深度学习论文精读(7):MTCNN
论文地址:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
译文地址:https://zhuanlan.zhihu.com/p/37884254
参考博文1:https://zhuanlan.zhihu.com/p/38520597
官方地址:https://kpzhang93.github.io/MTCNN_face_detection_alignment/
1 总体介绍
- 认为人脸检测和人脸对齐之间是有内在联系的,因此提出了一种同时训练两个任务的结构。
- 提出了一种基于深度学习的级联结构,用于以下两种人脸识别任务。
- 1.人脸检测(face detection)
- 2.人脸对齐(face alignment)
- 提出了一种新的hard sample选取策略: online hard sample mining strategy,有效提高训练精度。
- 在各类数据库中达到state-of-the-art。同时延迟较低。
2 网络总体结构
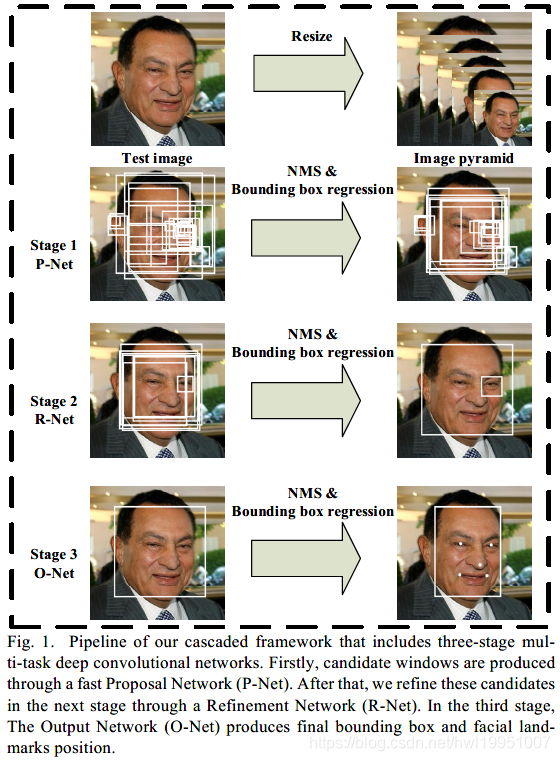
- 如下图所示,MTCNN的结构共分为三层,分别为:
- P-Net(Proposal Network),用于生成预选框
- R-Net(Refinement Network),用于精炼预选框
- O-Net(Output Network),用于输出人脸,以及脸部标志点
-
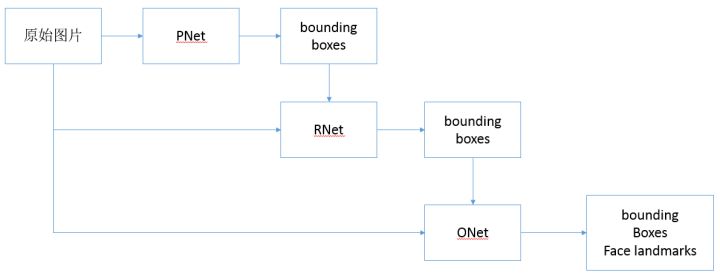
更直观的输入输出流程如下:(图片来自这篇文章)
-
首先将原始图片resize成一系列大小的图片金字塔,用于不同层级的网络输入。
-
P-Net的输入是resize成12*12的原始图片。输出是一系列的bounding boxes。
-
R-Net的输入是resize成24*24的原始图片以及P-Net得到的bounding boxes。输出是经过精炼过后的bounding boxes。
-
O-Net输入的是resize成48*48的原始图片以及R-Net精炼过后的的bounding boxes。输出是最终得到的bounding box,以及其中的五个facial landmarks。(左右眼,鼻尖,左右嘴角)
-
其中,上述步骤均以NMS(None-Maximum oression)进行重复bounding boxes的精简。
-
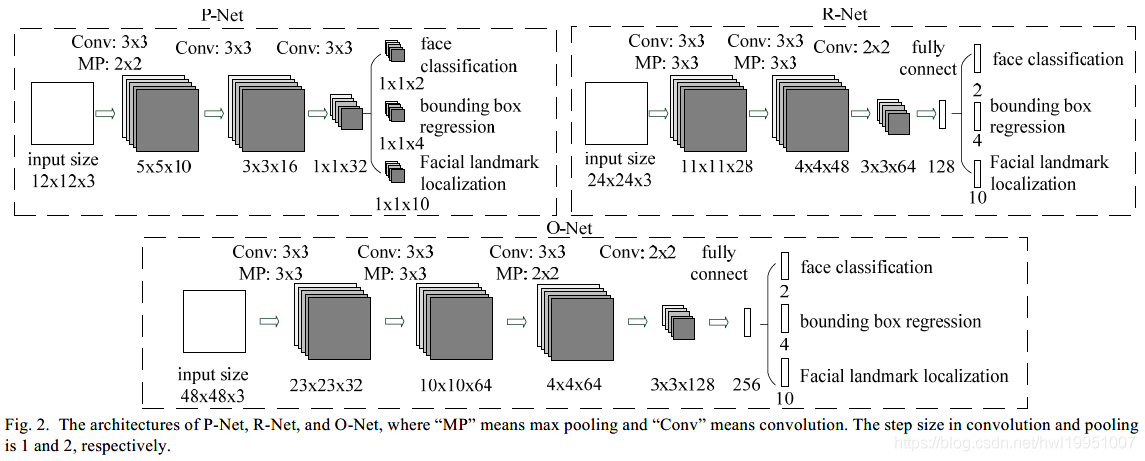
- P-Net,R-Net,O-Net的具体参数。
2.1 损失函数介绍
-
MTCNN共包含三个任务,分别为:
- Face classification(人脸分类,用于判断边框内是否为人脸)
- Bounding box regression(边框回归,用于标定人脸边框的范围)
- Facial landmark localization(人脸标志点定位,用于定位人脸上的特征部位)
-
