- 《NormFace: L2 Hypersphere Embedding for Face Verification》
2017,Feng Wang et al. NormFace
源码:https://github.com/happynear/NormFace
引言:
首先论文分析存在的问题:在优化人脸识别任务时,softmax本身优化的是没有归一化的内积结果,但是最后在预测的时候使用的一般是cosine距离或者欧式距离,这会导致优化目标和最终的距离度量其实并不一致。
在特征比较阶段,通常使用的都是特征的余弦距离:
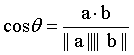
而余弦距离等价于L2归一化后的内积,也等价L2归一化后的欧式距离(欧式距离表示超球面上的弦长,两个向量之间的夹角越大,弦长也越大)

这也就是说在训练时使用的距离度量与在测试时使用的度量是不一样的。
测试时是否需要归一化?
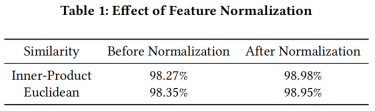
为了说明这个问题,作者特意做了试验,说明进行人脸验证时使用归一化后的内积或者欧式距离效果明显会优于直接计算两个特征向量的内积或者欧式距离,实验的结果如下:
为什么会是特征会呈辐射状分布
Softmax实际上是一种(Soft)软的max(最大化)操作,考虑Softmax的概率
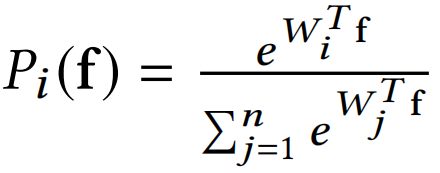
假设是一个十个分类问题,那么每个类都会对应一个权值向量
,某个特征f会被分为哪一类,取决f和哪一个权值向量的内积最大。
对于一个训练好的网络,权值向量是固定的,因此f和W的内积只取决与f与W的夹角。
也就是说,靠近
的向量会被归为第一类,靠近
的向量会归为第二类,以此类推。网络在训练过程中,为了使得各个分类更明显,会让各个权值向量W逐渐分散开,相互之间有一定的角度,而靠近某一权值向量的特征就会被归为相应的类别,因此特征最终会呈辐射状分布。
算法原理
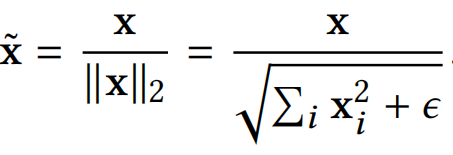
首先,说一下为什么需要正则化,以及为什么不要偏差bias:softmax loss倾向于学习到一个radial分布的特征,其原因在于特征的scale越大就会使得softmax的loss越小;softmax之前的fc有bias的情况下会使得有些类别在角度上没有区分性但是通过bias可以区分,在这种情况下如果对feature做normalize,会使得中间的那个小类别的feature变成一个单位球形并与其他的feature重叠在一起,所以在feature normalize的时候是不能加bias的。

接下来,论文解决了正则化后网络不收敛的问题:其原因在于normalize之后softmax loss的输入处于一个[-1,1]的分布,其最小值被抑制、是有下限的,即使样本被完美分类,即对应类别的输出为1,其他的为-1,那么这个概率Py还是一个比较小的值,而softmax loss的梯度为1-Py,这使得容易的样本梯度也很大。相比于原来的softmax loss,其输入的scale可以很大使得概率Py是个接近于1的数使得难易样本的梯度差别比较明显。

最后,论文提出解决办法,也就显而易见了,就是在normalize之后加个scale,让这个差距再拉大,所以最终normalize之后的softmax loss如下,其中w和f都是归一化的。
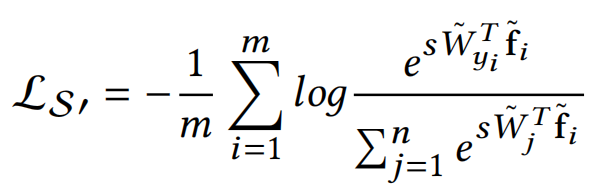
同样加了尺度因子s,但这里推荐用自动学习的方法。
实验结果

[36] Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao. 2016. A Discriminative
Feature Learning Approach for Deep Face Recognition. In European Conference
on Computer Vision. Springer, 499–515.
总结:
归一化后的softmax, contrastive 和center loss都用不同程度的提升,0.49M的CASIA-WebFace训练集28层ResNet,归一化前后,softmax从98.28%提升到99.16%,center loss从99.03%提升到了99.17%。
参考:
https://blog.csdn.net/u010579901/article/details/81030504
https://blog.csdn.net/fire_light_/article/details/79601378
https://zhuanlan.zhihu.com/p/34436551