一、非连续内存分配存在的必要性
1、连续内存分配的缺点
(1)分配给一个程序的物理内存是连续的
(2)内存利用率较低
(3)有外碎片、内碎片的问题
2、非连续分配的优点
(1)一个程序的物理地址空间是非连续的
(2)更好的内存利用和管理
(3)允许共享代码和数据(共享库等)
(4)支持动态加载和动态链接
* 非连续分配的主要问题在于管理开销本身
二、非连续物理内存的管理方法
物理内存管理需要考虑这样一个问题:如何建立虚拟地址和物理地址之间的转换。这个问题有两种解决方案——软件(开销大)和硬件。因此需要重点考虑如何利用已有的硬件协助非连续物理内存管理。而分段和分页是主要的硬件方案。
1、分段(Segmentation)
逻辑地址中有不同的堆栈段,如果能将这些堆栈段更好地区别、隔离出来,有助于我们进行更好的管理。
分段的目的:更好的分离和共享。
关注两个问题:
1.1 程序的分段地址空间
当1234从逻辑地址映射到物理地址空间,大小和位置都变得不同。
分段的逻辑视图:
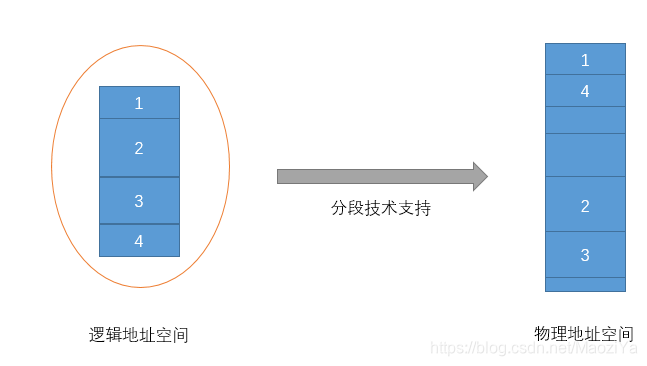
1.2 分段寻址方案
段访问机制:程序访问内存地址需要一个二维的二元组(s,addr)
【s_段号;addr_段内偏移】
硬件实现方案:CPU调用逻辑地址,根据段表查找出物理地址的起始段号和段长,经过MMU检测段号和段长是否合法,不合法则显示内存异常,合法则正确寻址。
- 操作系统提前建立好段表
2、分页(Paging)
现在的CPU大多采用分页的机制。
在分段机制中段的大小可变,但是分页机制中页的大小是固定的,目的是便于硬件对其做相应的实现。
2.1 分页地址空间
划分物理内存至固定大小的帧(Frame,物理页):大小是2的幂
划分逻辑地址空间至相同大小的页(Page,逻辑页):大小是2 的幂
(1)帧(Frame)
一个内存物理地址是一个二元组(f,o)
【f_帧号(F位,F指地址空间中减去o占的位数剩下的位数。共有2F 个帧);o_帧内偏移(S位,S指o占的位数,即页帧的大小。每帧有2S字节)】
| 物理地址=2S * f + o |
|---|
(2)页(Page)
一个逻辑地址是一个二元组(p,o)
【p_页号(P位,2P个页);o_页内偏移(S位,每页有2S字节)】
| 虚拟地址=2S * p + o |
|---|
2.2 页寻址方案:转换逻辑地址为物理地址(pages to frames)
工具:
- 页表
- MMU/TLB
页寻址机制:CPU调用逻辑地址,根据页表查找出物理地址的帧号。
- 与分段机制不同的是,分页机制的页内偏移大小是固定的,使得能以更简洁的方式在硬件上实现,不需要考虑分段机制中不同段大小不一定的问题。
- 逻辑地址空间的页大小和物理地址空间的帧大小不一致,一般前者要大于后者。虚拟地址解决空间大小不匹配问题。
- 逻辑地址空间中连续的页映射到物理地址空间时可能变得不连续,有助于减少碎片。
- 操作系统提前建立好页表
2.3 页表(Page Table)
2.3.1 页表概览
页表:以页号为索引存储的帧号。(Flags | Frame num)
- 物理地址和逻辑地址的偏移大小相等,帧号不一定相等。
- 页表保存了逻辑地址–物理地址之间的映射关系。
- 页表中存储一系列的属性,存在判断物理空间是否存在的属性(0/1)。
分页机制的性能问题
(1)访问一个内存单元需要2次内存访问
- 一次用于获取页表项
- 一次用于访问数据
(2)页表可能非常大
例如:64位机器如果每页1024字节,那么一个页表的大小是多少?
