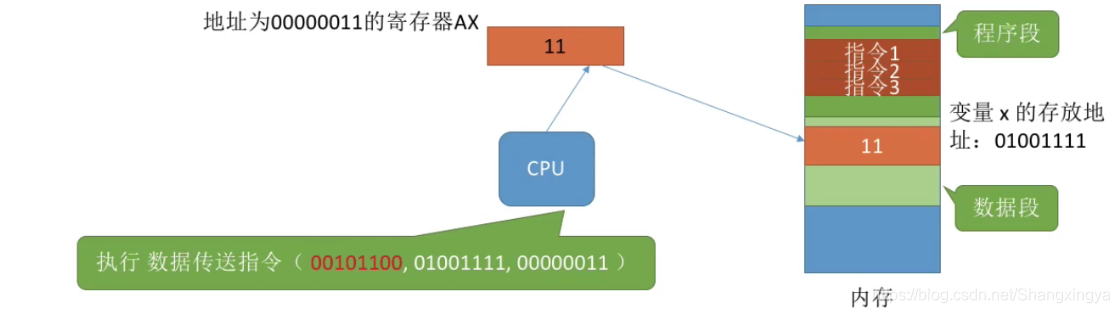
可见,我们写的代码要翻译成CPu能识别的指令。这些指令会告诉cPU应该去内存的哪个地址存/取数据,这个数据应该做什么样的处理。在这个例子中,指令中直接给出了变量x的实际存放地址(物理地址)但实际在生成机器指令的时候并不知道该进程的数据会被放到什么位置。所以编译生成的指令中一般是使用逻辑地址(相对地址)
逻辑地址VS物理地址
宿舍四个人一起出去旅行,四个人的学号尾号分别是0、1、2、3。
住酒店时酒店给你们安排了4个房号相连的房间。
四个人按学号递增次序入住房间。
比如0、1、2、3号同学分别入住了5、6、7、8号房间。
四个人的编号0、1、2、3其实是一个“相对位置”,而各自入住的房间号是一个“绝对位置”。
只要知道О号同学住的是房号为N的房间,那么M号同学的房号一定是N+M。
也就是说,只要知道各个同学的“相对位置”和“起始房号”,就一定可以算出所有同学的“绝对位置”
指令中的地址也可以采用这种思想。编译时产生的指令只关心“相对地址”,实际放入内存中时再想办法根据起始位置得到“绝对地址”
Eg:编译时只需确定变量x存放的相对地址是100(也就是说相对于进程在内存中的起始地址而言的地址)。CPU想要找到x在内存中的实际存放位置,只需要用进程的起始地址+100即可。
相对地址又称逻辑地址,绝对地址又称物理地址。
内存管理
操作系统作为系统资源的管理者,当然也需要对内存进行管理,要管些什么呢?
1.操作系统负责内存空间的分配与回收
2.操作系统需要提供某种技术从逻辑上对内存空间进行扩充
3.操作系统需要提供地址转换功能,负责程序的逻辑地址与物理地址的转换
4.操作系统需要提供内存保护功能。保证各进程在各自存储空间内运行,互不干扰
内存保护
内存保护可采取两种方法:
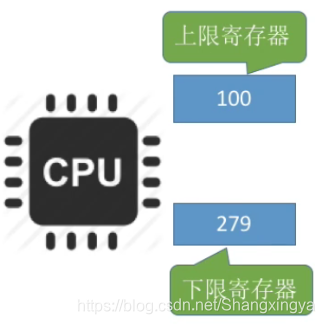
