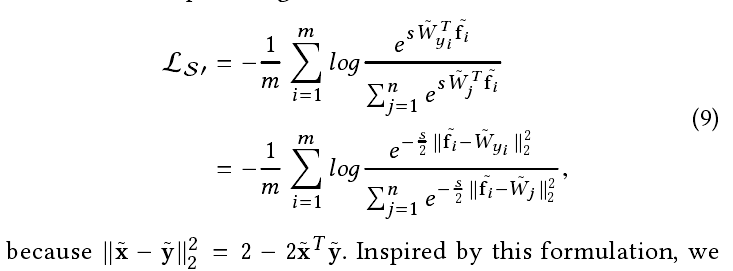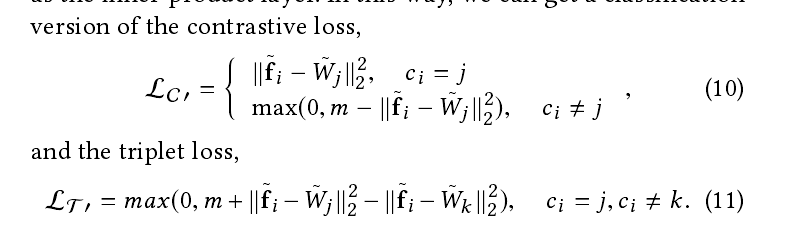转自:http://blog.csdn.net/sinat_27614125/article/details/71104183?locationNum=16&fps=1 略删改。
https://github.com/happynear/NormFace
本文的思想很简单,就是通过验证研究正则化的本质,来设计网络结构。
提取问题:
1,为什么用classificatin loss,尤其是softmax loss训练cnn 特征的时候,特征正则化这么有效果?
2,为什么用softmax loss 来直接优化余弦相似度会导致 网络不能收敛?
3,怎么优化余弦相似度?
3.1 L2 正则化层。
现象:下图就是LeNET的特征减少到2个点,然后选择10000个2维的特征点投影到平面。

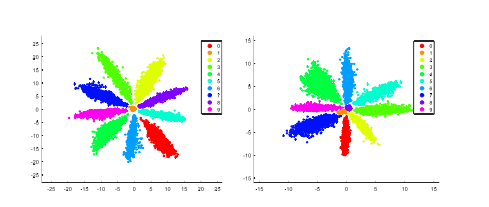
problem: 从左边的图中可以看见,按照欧式距离的度量方法来计算,那么f1和f2的欧式距离是小于f2和f3的欧式距离,请注意左图中心位置f1,f2,右上侧f3,naive idea,f1和f2的相似度远大于f2和f3
的相似度,但是事实上不是如此。所以能不换个度量方式呢?比如余弦的角度作为一种不错的度量方式,也是很多先前的工作采用的度量方式。这样就存在一个gap,也就说在test的时候采用正则化的方式(余弦公式),但是train 的时候就没有采用。
identity:上面是直观的说明这个问题,那么从数学的角度解释上面现象的本质。1:softmax是本质上就是在做最大化似然函数的操作(文中另有公式证明在特征正确分类的情况下,该特征的权值增大将不会影响,分类结果。,因此softnax 的特征分布就是radial 形状的),但是这个属性我们并不需要,因此就需要normalization,来减少radial形状的影响;2:考虑bias term 的影响,并且考虑该是否增加。比较一下下面两张图,观察做了正则化前后的特征分布的变化,很显然,在做了正则化之后,特征点就分布到整个空间。
solution:现在需要做的事情就是train和test的时候给设计特征的正则化的操作。所以模型设计一个正规化层。定义就如下:
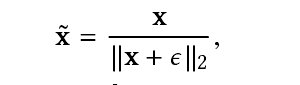
其中e的是一个正的数值主要目的防止被除数为0,其中x既可以代表f,也可以代表W的一组参数。在反向传播的过程中,关于x的梯度
如下:
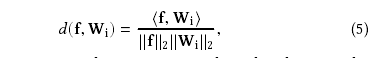
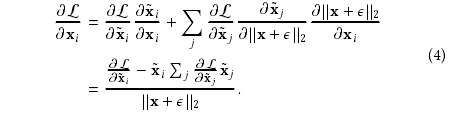
推到就省略了。下次补上。

我个人觉得上面文中有些推导存在逻辑上面问题。
3.3 模型正则化后,模型不能收敛的问题。
problem:通过上面知道normalization layer,我们将直接优化余弦相似度:
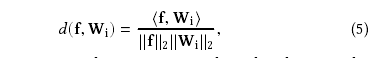
但是作者实验后发现,在经过几千部的迭代之后,
模型的loss 减少的很小,而且收敛到一个很大的数值。
wy:
最主要的原因是经过正则化之后,d的数值范围是在[-1,1]之间,然而一般情况下(就是不做正则化),他这个数值停留在[-20,20]或者[-80,80]的取值范围内部。这个小范围的问题将会组织概率P接近1,举个极端的例子,的数值很小,比如当n=10的时候,P=0.45;当n=1000的时候,p=0.007,即使其他的样本在他的对立面。既然softmax loss 针对the groud truth 标签的梯度是 1- Py,模型将经常尝试给大的梯度给完好分类的样本,但是那些比较不容易分类的样本可能不能得到大的梯度。(这又是为什么呢?)
定理:

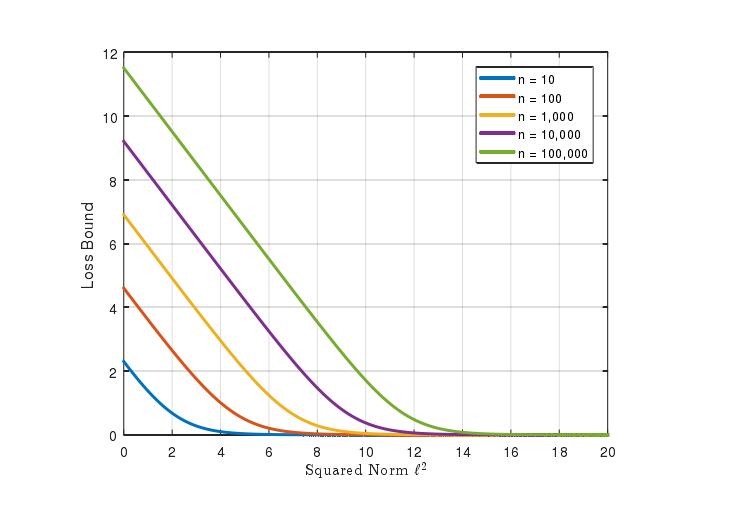
假设数据集的每一类都是拥有相同的样本,而且所有样本都是正确分类。如果我们能正则化特征和权值,softmax loss 将会有一个比更加小的bound,如上。
这个bound 预示了一个问题,如果我仅仅正规化特征和权值到1,softnax loss 在训练数据也将会陷入比较大的数值。举个真实的例子,我们在casia-webface dataset 上面训练模型。loss 将会从9.27降到8.5,但是loss of bound 是8.27,这个就非常接近真实的数值。也预示着bound 是很紧的。
下图给出解决办法,就是将特征和权值归一化到l,而不是1.

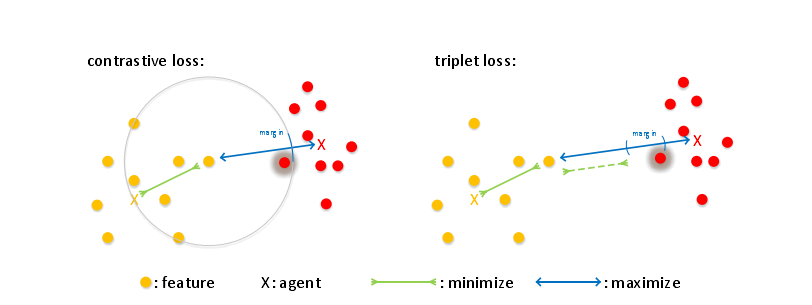
4,重新设计度量学习(注意,这里实际上是将下面两种损失函数的欧式距离评价,优化成归一化特征和权值的方式,使其在分类任务中也可以做识别任务)
补充:constrastice loss
Contrastive Loss (对比损失)
在caffe的孪生神经网络(siamese network)中,其采用的损失函数是contrastive loss,这种损失函数可以有效的处理孪生神经网络中的paired data的关系。contrastive loss的表达式如下:
L=12N∑n=1Nyd2+(1−y)max(margin−d,0)2
其中
d=||an−bn||2
,代表两个样本特征的欧氏距离,y为两个样本是否匹配的标签,y=1代表两个样本相似或者匹配,y=0则代表不匹配,margin为设定的阈值。
这种损失函数最初来源于Yann LeCun的Dimensionality Reduction by Learning an Invariant Mapping,主要是用在降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。
观察上述的contrastive loss的表达式可以发现,这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当y=1(即样本相似)时,损失函数只剩下∑yd2,即原本相似的样本,如果在特征空间的欧式距离较大,则说明当前的模型不好,因此加大损失。而当y=0时(即样本不相似)时,损失函数为∑(1−y)max(margin−d,0)2,即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。
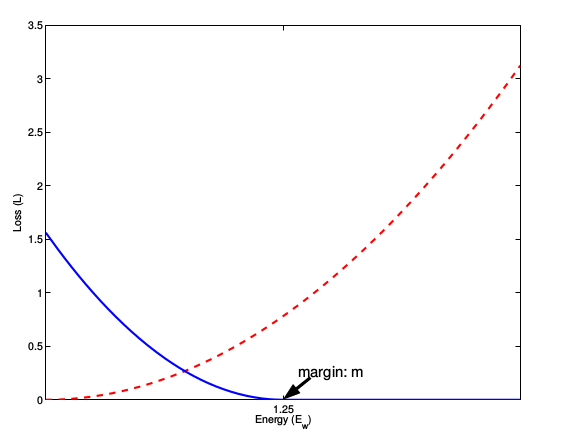
这张图表示的就是损失函数值与样本特征的欧式距离之间的关系,其中红色虚线表示的是相似样本的损失值,蓝色实线表示的不相似样本的损失值。
triplet loss 请参考FaceNet论文。
下图时经过归一化