其损失函数分别为:
-
Face classification,使用交叉熵损失:
,其中 为label, 为网络得出该边框是否为人脸的概率。
-
Bounding box regression,使用欧氏距离损失:
,其中 为网络预测的边框信息, 为边框标签。 内包括边框的左顶点,以及边框的宽和高。 。
-
Facial landmark localization,使用欧氏距离损失:
,其中 为网络预测的特征点信息, 为特征点真值。 包括左右眼,鼻尖,以及左右嘴角的位置。 。
-
2.2 多任务训练
-
MTCNN的框架里,每一层级的网络结构都需要完成的上述的三个任务,但在每层网络中,各个任务的重要性又不尽相同,因此,文中使用超参数来控制不同网络内,不同任务的损失权重。如下:
-
其中, 为样本总数, 为损失类别, 为用于控制损失权重的超参数, 用于描述样本类型,下面会提到。
-
的具体设置如下,用以调节在不同网络内不同任务的权重,以得到更优秀的结果。
- P-Net 和R-Net:
- O-Net:
2.3 在线困难样本挖掘
-
作用:构建训练数据的方法。
-
流程:
-
- 在每个mini-batch中,计算所有loss,并降序排序。
- 获取钱获取前70%的sample进行梯度下降训练。
2.3 训练数据构建
-
根据样本的好坏,以及作用的任务分为以下四类:
-
- positives:与 ground truth 的IOU高于阈值。(文中使用0.65)
- negatives:与 ground truth 的IOU低于阈值。(文中使用0.3)
- part faces:与 ground truth 的IOU处于两个阈值之间。(文中使用0.4以及0.65)
- landmark faces:拥有landmark的标签。(五个面部关键点)
-
不同任务使用不同的训练数据,并以 来规定样本能否参加训练,能参加的则置1,否则置0。
-
- Face classification使用 positives & negatives。
- Bounding box regression预测使用 potitives & part faces。
- Facial landmark localization预测使用 landmark faces。
4 其他
- MTCNN用于人脸识别的话,将会是用于裁剪人脸,获得边框。之后再输入到传统CNN中,获取特征向量,再通过特征向量进行距离的判断,以一个阈值来划分是否为同一张人脸。
单词整理:
- joint 连接,关节
- inherent 固有的,与生俱来的
- coarse 粗糙的
- auxiliary 辅助的,附加的
- desirable 令人满意的
- candidate 候选人
- refine 精炼
- notably 显著的
- pyraimd 金字塔
- estimate 估计,判断
- calibrate 矫正
- diversity 多样性,差异
- discriminate 歧视,区别
- leverage 杠杆作用
- obtain 获得