方法一:在CPu中设置一对上、下限寄存器,存放进程的上、下限地址。进程的指令要访问某个地址时,CPu检查是否越界。
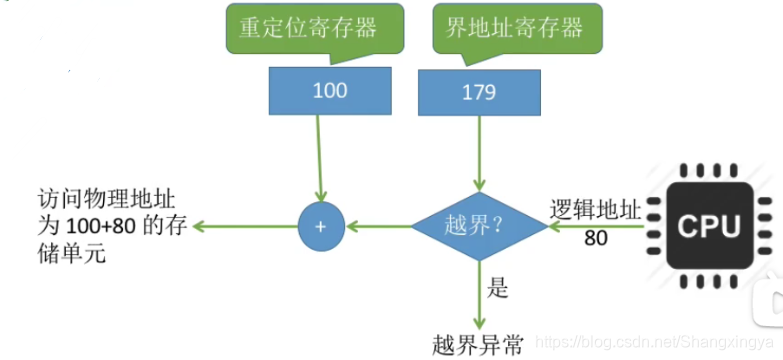
方法二:采用重定位寄存器(又称基址寄存器)和界地址寄存器(又称限长寄存器)进行越界检查。重定位寄存器中存放的是进程的起始物理地址。界地址寄存器中存放的是进程的最大逻辑地址。
内存覆盖
早期的计算机内存很小,比如IBM推出的第一台PC机最大只支持1MB大小的内存。因此经常会出现内存大小不够的情况。

后来人们引入了覆盖技术,用来解决“程序大小超过物理内存总和”的问题
覆盖技术的思想:将程序分为多个段(多个模块)。常用的段常驻内存,不常用的段在需要时调入内存。内存中分为一个“固定区”和若干个“覆盖区”。
需要常驻内存的段放在“固定区”中,调入后就不再调出(除非运行结束)
不常用的段放在“覆盖区”,需要用到时调入内存,用不到时调出内存
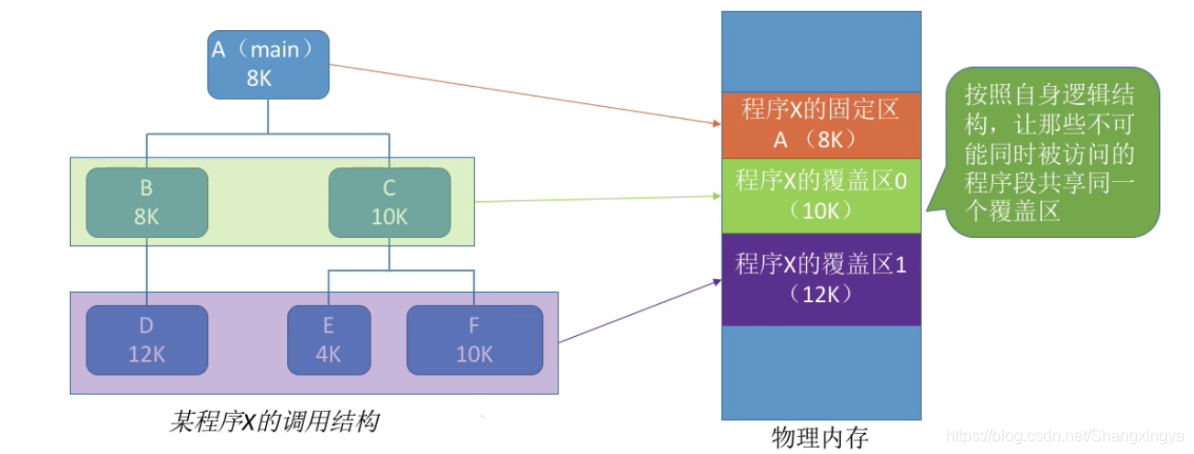
必须由程序员声明覆盖结构,操作系统完成自动覆盖。缺点:对用户不透明,增加了用户编程负担。覆盖技术只用于早期的操作系统中,现在已成为历史。
内存交换技术
交换(对换)技术的设计思想:内存空间紧张时,系统将内存中某些进程暂时换出外存,把外存中某些已具备运行条件的进程换入内存(进程在内存与磁盘间动态调度)
暂时换出外存等待的进程状态为挂起状态(挂起态,suspend)
挂起态又可以进一步细分为就绪挂起、阻塞挂起两种状态
交换(对换)技术的设计思想:内存空间紧张时,系统将内存中某些进程暂时换出外存,把外存中某些已具备运行条件的进程换入内存(进程在内存与磁盘间动态调度)
但又会有以下问题
1.应该在外存(磁盘)的什么位置保存被换出的进程?
2.什么时候应该交换?
3.应该换出哪些进程?