- 254
–>逻辑地址空间很大可能导致页表很大
解决方案
- 缓存(Caching):最常用的内存放到离CPU较近的地方(如TLB)
- 间接(Indirection)访问:将大空间拆分成小空间(如多层次页表)
2.3.2 MMU/TLB(translation look-aside buffer)(快表)
结构:Key | Value
缓存近期访问的页帧转换表项。
- TLB使用associative memory(关联内存)实现
- 如果TLB命中,物理页号可以很快被获取
- 如果TLB未命中,对应的表项被更新到TLB中
能够避免一次对页表的访问,使寻址开销得到降低。
2.3.3 二级 / 多级页表
(1)二级页表
将页表划分为一级页表p1(存储page table,即二级页表的起始地址)、二级页表p2(存储各个page table对应的 【Flags | Frame num】)。
以二级页表的方式进行寻址,显然多了一次页表访问,开销变大。但是以此种方式进行寻址,一些没有必要访问的页表项不占用内存。
(2)多级页表
通过把页号分为k部分,来实现多级间接页表,即建立页表“树”。
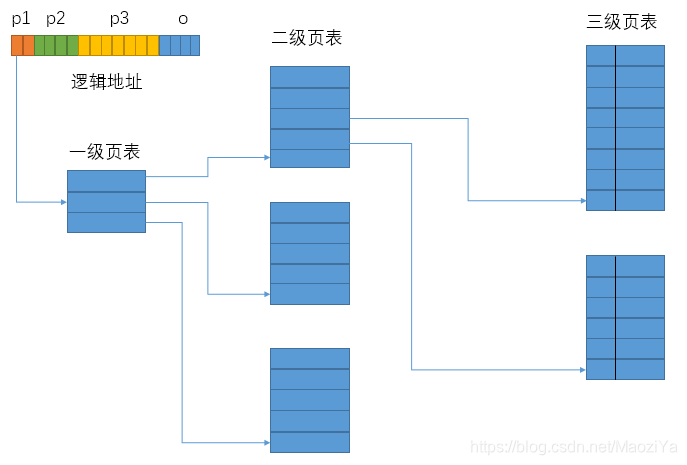
总的来说,多级页表是一种以时间为代价来节省空间的思想;TLB是以空间为代价节省时间的思想。二者相辅相成、互为补充。
2.3.4 反向页表(inverted page table)
思想:令页表大小不受限于逻辑地址空间大小,即页表与逻辑地址空间没有直接的对应关系,而是与物理地址空间建立一定关系,也即利用帧号。
基于页寄存器(Page Registers)的方案
Page Registers 结构:【帧号f | 页号P】
(1)优势
- 转换表大小相对于物理内存来说很小
- 转换表的大小与逻辑地址空间的大小无关
(2)弊端
- 需要的信息对调,即更具帧号可找到页号
- 如何转换回来?即根据页号找到帧号
- 在需要的反向页表中搜索需要的页号
基于关联内存(associative memory)的方案
类似于TLB。能够并行地查找页号对应的页帧号。
两种方案总结:反向页表设计方面可以做得很好,但成本、代价大,导致无法做得特别大,而且大的存储会拉缓查找速度。这些问题导致反向页表不够实用。
在反向页表中搜索一个页对应的帧号的步骤
- 如果帧数较少,页寄存器可以被放置在关联内存中
- 在关联内存中查找逻辑页号
- 成功:帧号被提取
- 失败:页错误异常(page fault)
- 限制因素:
- 大量的关联内存非常昂贵:难以在单个时钟周期内完成;耗电
优化方案:基于哈希(hash)查找的方案
- 借助哈希表:输入page num,输出frame num
- 需要硬件帮助,支持高速的哈希表计算
- 需要构建高效的函数
- 为了提高效率、解决冲突,需要在哈希表中添加一个运行参数PID(当前运行ID),以此可以很好地设计出一个比较简洁的hash函数,算出对应的帧号。
(1)优势
- 不受制于逻辑地址空间大小限制,容量可以做得很小
- 不受进程数目影响,只需要一个page table
(2)弊端
- 出现hash碰撞,即对于一个input,出现多个output,这时候就需要进行进一步分析。程序的ID可以缓解这一冲突。
- 进行hash计算的时候也需要到内存中的反向列表中取数,开销仍然比较大,因此仍然需要一种类似于TLB的机制缓存。