- 《SphereFace: Deep Hypersphere Embedding for Face Recognition》
2017,Weiyang Liu et al. A-softmax loss(angular softmax loss)
源码:https://github.com/wy1iu/sphereface
参考:https://blog.csdn.net/qq_14845119/article/details/76154976
https://www.cnblogs.com/heguanyou/p/7503025.html

文章主要提出了归一化权值(normalize weights and zero biases) 和角度间距(angular margin),基于这2个点,对传统的softmax进行了改进,从而实现了,最大类内距离小于最小类间距离的识别标准。
原始的softmax的loss损失是一个交叉熵损失,
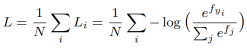
其中,
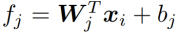
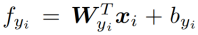
将其代入第一个式子,得出了损失函数如下,
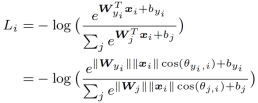
原始softmax loss的特征分布结果:
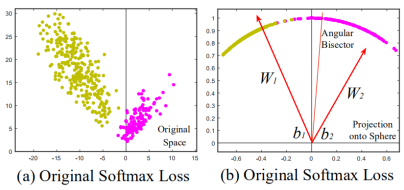
进行归一化操作,将其都映射到一个单位球面上,令||W||=1,b=0,并且引入夹角,得出Modified Softmax Loss公式如下,
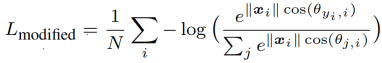
Modified Softmax Loss的特征分布结果:
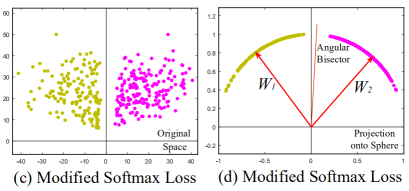
在此基础上,再引入angular margin,用m表示,最终产生A-softmax的loss公式
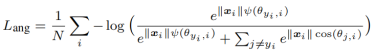
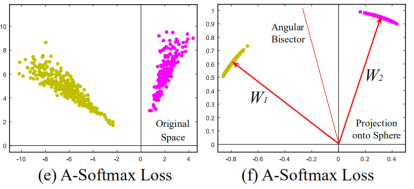
A-softmax loss的特征分布结果:
其中:
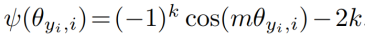
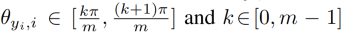
L-Softmax和SphereFace都采用乘性margin使不同类别更加分离,特征相似度都采用cos距离。需要注意这两个loss直接训练很难收敛,实际训练中都用到了优化策略:
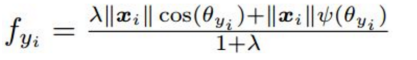
从Softmax逐渐过渡到L-Softmax或A-Softmax。
其中,
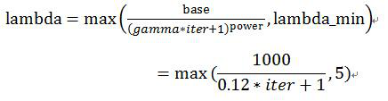
与L-Softmax的区别:
A-Softmax与L-Softmax的最大区别在于A-Softmax的权重归一化了,而L-Softmax则没有。A-Softmax权重的归一化导致特征上的点映射到单位超球面上,而L-Softmax则不没有这个限制,这个特性使得两者在几何的解释上是不一样的。如果在训练时两个类别的特征输入在同一个区域时,如下图1所示。A-Softmax只能从角度上分度这两个类别,也就是说它仅从方向上区分类,分类的结果如图2所示;而L-Softmax,不仅可以从角度上区别两个类,还能从权重的模(长度)上区别这两个类,分类的结果如图3所示。在数据集合大小固定的条件下,L-Softmax能有两个方法分类,训练可能没有使得它在角度与长度方向都分离,导致它的精确可能不如A-Softmax。

图1:类别1与类别2映射到特征空间发生了区域的重叠

图2:A-Softmax分类可能的结果

图3:L-Softmax分类可能的结果
总结:
SphereFace是L-Softmax的改进,归一化了权值W,让训练更加集中在优化深度特征映射和特征向量角度上,降低样本数量不均衡问题。