1.具有对换功能的操作系统中,通常把磁盘空间分为文件区和对换区两部分。
文件区主要用于存放文件,主要追求存储空间的利用率,因此对文件区空间的管理采用离散分配方式;对换区空间只占磁盘空间的小部分,被换出的进程数据就存放在对换区。由于对换的速度直接影响到系统的整体速度,因此对换区空间的管理主要追求换入换出速度,因此通常对换区采用连续分配方式。总之,对换区的I/o速度比文件区的更快。
2.交换通常在许多进程运行且内存吃紧时进行,而系统负荷降低就暂停。例如:在发现许多进程运行时经常发生缺页,就说明内存紧张,此时可以换出一些进程;如果缺页率明显下降,就可以暂停换出。
3. 可优先换出阻塞进程;可换出优先级低的进程;为了防止优先级低的进程在被调入内存后很快又被换出,有的系统还会考虑进程在内存的驻留时间…
(注意:PCB会常驻内存,不会被换出外存)
内存分配
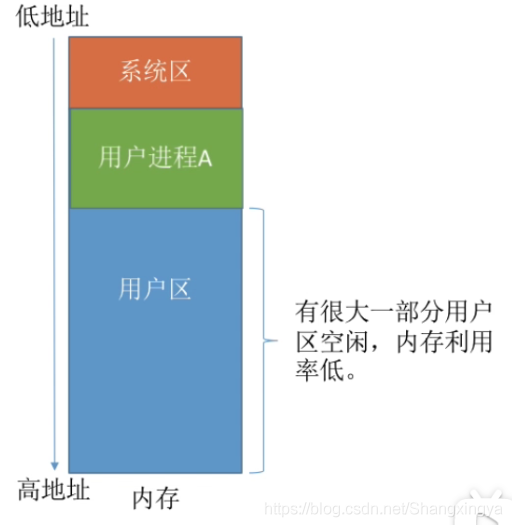
单一连续分配
在单一连续分配方式中,内存被分为系统区和用户区。系统区通常位于内存的低地址部分,用于存放操作系统相关数据;用户区用于存放用户进程相关数据。
内存中只能有一道用户程序,用户程序独占整个用户区空间。
优点:实现简单;无外部碎片;可以采用覆盖技术扩充内存;不一定需要采取内存保护(eg:早期的PC操作系统MS-DOS) 。
缺点:只能用于单用户、单任务的操作系统中;有内部碎片;存储器利用率极低。
固定分区分配
20世纪6o年代出现了支持多道程序的系统,为了能在内存中装入多道程序,且这些程序之间又不会相互干扰,于是将整个用户空间划分为若干个固定大小的分区,在每个分区中只装入一道作业,这样就形成了最早的、最简单的一种可运行多道程序的内存管理方式。
固定分区分配
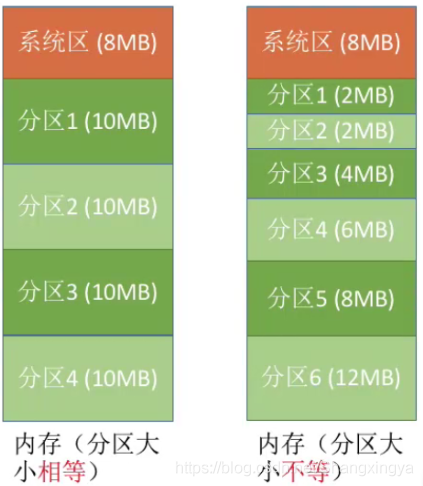
- 分区大小相等
- 分区大小不等
分区大小相等:缺乏灵活性,但是很适合用于用一台计算机控制多个相同对象的场合(比如:钢铁厂有n个相同的炼钢炉,就可把内存分为n个大小相等的区域存放n个炼钢炉控制程序)
分区大小不等:增加了灵活性,可以满足不同大小的进程需求。根据常在系统中运行的作业大小情况进行划分(比如:划分多个小分区、适量中等分区、少量大分区)
优点:实现简单,无外部碎片。
缺点: a.当用户程序太大时,可能所有的分区都不能满足需求,此时不得不采用覆盖技术来解决,但这又会降低性能;
b.会产生内部碎片,内存利用率低。
动态分区分配
动态分区分配又称为可变分区分配。这种分配方式不会预先划分内存分区,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此系统分区的大小和数目是可变的。

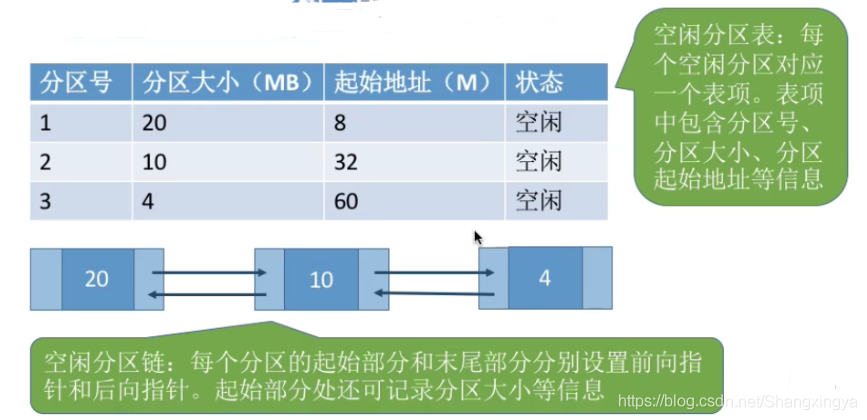
动态分区分配没有内部碎片,但是有外部碎片。
内部碎片,分配给某进程的内存区域中,如果有些部分没有用上。
外部碎片,是指内存中的某些空闲分区由于太小而难以利用。
如果内存中空闲空间的总和本来可以满足某进程的要求,但由于进程需要的是一整块连续的内存空间,因此这些“碎片”不能满足进程的需求。
可以通过紧凑(拼凑,Compaction)技术来解决外部碎片。
动态分配算法
首次适应算法
算法思想:每次都从低地址开始查找,找到第一个能满足大小的空闲分区。
如何实现:空闲分区以地址递增的次序排列。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
优点:实现简单
缺点:会有内存碎片化问题, 而且每次找到合适位置效率低
最佳适应算法
算法思想:由于动态分区分配是一种连续分配方式,为各进程分配的空间必须是连续的一整片区域。
因此为了保证当“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片的空闲区,即,优先使用更小的空闲区。
如何实现:空闲分区按容量递增次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
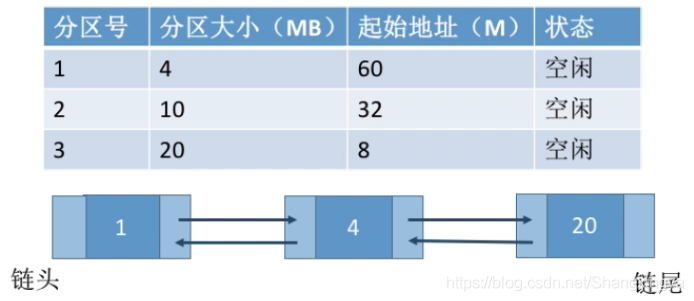
缺点:每次都选最小的分区进行分配,会留下越来越多的、很小的、难以利用的内存块。因此这种方法会产生很多的外部碎片。
最坏适应算法
又称最大适应算法(Largest Fit)
算法思想:为了解决最佳适应算法的问题――即留下太多难以利用的小碎片,可以在每次分配时优先使用最大的连续空闲区,这样分配后剩余的空闲区就不会太小,更方便使用。
如何实现:空闲分区按容量递减次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
缺点:每次都选最大的分区进行分配,虽然可以让分配后留下的空闲区更大,更可用,但是这种方式会导致较大的连续空闲区被迅速用完。如果之后有“大进程”到达,就没有内存分区可用了。
邻近适应算法
算法思想:首次适应算法每次都从链头开始查找的。这可能会导致低地址部分出现很多小的空闲分区,而每次分配查找时,都要经过这些分区,因此也增加了查找的开销。如果每次都从上次查找结束的位置开始检索,就能解决上述问题。
如何实现:空闲分区以地址递增的顺序排列(可排成一个循环链表)。每次分配内存时从上次查找结束的位置开始查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。
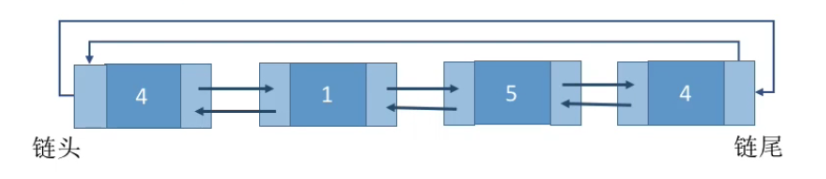
首次适应算法每次都要从头查找,每次都需要检索低地址的小分区。但是这种规则也决定了当低地址部分有更小的分区可以满足需求时,会更有可能用到低地址部分的小分区,也会更有可能把高地址部分的大分区保留下来(最佳适应算法的优点)
邻近适应算法的规则可能会导致无论低地址、高地址部分的空闲分区都有相同的概率被使用,也就导致了高地址部分的大分区更可能被使用,划分为小分区,最后导致无大分区可用(最大适应算法的缺点)综合来看,四种算法中,首次适应算法的效果反而更好